




Ulrich_W
Members
-
Joined
-
Last visited
-
It's really weird and I stopped searching for the problem, as it looks like it can damage the Hardware! When I was swapping the two nvme drives, one of them was already bricked or gone. No problem I got a warranty replacement. But I guess this explains why the problem at that time was following the drive. So after new installation of unraid on the stick the problem came back again. But I guess this was due to the config files for apps and vms that still existed on my drives. I took the original motherboard on which the problem started. I deleted the nvme drives, added new unraid array drives and zfs pool drives without any changes again. After that everything worked fine without any problems since. Of course I am still busy restoring my data from backup and configuring vms and dockers manually again. But it works and at least for me it was the best solution. Best regards Ulrich
-
Ok, now I guess I know the problem. Of course it's my fault again as every time ...! There must be any old config information that unraid was using in the latest update to 7.1.4. When removing my Gaming pool and rebooting two times to check if the drives come back again. I got an error message from unraid. Disk Location: nvme3n1 31. Okt., 19:03 Alert - Device failureSamsung SSD 980 PRO 500GB S5GYNF0W122040R But this disk doesn't exit for months, actually for years anymore on this unraid installation. Probably my fault, as I am using similar names for the pools? I also had similar problems with the upper and lower case of shares in the last updates that don't exist anymore, this problems always came back, but were easy to fix. I guess best way is to have a completly new unraid installation. So, what is the best way to fully reinstall unraid on an existing stick with an existing licence? diagnostics-20251031-1945.zip
-
Well, it sounds plausible, but it is nearly impossible that the Samsung NVME drive causes the problem. This is why I first thought it is a hardware problem and I changed nearly every single component now. Dont't get me wrong Jorge, I fully trust you, you are one of the experts and I am grateful for any help, thank you very much. But, (just thinking, no accusation) the original problem started with the SATA drives in the unraid pool first parity 1, then parity 1 and disk 1, then parity 2 and disk 2, and so on ... Then ZFS pool started to fail, mainly disk 2 and 5, and so on ... now disk 6 In the meanwhile I exchanged PCIE SATA controller, power supply, motherboard two times, CPU and exactly this Samsung NVME SSD990 4TB that fails now and it is brand new. Before I had in 6x Seagate FireCuda 530 2TB that also failed with the latest motherboard, in the application and gaming NVME pool. I also know the Fractal Define 7 case I use has a problem with the front 5V USB supply in the boot process, but front USBs aren't plugged in anymore. I also exchanged temporarily the graphics card. And before, ... everything worked without any issue for months. Now again, after reboot, Gaming 2 NVME doesn't exist anymore in unraid, in the bios every single drive exists. But now I can choose the exchanged SATA ZFS drive 6 for to add to the pool. This is exactly when it starts again, I destroy the Gaming raid to single. Then I reboot, I bet NVME Gaming 2 comes back. I remove the pool, add the two Gaming NVMEs in a new pool again with raid 1. Then everything is fine, latest when I reboot and it starts over again ... The only time I thought it becomes better was, when I deleted the <hostdev> part from the VM script. Suddenly after this all drives came back without issues?! Didn't really get why? Latest diag file attached. diagnostics-20251031-1707.zip
-
I swapped now the two devices. diagnostics-20251031-1458.zip
-
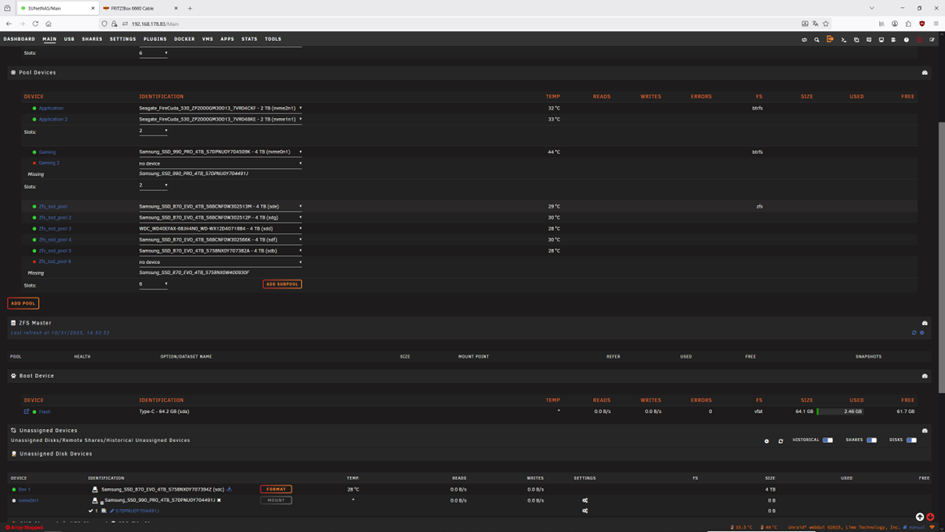
I change drive 5 that showed the fiist error. Resilvering was finished, pool was still degraded. then changed drive 6 that seem not to be readable. New, or actually same problems with nvme Gaming 2. Diag file is attached. diagnostics-20251031-0643.zip
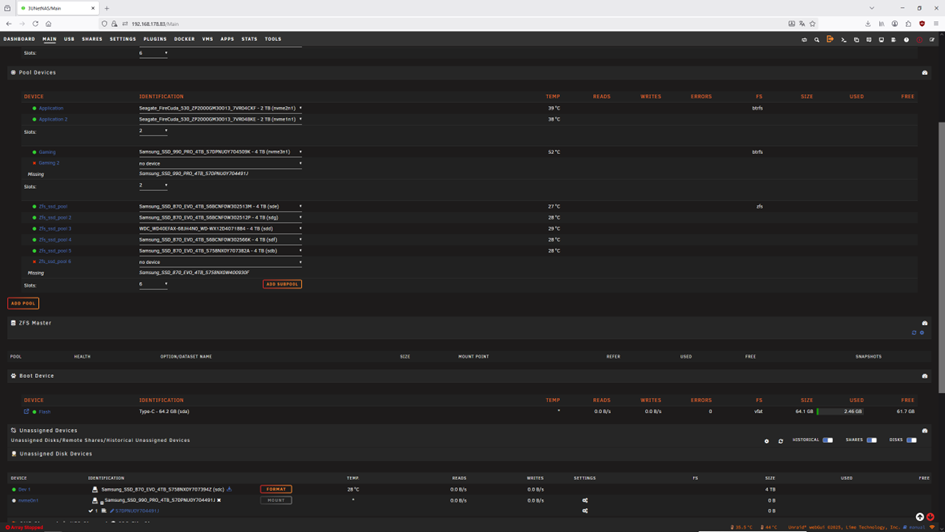
-
ok, I started replacing the failed drive, that will take a while.
-
Just the scrub results or any further UUID: 42ffca51-c710-487d-baaf-1b778e48eb43 Scrub started: Wed Oct 29 20:05:00 2025 Status: finished Duration: 0:02:10 Total to scrub: 708.86GiB Rate: 5.45GiB/s Error summary: verify=612 Corrected: 612 Uncorrectable: 0 Unverified: 0
-
Hello Jorge, I couldn't wait 🙂 Diag file is already posted.
-
I had some trouble during reboot but different than the other times all drives came back in good condition. Attached the diag. diagnostics-20251029-1926.zip
-
Actually the script shows: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x08' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x45' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x06' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x45' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x07' slot='0x00' function='0x0'/> </hostdev>guess I shall delete all of it, correct?
-
Not any VM or Docker was running anymore when this happend the last 10 times. Actually I only tryed to start the VM "001b Windows 10 Gaming", but it didn't work as the iso file was missing last time. Before I was regularly using VM "001b Windows 10 Gaming" and VM "101 Windows 10 Programming NVDIA" in parallel with two passed though graphics cards. Only one graphics card is passed through now, but this configuration was running months without any changes or trouble till the frist drive failed. I didnt work on the configuration of VMs or Dockers till 10 days before when I updated some dockers, apps and unraid as usually and several times before. As I remember only this first VM was up when it happend the first time. But there was no connection between the first failed drive and the VM. The VM was running without any issues the first five times when any drives failed. I am just summarizing what I remember ....
-
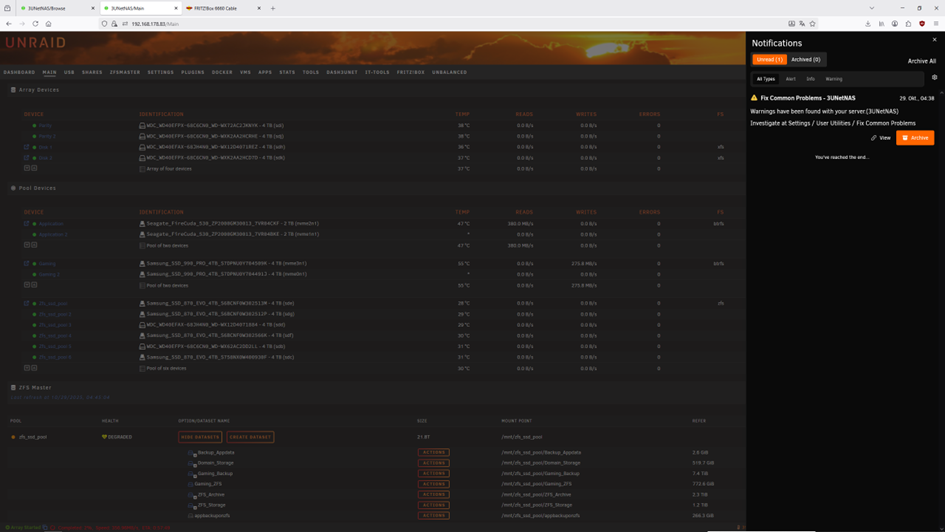
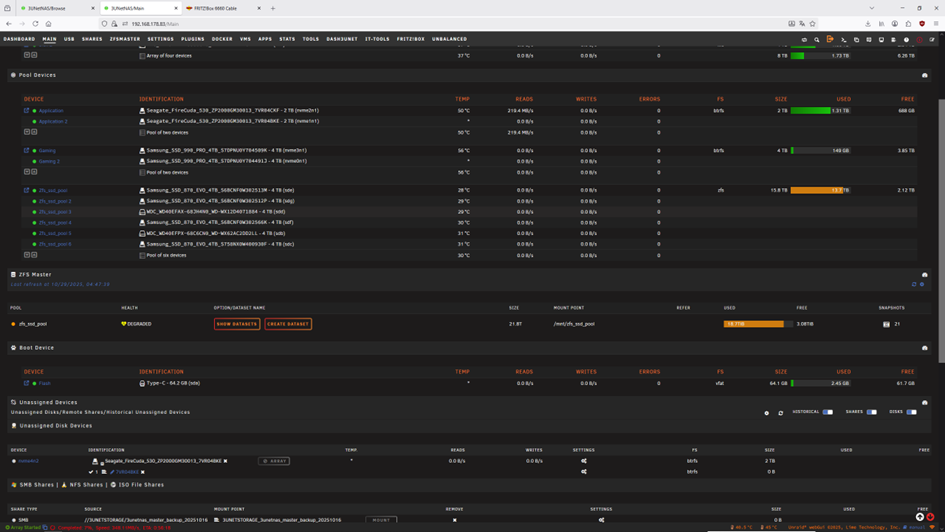
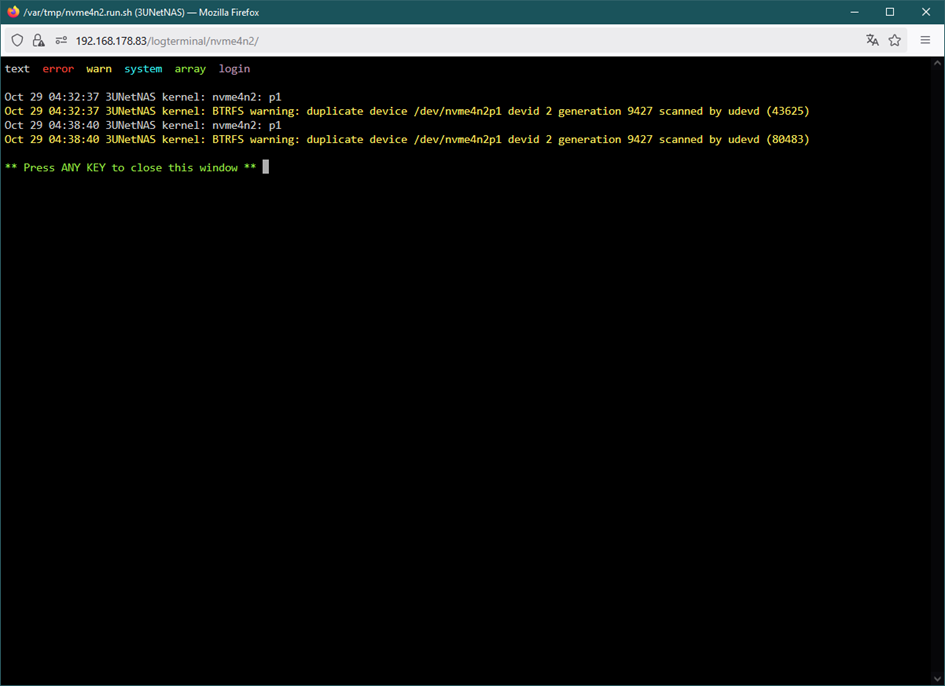
Ok, here we are again ☹️ After everything was fine I got a notification. Then after cold reboot. First drive starts to fail, no temperature information anymore. Second drive the same. one drive is shown as unassigned. With folloowing drive log. Attached the latest log files.diagnostics-20251029-0436.zipdiagnostics-20251029-0442.zipdiagnostics-20251029-0506.zip
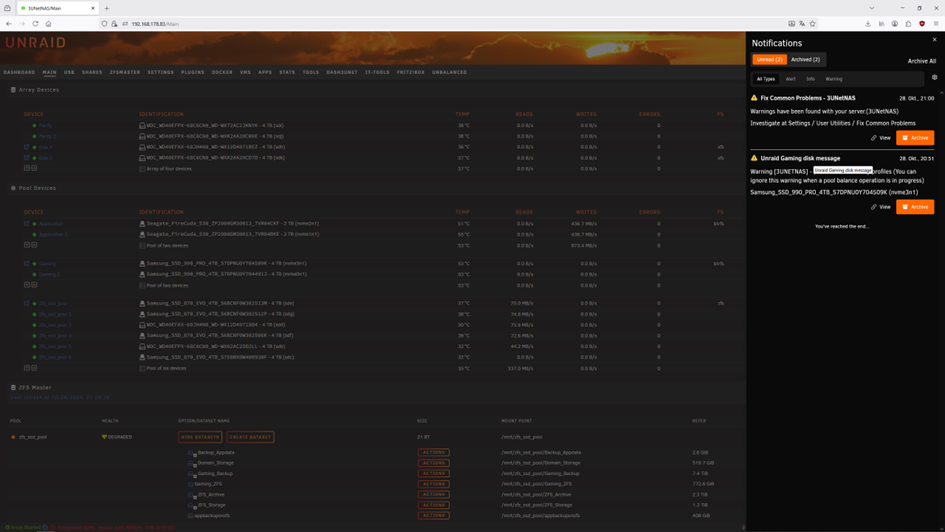
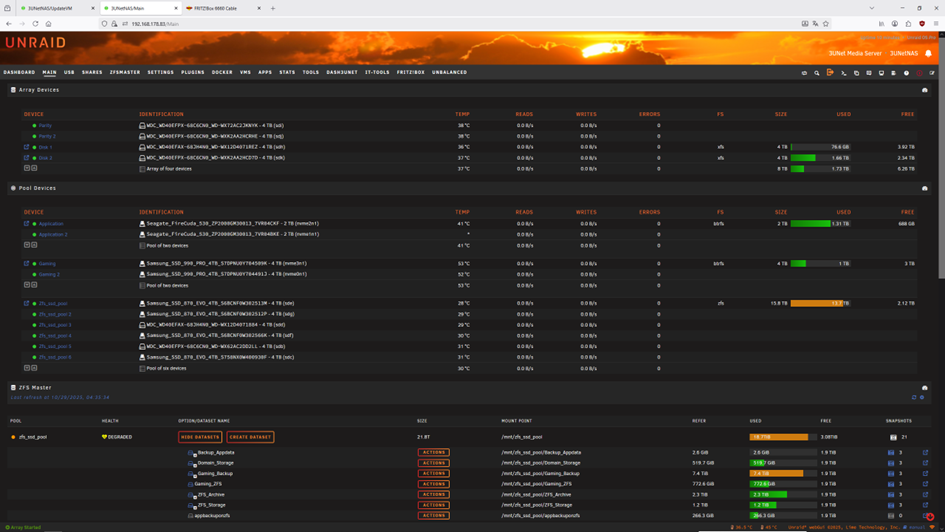
-
Ok, thanks for your help so far.
-
Power cycle doesn't help either, I tried a dozen times. It seems drives which failed need to be formated externally to bring them back in unraid. But then they work fine again for the first period of time until anything fails again. And the nvme that failed here is brand new I bought it yesterday. In the first picture you can see the the failed drive "Gaming" and it was originally named or mounted nvme2n1. In the second picture you see same drive under unassigned devices and it is named as nvme0n1 same as the second drive in first nvme pool "Application 2", but not mountable. There seems to be something mixed up in the SW!? Propably my problems started with update to 7.1.4? No accusation, just a observation. The fail this time started with a missing green bulb in front of the Name "Gaming" during a file transfer >1TB between this two pools by the move button. I rebooted after cold start, without switching of power supply. After reboot it showed the red X and I did first diagnostic file. I rebooted again checked in the bios, drive is recognized and with the same numbering as shown in the two nvme pools. Unraid reboots but doesn't find it as nvme2n1 but as unassigned under nvme0n1 that is already used!? And I did the second diagnostic file. In the terminal window all drives can be found with the correct naming. This was now round about the 15th failed hdd or ssd drive in the last 10 days. And I nearly changed the full HW except the case and half the drives. Do you think it could help to fully new install unraid?
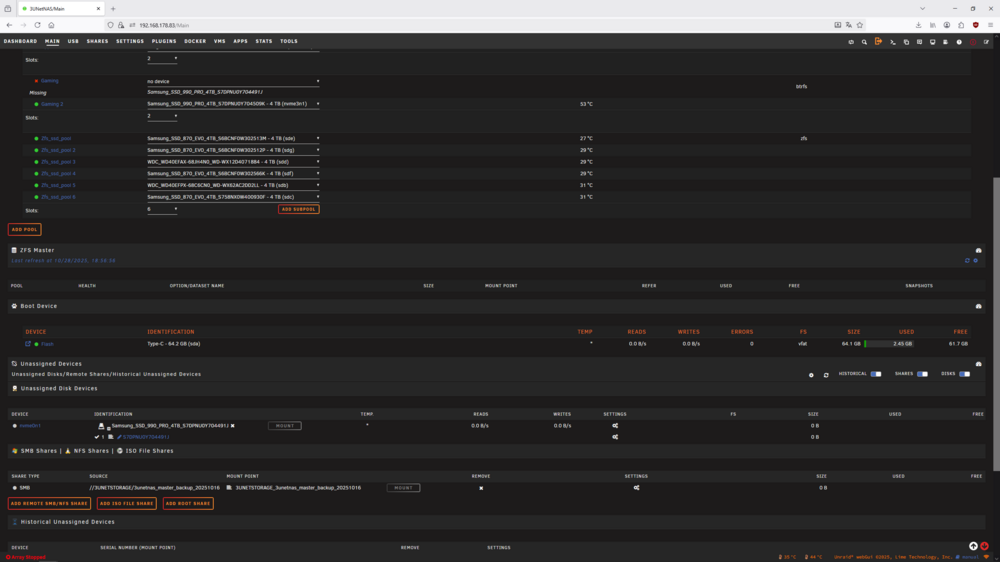
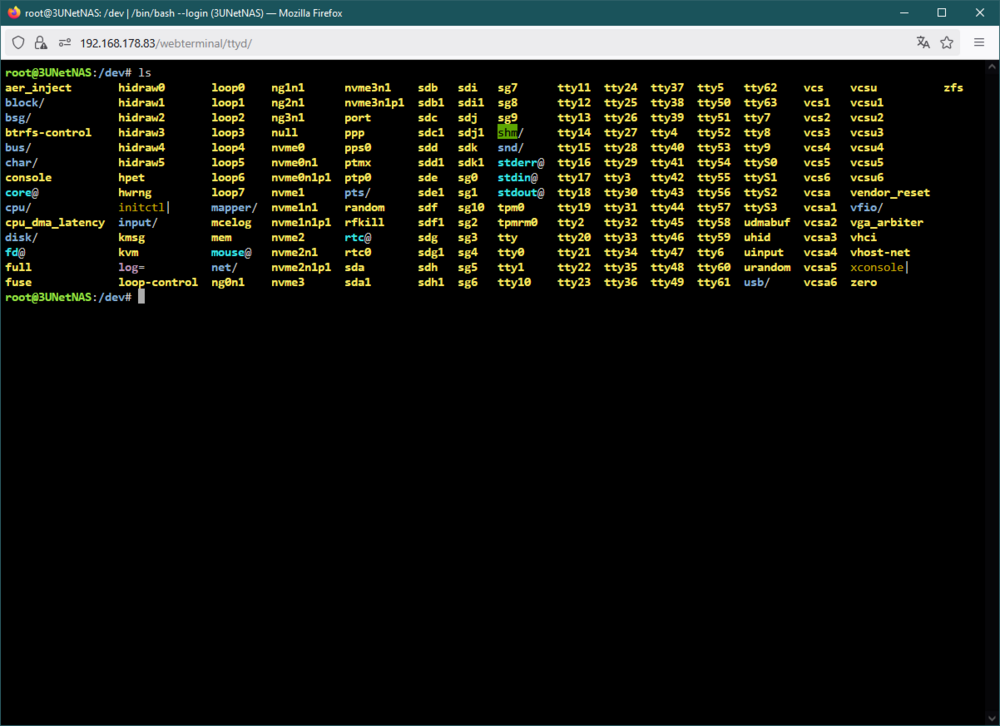
-
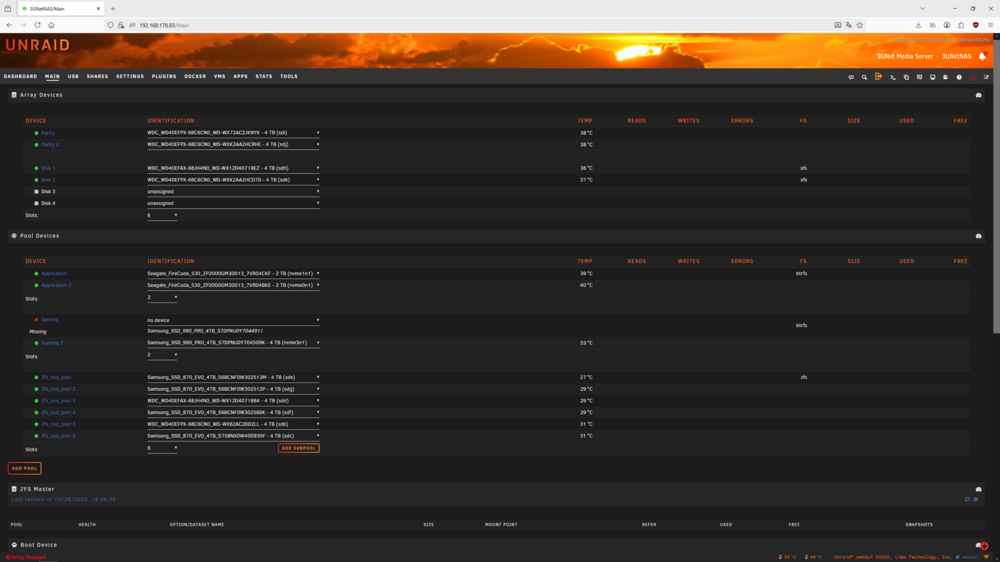
Drive nvme2n1 already fully failed and is not mountable, but is was recogniced by bios before booting this time. Guess it doesn't help to boot again, but I have the diagnostic file before I rebooted. Does this help? diagnostics-20251028-1545.zip









