




jpfeifer14
Members
-
Joined
-
Last visited
-
When attempting to use the config template provided in the set up documentation, I consistently get this error in the logs Database connection failure: invalid integer value "=" for connection option "port" My odoo.conf is as follows:
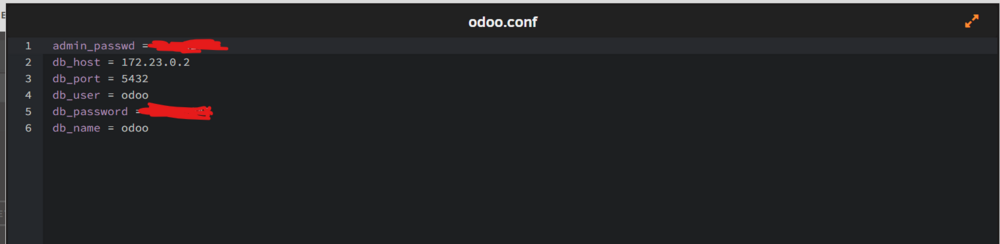
-
This plugin appears broken on Unraid 7, any plans to update?
-
Proxied Cloudflare domains only handle HTTPS traffic, so RustDesk does not work over cloudflare tunnels.
-
@scolcipitato Thats very unfortunate, I loved that plugin
-
Does anyone have experience with this error: Some headers are not set correctly on your instance - The `Strict-Transport-Security` HTTP header is not set (should be at least `15552000` seconds)? Ive tried everything to make it go away. Cloudflare proxy both on and off, HSTS set in cloudflare to 6 months, HSTS set in Nginx Proxy Manager, and any combination of those options. When I use a web utility to check HSTS, it says that I have it enable and for far longer than the minimum in the error, but it still will not go away. Ive read about everything I can find and tried all possible solutions I've come across, so I am kind of at a loss here.
-
I finally caught the error as it was happening and was about to get the logs leading up to the repeating line. Jun 18 15:54:15 cloud kernel: usb 1-4: reset full-speed USB device number 4 using xhci_hcd Jun 18 15:54:15 cloud kernel: usb 1-4: reset full-speed USB device number 4 using xhci_hcd Jun 18 15:54:15 cloud kernel: cp210x 1-4:1.0: cp210x converter detected Jun 18 15:54:15 cloud kernel: usb 1-4: cp210x converter now attached to ttyUSB0 Jun 18 15:54:15 cloud kernel: cp210x 1-4:1.1: cp210x converter detected Jun 18 15:54:15 cloud kernel: cp210x 1-4:1.1: Failed to attach ACPI GPIO chip Jun 18 15:54:15 cloud kernel: usb 1-4: cp210x converter now attached to ttyUSB1 Jun 18 15:54:15 cloud usb_manager: Info: rc.usb_manager tty_add Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB0 Jun 18 15:54:15 cloud usb_manager: Info: rc.usb_manager tty_add Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB1 Jun 18 15:54:15 cloud kernel: usb 1-2.3: reset high-speed USB device number 7 using xhci_hcd Jun 18 15:54:15 cloud usb_manager: Info: rc.usb_manager Processing tty attach Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB0 Jun 18 15:54:15 cloud usb_manager: Info: rc.usb_manager Processing tty attach Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB1 Jun 18 15:54:15 cloud usb_manager: Info: rc.usb_manager Autoconnect No Mapping found Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB1 port Jun 18 15:54:15 cloud usb_manager: Info: rc.usb_manager Autoconnect No Mapping found Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB0 port Jun 18 15:54:17 cloud kernel: cp210x ttyUSB0: cp210x converter now disconnected from ttyUSB0 Jun 18 15:54:17 cloud kernel: cp210x 1-4:1.0: device disconnected Jun 18 15:54:17 cloud kernel: cp210x ttyUSB1: cp210x converter now disconnected from ttyUSB1 Jun 18 15:54:17 cloud kernel: cp210x 1-4:1.1: Failed to retrieve ACPI GPIO chip Jun 18 15:54:17 cloud kernel: cp210x 1-4:1.1: device disconnected Jun 18 15:54:18 cloud kernel: usb 1-4: reset full-speed USB device number 4 using xhci_hcd Jun 18 15:54:19 cloud kernel: usb 1-4: reset full-speed USB device number 4 using xhci_hcd Jun 18 15:54:19 cloud kernel: cp210x 1-4:1.0: cp210x converter detected Jun 18 15:54:19 cloud kernel: usb 1-4: cp210x converter now attached to ttyUSB0 Jun 18 15:54:19 cloud kernel: cp210x 1-4:1.1: cp210x converter detected Jun 18 15:54:19 cloud kernel: cp210x 1-4:1.1: Failed to attach ACPI GPIO chip Jun 18 15:54:19 cloud kernel: usb 1-4: cp210x converter now attached to ttyUSB1 Jun 18 15:54:19 cloud kernel: cp210x ttyUSB0: cp210x converter now disconnected from ttyUSB0 Jun 18 15:54:19 cloud kernel: cp210x 1-4:1.0: device disconnected Jun 18 15:54:19 cloud kernel: cp210x ttyUSB1: cp210x converter now disconnected from ttyUSB1 Jun 18 15:54:19 cloud kernel: cp210x 1-4:1.1: Failed to retrieve ACPI GPIO chip Jun 18 15:54:19 cloud kernel: cp210x 1-4:1.1: device disconnected Jun 18 15:54:19 cloud usb_manager: Info: rc.usb_manager tty_add Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB0 Jun 18 15:54:19 cloud usb_manager: Info: rc.usb_manager tty_add Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB1 Jun 18 15:54:19 cloud kernel: usb 1-2.3: reset high-speed USB device number 7 using xhci_hcd Jun 18 15:54:19 cloud usb_manager: Info: rc.usb_manager Processing tty attach Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB1 Jun 18 15:54:19 cloud usb_manager: Info: rc.usb_manager Autoconnect No Mapping found Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB1 port Jun 18 15:54:19 cloud usb_manager: Info: rc.usb_manager Processing tty attach Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB0 Jun 18 15:54:19 cloud usb_manager: Info: rc.usb_manager Autoconnect No Mapping found Silicon_Labs_HubZ_Smart_Home_Controller_6160034E /dev/ttyUSB0 port Jun 18 15:56:21 cloud kernel: usb 1-4: usbfs: process 20431 (qemu-system-x86) did not claim interface 1 before use And then the last line repeats until the log fills and system crashes
-
It crashed the server, so I had to reboot. I looked for the historical log entries in the local log server, but the entire log was populated with the same error.
-
Unfortunately the backup syslog provided no extra context, just that same error repeating. The log history ended before it showed the start of the error.
-
Is there a way to at least maybe stop a crash from the log filling up? Can it be set to only retain a certain number of log entries? When the server crashes and Im out of town its a bit of a problem.
-
That was a past issue I had, I thought I had limited its ram usage. But the other day, and one other time this month, the error from my original post was filling the logs
-
cloud-diagnostics-20240514-2206.zip
-
Unraid is intermittently crashing because the log fills up with this error: May 13 12:00:00 cloud kernel: usb 1-4: usbfs: process 14474 (qemu-system-x86) did not claim interface 1 before use [4:50 PM] usb 1-4 is a zwave/zigbee controller attached to HA vm. Most of the time there is no issue, but occasionally it starts throwing back that error and the whole server crashes as a result of the Log filling up.
-
Is there anyway I can prevent the syslog from filling up and causing the system to crash from memory usage? Ive had a errors with a VM and a container recently that caused the log to fill up and crash the system. I fixed the errors, but I am worried about this happening with something else when I am out of town and unable to physically restart the server.
-
This appears to be an issue with the Frigate docker container so rapidly blowing through 128 GB of RAM that the system halts and never records an error, I have submitted a request on their github
-
Well, started adding back in services after no crashes in 48 hours. Ran the whole thing full force with a stress test on the cpu, all drives spinning, every container running and still only pulled 276w on the 750w psu, so Im kinda at a loss hardware wise. I guess it's not too late to RMA every component and pray it was one of those pieces.
