



EldonMcGuinness
Members
-
Joined
-
Last visited
Everything posted by EldonMcGuinness
-
I have this very issue. From time to time I have a router that is reset and when that happens I have to get to the unraid server in person and alt-ctrl-del to initiate a reboot. The router is setup to give the server a static IP and the server is setup to use a static ip as well, not sure what the issue is. Another issue is you can't login via cli as when you type in root you are not prompted for a password and the attempt times out after 60 seconds.
-
That all just depends on how your service can access the data. It is just an SQLite database file that resides on your thumb drive. If your service in question can read from the file, you're welcome to pull data right from there. As for a graph, I highly doubt I'll be adding anything of that nature as it just seems overkill. The point of this was just to get a running idea of how often your drives are awake or asleep. I'm not adverse to somebody proposing a pull request to add this feature though. 😉
-
Ahh true, still a valid solution for bitrot or other possible corruption issues of that nature that are more of a passive issue.
-
Well parity should be able to, and at least did for me, just fine. Consider this situation: You have 6 disks Disk 1 through 6 being found at /mnt/disk1 through /mnt/disk6. Parity checks are not set to correct the parity drive, meaning if a discrepancy is found one could still read the previous parity (checked?) version. This means is say /mnt/disk2/somefile.txt were to suffer from bitrot, overwriting, or really anything else (EDIT: Forgot parity is actively written, thanks @primeval_god) one can pull disk2 from the array and then access the parity (checked? is this the right term) version. Seems like a logical conclusion to me. Kinda like having a non-versioned backup. Assuming you have not overwritten the backup with bad data you could restore from it.
-
It occurred to me yesterday, while trying to restore a file that had somehow been corrupted, that it would be nice to be able to read from an emulated drive and try to recover the file without having to remove the drive from the array temporarily. In my case, I was able to get the file from the emulated drive, after removing the drive that contained the corrupted file, and it was indeed a proper file. Seems like this could be a quick first step for restoring a corrupted file locally before having to resort to pulling a remote backup. If mounting is not feasible, due to file system locks or something similar, perhaps a command could be included in unraid to be able to rebuild a particular file on a specific disk from the parity and the other disks. Something like below would be great. parity-restore /mnt/disk2/somefile.txt /mnt/user/somefile.txt.restored In practice this command would rebuid /mnt/disk2/somefile.txt from the parity disk as well as the other disks, save disk2 of course, and save it to /mnt/user/somefile.txt.restored. Any chance for this, unless there is already a way to do it.
-
Thanks for the heads up, I will put in the next update. I hope to have it out by this weekend.
-
Will do!
-
Is it happening after every reboot or only some reboots?
-
At the moment it does not, but the backend does, so it should just be a matter of building in the UI to capture the needed fields. If you're up for testing, file a bug on the github repo asking for it to be supported so I do not forget. New Backend Request
-
I wanted a better way to backup some of my local files to a cloud provider and did not want to have to rely on a container or VM to do so. To this end I have written a backup plugin that allows me to do so. At the moment it is just oAuth2 based, however, it uses rclone for a backend so I could add other destination types. The project is on GitHub in case you want to review the codebase. The plugin allows you to do 3 types of jobs: Backup - This copies files from the unraid server to the remote storage Archive - This moves files from the unraid server to the remote storage Sync - This is a bi-directional sync so changes on either side are replicated both ways In addition to this, it uses cron scheduling to automate calling of the backup commands. [ https://github.com/EldonMcGuinness/UnraidCloudBackup ] At this time the plugin is a beta, and I am looking for testers. As it currently sits, it allows you to hook connect to Dropbox, GoogleDrive, and Box. If you have another use case, and are willing to help test, let me know and I'll see what I can do on getting it in there. Below are images of the current interface. Do be aware, as oAuth2 does require a FQDN to connect and properly process callbacks, I did need to write a server-side client script, which I am hosting as a github page, to handle the handshake and requesting of tokens to give back to rclone. This too is on github for your review, since I know this might be a point of contention. If you are interested in testing, please let me know how it goes or if you need help installing the plugin. A link the the plg file is below: [ https://raw.githubusercontent.com/EldonMcGuinness/UnraidCloudBackup/master/CloudBackup.plg ] You will need to setup your own client id and secret, which is free, until I find out what all I need to do to open my generated client/secret it up for general use with the different providers. The callback URL you will want to use for your application/client is [ https://eldonmcguinness.github.io/UnraidCloudBackup/callback ], again, this does not log anything at all and the code base is on github as well. Plugin @ Github Auth Server @ Github
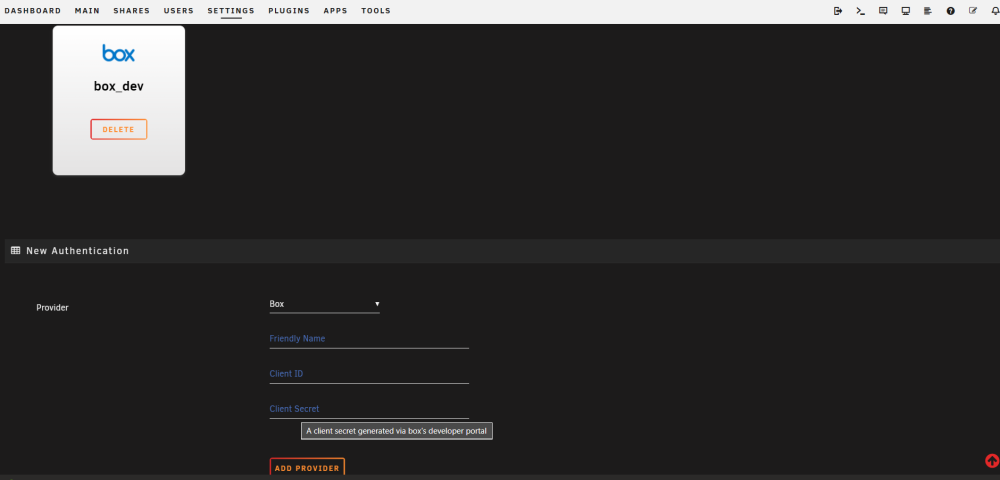
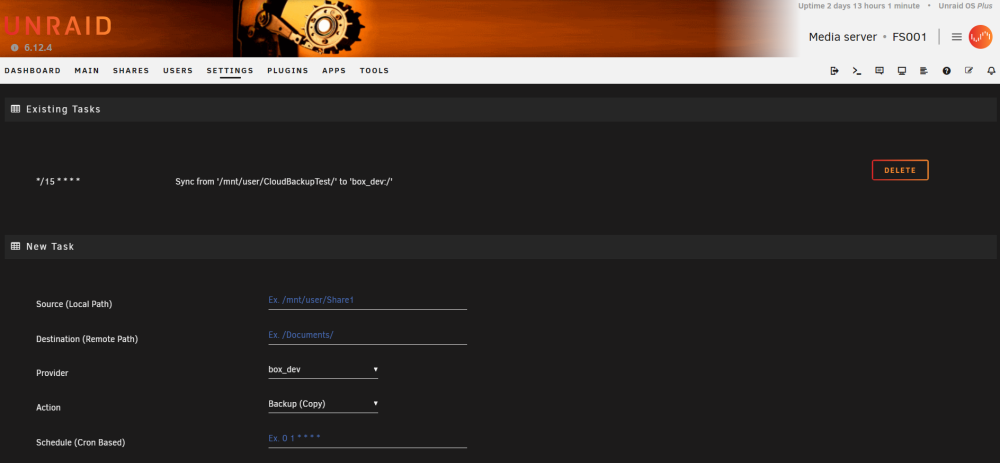
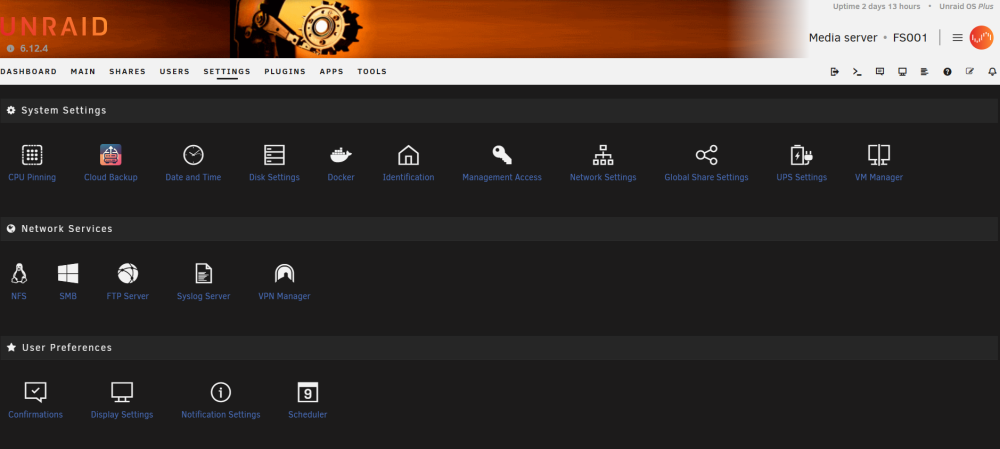
-
@kiwijunglist I would love to add this to the plug-in as well as a few other things, perhaps I will have some more time soon. At the risk of sounding like a mad capitalist, donations towards getting features added are always nice and will definitely help to move things along. If you're interested, you can do so on the github repo. @kiwijunglistI have moved away from manual polling and instead use the built-in polling that is part of unraid, this should not be an issue any longer. @fr500 I'm not sure on this one, I'm running the latest version and am not seeing this, additionally, I have other testers that have confirmed it is not happening to them either. Perhaps this is unique to your setup?
-
What version of Unraid are you running?
-
I'm not seeing that behavior, do be aware that this does use cookies to store the information. Perhaps you have cookies disabled? Try it in "in-private or incognito" mode with your browser and let me know what happens.
-
That is so odd, you are the second person that said that. I wonder if it is due to my script clashing/relying on anther script inadvertently. I will take a look. 👍 EDIT: This is indeed what was happening, this is fixed in the next build [2023.11.26-004] Also added dev support as of [2023.11.27-002]
-
I don't think so as this is a longitudinal average of queries. If I don't have the intervals logged then, when they are all counted up and divided, the averages would not be the same. The way I calculate it is a simple average: Without each interval I would not be able to take a quick sum and it likely would get more complicated for minimal gain. There is currently a show toggle that lets you hide it and it is cookie based so it should stick across sessions. I will have to look into this once I have an unassigned drive to test, unless someone would like to be my guineapig. In the case that you or someone else would, let me know and I'll setup a dev branch for you to test.

.png.df98e955c7ff82fdd999a25bcc842411.png)
-
@sonic6 I am uploading a fix for this right now, it looks like the plugin installer does not overwrite old files when the file is made via a <FILE></FILE> tag. Version 2023.11.24-005 should fix this issue.
-
The latest version reworked the backend, give it a go and see what you get. If there is data that you want to clear, you can reset the database in the tools page or you can hide the lines you want via the "edit" button on the main page. Thank you for testing it and all the feedback!
-
@SimonF That is an interesting idea and I will look into that, it would allow me to make sure there is parity between the status unraid is showing and what the plugin logs show. Update: OK, reworked the backend to make use of the existing unraid data. @bombz,let me know if that make a difference for you.
-
@bombz those are some interesting results. /dev/sdb looks like it was awake and in use, not sure why hdparm returned a result code of 1 though /dev/sdc looks like it went to standby and stayed there /dev/sdd looks like it went to standby and stayed there /dev/sde looks like it was in standby and then was woken up by smartctl or something else /dev/sdf looks like it went to standby and stayed there /dev/sdg looks like it was in standby and then was woken up by smartctl or something else /dev/sdh looks like it went to standby and stayed there /dev/sdi looks like it was awake and in use, not sure why hdparm returned a result code of 1 though /dev/sdj looks like it was awake and in use, not sure why hdparm returned a result code of 1 though /dev/sdk looks like it was in standby and then was woken up by smartctl or something else /dev/sdl looks like it was in standby and then was woken up by smartctl or something else /dev/sdm looks like it was in standby and then was woken up by smartctl or something else /dev/sdn looks like it was in standby and then was woken up by smartctl or something else /dev/sdo looks like it was in standby and then was woken up by smartctl or something else An interesting thing to note is that sdb, sdi, and sdj all get a return code of 1 from hdparm. I'm not sure why that is the case and you will likely need to investigate that further. hdparm -I /dev/sdb What I would look at next is what type of drives these are and how they are hooked up to see if there is a correlation. Additionally, if there is no correlation, you might need to shut all the services down and turn off the array and try the command again to look for different results. In case you are curious the way the results reads is as follows: Is the drive in standby [0:Yes] Run hdparm and see if the command runs without errors [0:OK] Is the drive in standby [0:Yes] Is the drive in standby [0:Yes] Run smartctl runs and reports the drive as in standby [0:Yes] Is the drive in standby [0:Yes] Anytime you see a 1 in the results, that means the drive was not in standby or the command did not execute properly.
-
in this case it looks like hdparm is waking the drive. Give this a try and post back what you get, this tries to put the drive to sleep then query it and then check the status again. It will do it with both hdparm and smartctl. curl -s https://gist.githubusercontent.com/EldonMcGuinness/ea36fd56660860f851395aab42cfbbc1/raw/739ada10cab68f5bf45bf377dd7f04553327ab61/diskstandbytest.sh | bash You should get back something like: Starting Sleep Tests ============================== Testing /dev/sdb: [ 0 | 0 | 0 | 1 | 0 | 1 ] Testing /dev/sdc: [ 0 | 0 | 0 | 0 | 0 | 0 ] Testing /dev/sdd: [ 0 | 0 | 0 | 1 | 0 | 1 ] Testing /dev/sde: [ 0 | 0 | 0 | 0 | 0 | 0 ] Testing /dev/sdf: [ 1 | 1 | 1 | 1 | 0 | 1 ] Testing /dev/sdg: [ 1 | 1 | 1 | 0 | 0 | 1 ] Testing /dev/sdh: [ 1 | 1 | 1 | 0 | 0 | 0 ] Testing /dev/sdi: [ 0 | 0 | 0 | 0 | 0 | 0 ] Testing /dev/sdj: [ 0 | 0 | 0 | 0 | 0 | 0 ] Testing /dev/sdk: [ 0 | 0 | 0 | 0 | 0 | 0 ] Testing /dev/sdl: [ 0 | 0 | 0 | 0 | 0 | 0 ] Testing /dev/sdm: [ 0 | 0 | 0 | 0 | 0 | 0 ]
-
@SimonF Indeed however, using smartctl -i -n standby /dev/sdX does not get you the serial number or model number of the drive in question, only an exit code of 2. I thought about using hdparm, which sdspin is using, to get the serial and model number, but that could result in spin up of the drive according to sources on Google. It seems, since there really is no 100% standard to how drives and controllers act with regard to querying standby status, there are reports of virtually every command out there spinning up some type of drive/setup, the best one can do is shoot for what should work. As the script sits now, it captures the serial+model of each drive when checking to make sure no drives have changed their assignment. I do want to try to hook into udev and do something a bit more intelligent there, but as of now this seems to work well except for outlier cases when the drives or the controllers are not following regular standards. I think I'll add a disclaimer in the app description that some drives and controllers may not work correctly with it due to deviance from the standards. @bombz You got it, just post that in the console and post what you get. What is your standby timer set to? I would expect that if the plugin were spinning up your drives then I would see a uniform wake/sleep of the drives, then again, this is just the emhttpd log and I don't think it logs outside actions of waking and sleeping, at least it is not when I test it.
-
Out of curiosity, what model? I'm using the 9207-8i. Additionally, try the following command and let me know what you get, this will test all your drives /dev/sdb thru /dev/sdz: curl -s https://gist.githubusercontent.com/EldonMcGuinness/ea36fd56660860f851395aab42cfbbc1/raw/39a92fa5b63b71c4d155ba72a2ba3e0b2bb71a83/diskstandbytest.sh | bash Don't bother with the below snippet, but I'm leaving it for posterity. clear echo Put Drive to Sleep hdparm -y /dev/sdX sleep 20 hdparm -C /dev/sdX sleep 20 echo Try hdparm -I hdparm -I /dev/sdX > /dev/null sleep 20 hdparm -C /dev/sdX sleep 20 echo Try smartctl -i -n never smartctl -i -n never /dev/sdX > /dev/null sleep 20 hdparm -C /dev/sdX NOTE: replace /dev/sdX with the target drive
-
@bombz Do keep me posted! The script side of it uses `smartctl` to query the drive status and other information, but it should not spin up a drive that is currently in standby. I have testing this with a range of internal drives, both connected directly to the motherboard and via a pcie hba, and have yet to see the drives spin-up. That being said, I have read some things online that people using USB enclosures could see the command spin up the drives due to the controller that the USB enclosures use. However, USB enclosures are not know for following the rules when it comes to SMART data. 😁 If you do see an issue feel free to open an issue on github as well.
-
This plugin allows you to track how long your drives are (or are not) in standby. This is great for those that are trying to make their rig as low power as you can as it will allow you to see what drives are highly active. The plugin gives you an overview of activity per device, but also gives you a breakdown of the status changes. It scans your drives every 15 minutes, this should not cause them to spin up, and logs the data. Upcoming releases will tie the data to drive serial numbers and show a bit more information as to disk names, currently it is based on the dev name (/dev/sdX). You can check out the repo HERE if you come across a bug or issue feel free to open a issue on Github as well. If you're having an issue related to drives spinning up and believe it is related to the plug-in, please file a ticket on the github repo using this link as it has a command you can run and get a better look into what the issue might be.
-
Good find! I was able to get it working by modifying the at command and doing: at -M -f /tmp/start_DrvStdbyMon now + 1 2>/dev/null I think it is a bit of a race condition that might be happening.





.png.df98e955c7ff82fdd999a25bcc842411.png)
