




Thomas Gunn
Members
-
Joined
-
Last visited
-
Thanks for the help
-
I also added the script you mentioned in this post, for monitoring zpools going forward
-
That worked. Thanks. Just to clarify for others that might be gunshy and not as familiar with UNRAID yet, such as myself, I did what you said with: Stop the array Make note of all disk assignments order (as was mentioned in another thread) Unassign all pool devices Start array (check mark for 'Yes, I want to do this' for 'Start will remove the missing cache disk and then bring the array on-line') Stop array Re-assign all pool devices Start array Would it be likely that the resilvering caused the disk count to go up?
-
Hello. Just finished rebuilding 2 drives. Array started up after, all seemed good. Then the zpool was writing a lot with docker disabled. Looked at stats for zpool scrub section and said it was degraded and being resilvered. That completed, pool was back to good. Rebooted then couldn't start the array even though the GUI said it had a valid configuration. Syslog shows 'zfs_pool: invalid config: root_slots 6 num_slots 3' and there are only 3 drives for that pool. Sounds like this might be same/similar: Imported: zpool import zfs_pool, then root@7OM-UNRAID:~# zpool status -v pool: zfs_pool state: ONLINE scan: resilvered 153G in 00:21:49 with 0 errors on Sun Feb 18 23:50:54 2024 config: NAME STATE READ WRITE CKSUM zfs_pool ONLINE 0 0 0 raidz1-0 ONLINE 0 0 0 sdn1 ONLINE 0 0 0 sdq1 ONLINE 0 0 0 nvme0n1p1 ONLINE 0 0 0 errors: No known data errors Wanted to check if I should do the same from the post to actually fix the problem. 7om-unraid-diagnostics-20240219-0223.zip
-
USB got me through previous setups but doesn't seem sufficient for UNRAID. Will look through the hardware section to see what are some good setups for the amount of drives I have, currently will be 18 (HDDs - 3.5", SSDs - 2.5" & NVME). Due to USB and 2 drives being problems, I played it safer and didn't go the Parity Swap route. But that would be great for the future. I moved some drives around to another enclosure so the 8 bay would only have 1 drive, instead of 2, for each controller, in hopes that it wouldn't cause the same problem again during the rebuild. I don't have another replacement for disk8 (with all the errors), so I put in the old disk8 that has a few errors and will see how the rebuild goes this time and go from there. Doing more passes of preclearing for the 2 new 18TBs while it rebuilds. Seems to be ok to do at the same time. Let me know if this is unwise.
-
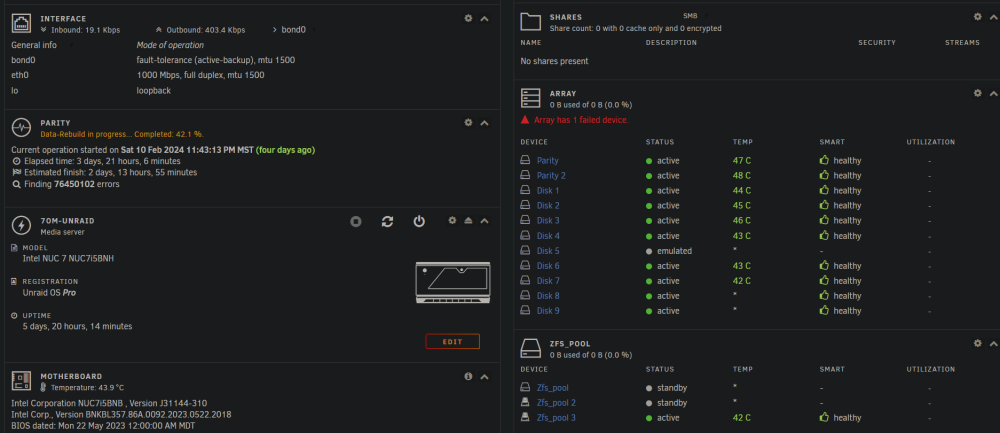
Looks like at 19:12 something happened with the USB for that 1 controller in the enclosure and the disks aren't reading anymore for 8 and 9, hence why I couldn't do the smart test on disk 9.
-
And the log is full. Did the diagnostics even give you the right thing you needed?
-
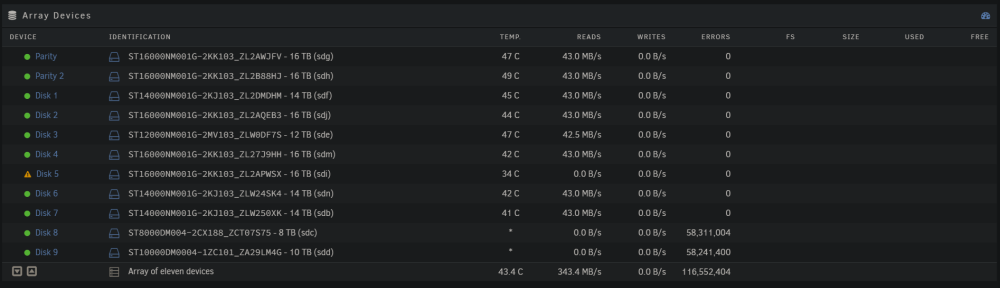
Just noticed that parity is showing all those errors as well now on the dashboard, whereas when it was 61 000 parity didn't show any errors I'm pretty sure.
-
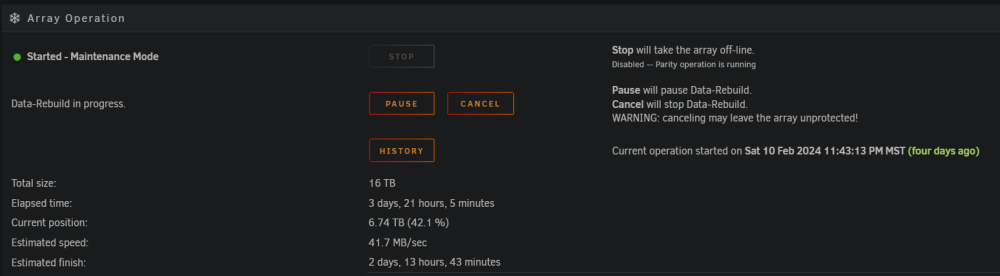
None are showing smart warnings right now, but disk 8 was before I'm pretty sure. I have 2 new drives but they're 18TB, so was going to use them for new parity drives after all of this got sorted out and use the 16TB parities to replace the 8TB and keep one as a precleared spare. The 8TB that's in there now actually replaced a different 8TB that was having a few issues. Seems like this one is even worse. I even did a full badblocks run with 4 passes of writes (0 01 10 11, I believe) on it before adding it and extended test to make sure it was decent. Didn't show any errors then. Yes have alerts setup immediately via PushOver. Since posting earlier, the error count has skyrocketed from 61 000 to 67 000 000 @ 6.7 of 16TB rebuilt, and now disk 9 is showing about the same as what disk 8 does. Tried to do a short SMART test via GUI on disk 9 but it won't run it. Didn't try via CLI yet. Disk 8 and 9 are in the same USB enclosure. It's an 8 bay enclosure, but only shows up as 4 paired controllers (or something like that when I had it on windows). 8 and 9 are on the same controller, even though it says in the notes: 1-1 for disk 9 and 1-8 for disk 8 (it was swapped to 1-2 when doing some troubleshooting and didn't move it back). I'm guessing that's why it's showing that, but don't know why exactly. Also, disk 5 is now not showing any writing to it while the rebuild progresses now and is skipping along at 62MB/s, when it was usually 30MB/s before. What would you suggest or what else can I provide for details? 7om-unraid-diagnostics-20240214-2024.zip
-
I'm not used to parity yet so I was getting all the files off the drive while it was able to be read. But yes, thank you. While disk 5 is rebuilding, the drive that I wanted to remove before [disk 8] has a tonne of reallocated and reported uncorrect sectors (currently 61k errors @ 6 of 16 TB rebuilt). No errors are reported on the rebuilding process. This is affecting the rebuild time substantially; which I can live with as long it gets done right. Will these bad sectors affect the files rebuilt for disk 5?
-
Thanks for the help. It's rebuilding now.
-
Is rebuilding the only way to fix a disabled drive? This looks like the instructions I need to follow. Just want to make sure since this is the first time I've had to do this with a drive that I hadn't cleared and replaced. https://docs.unraid.net/unraid-os/manual/storage-management/#rebuilding-a-drive-onto-itself
-
Will do Is there anywhere that tells what exactly it is that UNRAID doesn't like about the drive and why it's disabled?
-
@trurl No it was pretty full due to emptying Drive 8 for having bad sectors and getting ready to replace it. @itimpi Thanks for the tip.






