




Deler7
Members
-
Joined
-
Last visited
-
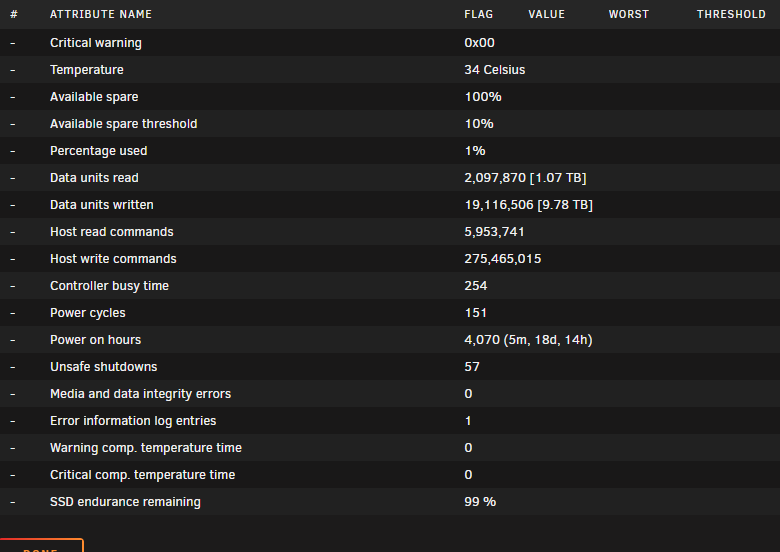
Initially, i couldn't do the readonly mount as specified. When i changed /mnt/cache into just cache , it worked. Then i proceed as advised, started the array, copied the files from the cache, erased the cache drives, re-format. Reboot, copy all files back to the new cache pool, and enabled docker again. Everything worked again as before. Many many thanks for this great advise and lightning fast support ! Now everyting is up and running again, i'm now wondering how this could happen. Is it most likely a HW issue, or perhaps a misbehaving docker, or is it just a ZFS quirk that just could happen anytime to anyone ? As attached, the 2x WD RED 1TB NVME drives are fairly young, only 9.78TB written, and i don't see any issues on it ? Otherwise, I just knock on wood this won't happen again soon
-
Out of the blue, my server was somehow stopped working after a few weeks of uptime. Could not access GUI, so i rebooted the server. Server seems booting fine, but when i try to start the array, things goes wrong. i did a 4hour memtest (latest from memtest.org, not the one included on unraid USB), 0 errors. I disabled DOCKER and VM, to make sure they are not causing the issue. As when starting the array, i cannot make a diagnostic file, perhaps this information from the syslog below could help to diagnose the issue ? Aug 4 20:48:18 SERVER1 emhttpd: mounting /mnt/cache Aug 4 20:48:18 SERVER1 emhttpd: shcmd (568): mkdir -p /mnt/cache Aug 4 20:48:18 SERVER1 emhttpd: shcmd (569): /usr/sbin/zpool import -f -N -o autoexpand=on -d /dev/nvme1n1p1 -d /dev/nvme2n1p1 1547749684351647778 cache Aug 4 20:48:18 SERVER1 kernel: VERIFY3(size <= rt->rt_space) failed (281442900058112 <= 8586334208) Aug 4 20:48:18 SERVER1 kernel: PANIC at range_tree.c:436:range_tree_remove_impl() Aug 4 20:48:18 SERVER1 kernel: Showing stack for process 7359 Aug 4 20:48:18 SERVER1 kernel: CPU: 6 PID: 7359 Comm: zpool Tainted: P O 6.1.74-Unraid #1 Aug 4 20:48:18 SERVER1 kernel: Hardware name: Gigabyte Technology Co., Ltd. Z690 AORUS MASTER/Z690 AORUS MASTER, BIOS F8 08/08/2022 Aug 4 20:48:18 SERVER1 kernel: Call Trace: Aug 4 20:48:18 SERVER1 kernel: <TASK> Aug 4 20:48:18 SERVER1 kernel: dump_stack_lvl+0x44/0x5c Aug 4 20:48:18 SERVER1 kernel: spl_panic+0xd0/0xe8 [spl] Aug 4 20:48:18 SERVER1 kernel: ? slab_free_freelist_hook.constprop.0+0x3b/0xaf Aug 4 20:48:18 SERVER1 kernel: ? bt_grow_leaf+0xc3/0xd6 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? bt_grow_leaf+0xc3/0xd6 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? zfs_btree_find_in_buf+0x4c/0x94 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? zfs_btree_find+0x16d/0x1b0 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? rs_get_start+0xc/0x1d [zfs] Aug 4 20:48:18 SERVER1 kernel: range_tree_remove_impl+0x77/0x406 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? zio_wait+0x1ee/0x1fd [zfs] Aug 4 20:48:18 SERVER1 kernel: space_map_load_callback+0x70/0x79 [zfs] Aug 4 20:48:18 SERVER1 kernel: space_map_iterate+0x2d3/0x324 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? spa_stats_destroy+0x16c/0x16c [zfs] Aug 4 20:48:18 SERVER1 kernel: space_map_load_length+0x93/0xcb [zfs] Aug 4 20:48:18 SERVER1 kernel: metaslab_load+0x33b/0x6e3 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? zap_lookup_impl+0x1b0/0x1da [zfs] Aug 4 20:48:18 SERVER1 kernel: ? zap_lookup_impl+0x1b0/0x1da [zfs] Aug 4 20:48:18 SERVER1 kernel: vdev_trim_calculate_progress+0x12e/0x217 [zfs] Aug 4 20:48:18 SERVER1 kernel: vdev_trim_load+0x13d/0x148 [zfs] Aug 4 20:48:18 SERVER1 kernel: vdev_trim_restart+0x144/0x1f0 [zfs] Aug 4 20:48:18 SERVER1 kernel: vdev_trim_restart+0x1cc/0x1f0 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? preempt_latency_start+0x2b/0x46 Aug 4 20:48:18 SERVER1 kernel: vdev_trim_restart+0x1cc/0x1f0 [zfs] Aug 4 20:48:18 SERVER1 kernel: spa_load+0xfcc/0x1110 [zfs] Aug 4 20:48:18 SERVER1 kernel: spa_load_best+0x61/0x267 [zfs] Aug 4 20:48:18 SERVER1 kernel: spa_import+0x282/0x5ac [zfs] Aug 4 20:48:18 SERVER1 kernel: ? get_nvlist+0xe8/0x119 [zfs] Aug 4 20:48:18 SERVER1 kernel: zfs_ioc_pool_import+0xea/0x143 [zfs] Aug 4 20:48:18 SERVER1 kernel: zfsdev_ioctl_common+0x68f/0x726 [zfs] Aug 4 20:48:18 SERVER1 kernel: ? mod_lruvec_page_state.constprop.0+0x1c/0x2e Aug 4 20:48:18 SERVER1 kernel: ? __kmalloc_large_node+0xd6/0xfb Aug 4 20:48:18 SERVER1 kernel: ? __kmalloc_node+0x5e/0xb1 Aug 4 20:48:18 SERVER1 kernel: zfsdev_ioctl+0x5b/0xb4 [zfs] Aug 4 20:48:18 SERVER1 kernel: vfs_ioctl+0x1b/0x2f Aug 4 20:48:18 SERVER1 kernel: __do_sys_ioctl+0x52/0x78 Aug 4 20:48:18 SERVER1 kernel: do_syscall_64+0x68/0x81 Aug 4 20:48:18 SERVER1 kernel: entry_SYSCALL_64_after_hwframe+0x64/0xce Aug 4 20:48:18 SERVER1 kernel: RIP: 0033:0x14582ea344e8 Aug 4 20:48:18 SERVER1 kernel: Code: 00 00 48 8d 44 24 08 48 89 54 24 e0 48 89 44 24 c0 48 8d 44 24 d0 48 89 44 24 c8 b8 10 00 00 00 c7 44 24 b8 10 00 00 00 0f 05 <89> c2 3d 00 f0 ff ff 77 07 89 d0 c3 0f 1f 40 00 48 8b 15 f9 e8 0d Aug 4 20:48:18 SERVER1 kernel: RSP: 002b:00007ffe48bbcb18 EFLAGS: 00000246 ORIG_RAX: 0000000000000010 Aug 4 20:48:18 SERVER1 kernel: RAX: ffffffffffffffda RBX: 0000000000433320 RCX: 000014582ea344e8 Aug 4 20:48:18 SERVER1 kernel: RDX: 00007ffe48bbd480 RSI: 0000000000005a02 RDI: 0000000000000004 Aug 4 20:48:18 SERVER1 kernel: RBP: 00007ffe48bc0a60 R08: 000014582eb14490 R09: 000014582eb14490 Aug 4 20:48:18 SERVER1 kernel: R10: 0000000000000000 R11: 0000000000000246 R12: 00007ffe48bbd480 Aug 4 20:48:18 SERVER1 kernel: R13: 000000000043b1b0 R14: 0000000000435930 R15: 0000000000000000 Aug 4 20:48:18 SERVER1 kernel: </TASK>
-
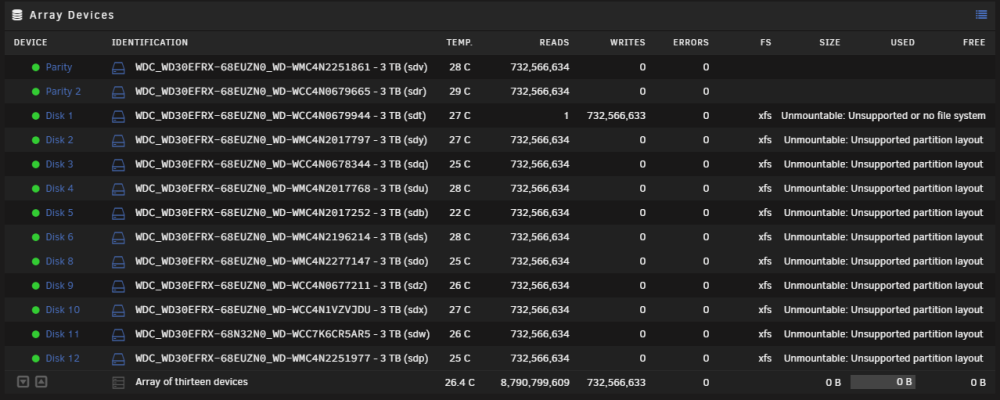
Oh yes, i instantly ordered a cheap LSI 9211-i8 controller and installed it yesterday on the server. As i expected to have some complications, i kept my backups, but this change from Adaptec to LSI went flawlessly. It was more like plug&play, all drives were recognised and the array stated without errors. To make sure everything is OK, i started a paritycheck. Perfect ! All my issues are resolved now. However, perhaps good information for others who are reading this thread in future and have the same issue. I have found the source of my original issue! I now can reproduce the issue. Not the swap to the SAS-SATA cables to SAS-Extender that caused this. It was change of controller mode. The Adaptec 7 series have 4 different controller modes you can pick for operation. - Auto - RAID hide RAW. Act as a pure HW raid controller, unassigned disks are not exposed to OS. - RAID expose RAW.(default) Same as above, but now it exposes unassigned disks not assigned on a HW RAID to the OS. This is the default setting at factory defaults ie. new cards. - HBA. No RAID volumes, all disks are RAW exposed to the OS, comparable to IT mode, this is the mode you should run with UNRAID. Here is the thing, although you might expect "RAID expose RAW" would be the same as "HBA" when having no RAID volumes, IT ISN'T. Switching between those 2 modes does somehow mess up with your partition tables. I did some tests on a discardable array. Create the array when controller is in HBA, then change controller to RAID expose RAW, will render the issue i had on my first post of this topic (drives are unmountable). Even when switching back to HBA mode, the damage is already done, and disk partitions needs to be fixed. Well, how could this happen to me, as i wasn't messing at the controller settings when migrating to a new enclosure. My mainbord UEFI bios. 🤬 As some are aware, when installing the 7 series (and perhaps newer) Adaptec cards on mainbord's that have UEFI, you no longer get the legacy CTRL+A for menu option at bootup, instead, you enter the controller bios within your mainbord UEFI bios at the Add-On devices sub-menu. For me unknown reason, the mainbord also remembers what slot the controller is plugged into, and keep it settings by slot. Meaning, when you change PCIe slot of the controller, at my Gigabyte Z590 mainbord, it defaults the controller to its original setting "RAID expose RAW". And indeed, when i was migrating to the enclosure, i did a one-time boot the system with the controller on a different PCIe slot, as i wanted to test a GPU in its main slot. I didn't check the array at that time, but i did a shutdown, moved the controller back to its original slot, but the 'damage' was already done. Hence my issue above. This seems only happening on my Gigabyte Z590 UEFI based mainbord, as my older dual Xeon legacy BIOS mainbord does not behave like this. On the legacy board, i can move the controller to any PCIe slot i like, it does not change it's mode. But when i install the controller to my Gigabyte Z590, it store my settings per PCIe slot. My lesson learned: do NOT change the PCIe slot of Adaptec cards at UEFI based mainbord's without verifying settings before fist boot. Or buy a LSI HBA in IT mode and never look back
-
It worked, even for DISK1 👍 Thank you all very much for the support !!!
-
A small update from my side. I made a DD copy from 1 disk to one of my new installed HDD's before continuing potentially screwing things (more)up Not sure how to use the gdisk tool, i just tried following a guide, using gdisk on the drive that just got its backup. I went for the "r" option (r recovery and transformation options), then choose "b" (use backup GPT header (rebuilding main)), and when finished write and exit. Then i rebooted the server, but still no luck, same error message. Then, in maintenance mode, in Unraid UI, i went for the same disk, and i started the xfs_repair without any arguments. Rebooted the server again, did a regular ARRAY START and there it was, this particular disk with all its files accessible again ! There were a few (just really only a few) files in the Lost+found folders, but that's OK for me. So, i guess im on the right track (?) At the moment, i'm DD'ing every disk now to my new placed harddrives to have a backup at least. When that is finished, i should follow the same procedure on each disk ?
-
Allright. root@PARODIUS:~# blkid /dev/sda1: LABEL_FATBOOT="UNRAID" LABEL="UNRAID" UUID="2736-60C3" BLOCK_SIZE="512" TYPE="vfat" /dev/loop1: TYPE="squashfs" /dev/mapper/nvme3n1p1: LABEL="nvme-two" UUID="4128737249177850753" UUID_SUB="5585851513646370683" BLOCK_SIZE="4096" TYPE="zfs_member" /dev/nvme0n1p1: LABEL="cache" UUID="17440156396158875726" UUID_SUB="14585744415475683753" BLOCK_SIZE="4096" TYPE="zfs_member" /dev/nvme3n1p1: UUID="ad1f4b74-88bc-409b-8586-e81baf646027" TYPE="crypto_LUKS" /dev/nvme2n1p1: UUID="b8d4d0c9-ec99-4505-8cce-c9a19a817ba1" TYPE="crypto_LUKS" /dev/loop2: UUID="139601bd-7ef3-471e-9dc5-5e5e4f78d045" BLOCK_SIZE="512" TYPE="xfs" /dev/loop0: TYPE="squashfs" /dev/mapper/nvme2n1p1: LABEL="nvme-one" UUID="18166102060409839496" UUID_SUB="9952805448310778193" BLOCK_SIZE="4096" TYPE="zfs_member" /dev/nvme1n1p1: LABEL="cache" UUID="17440156396158875726" UUID_SUB="926196455089919428" BLOCK_SIZE="4096" TYPE="zfs_member" /dev/sdt1: PARTUUID="30cecb74-aef3-47de-99a5-1b6d6033178a" and From DISK2 root@PARODIUS:~# gdisk /dev/sdy GPT fdisk (gdisk) version 1.0.9.1 Caution: invalid main GPT header, but valid backup; regenerating main header from backup! Warning: Invalid CRC on main header data; loaded backup partition table. Warning! Main and backup partition tables differ! Use the 'c' and 'e' options on the recovery & transformation menu to examine the two tables. Warning! Main partition table CRC mismatch! Loaded backup partition table instead of main partition table! Warning! One or more CRCs don't match. You should repair the disk! Main header: ERROR Backup header: OK Main partition table: ERROR Backup partition table: OK Partition table scan: MBR: not present BSD: not present APM: not present GPT: damaged Found invalid MBR and corrupt GPT. What do you want to do? (Using the GPT MAY permit recovery of GPT data.) 1 - Use current GPT 2 - Create blank GPT Your answer: ^C I did the same for DISK3 until DISK12 all have identical results as above. In case of any help, this is the output of the rebuilded DISK1: (see below) root@PARODIUS:~# gdisk /dev/sdt GPT fdisk (gdisk) version 1.0.9.1 Partition table scan: MBR: protective BSD: not present APM: not present GPT: present Found valid GPT with protective MBR; using GPT. Command (? for help): ^C
-
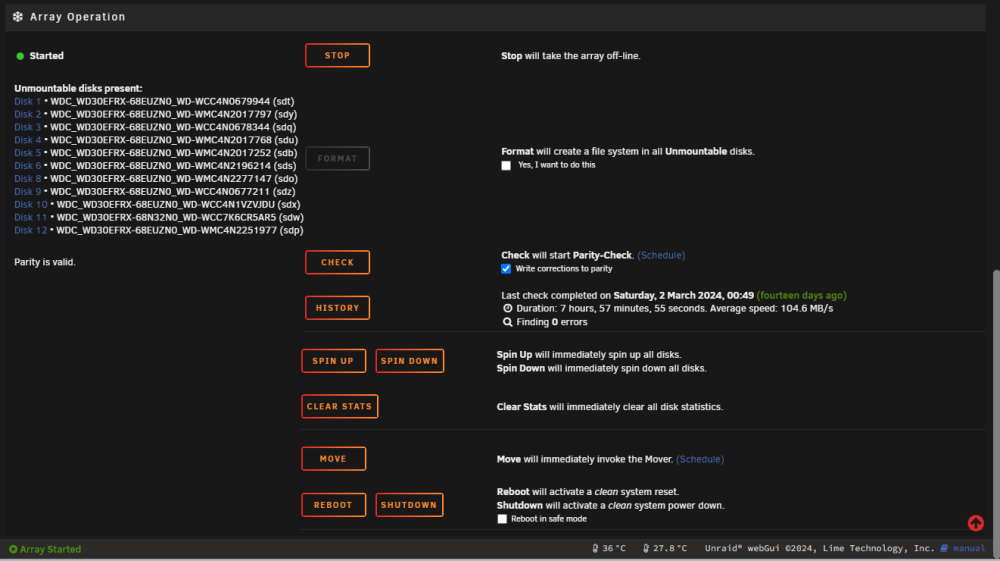
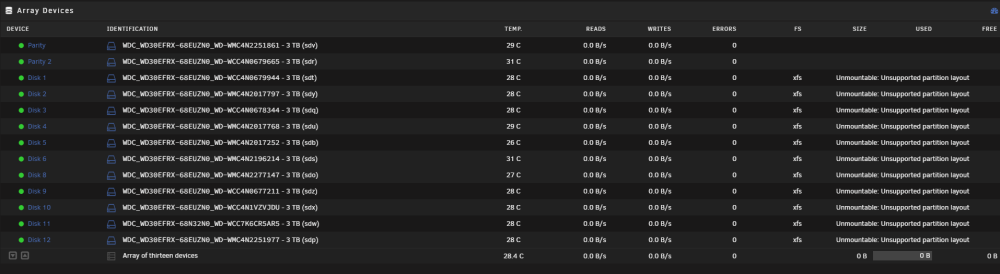
After a night of spinning, the rebuild is complete. I havent rebooted since my previous steps. My new diagnostics below 👍 parodius-diagnostics-20240316-1120.zip
-
Ah, when i checked the box, START remains grey. Closed all browsertabs, did a cache clear, logged back into server, and now it turns orange, so i can proceed now. Removed the disk, checked the box, start array. Stopped the array, reattach the disk i just unassigned. And start the array. I assume, the waiting game starts ?
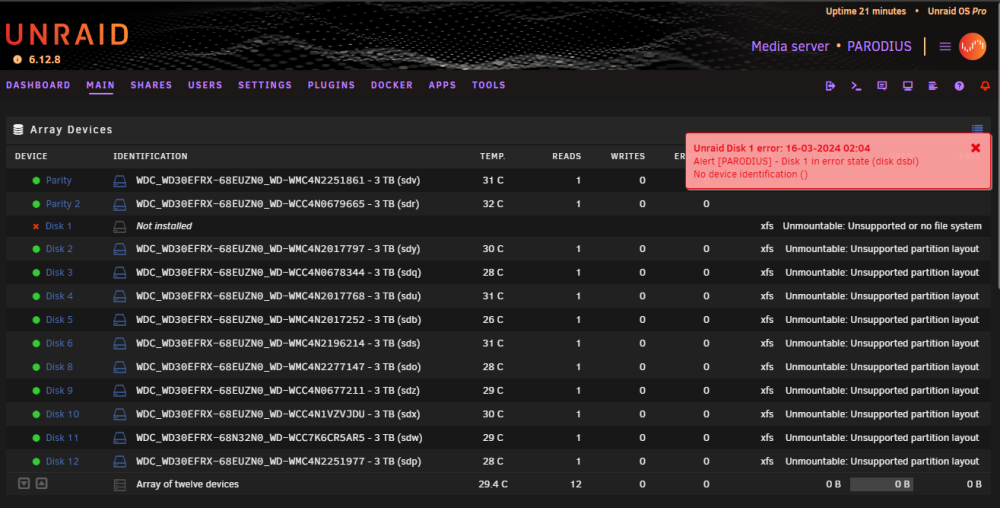
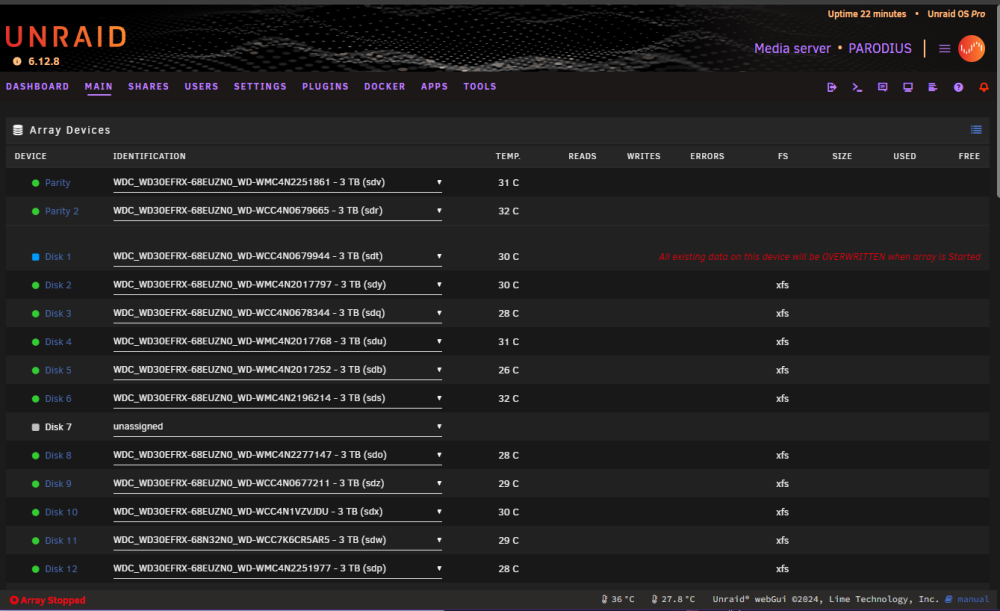
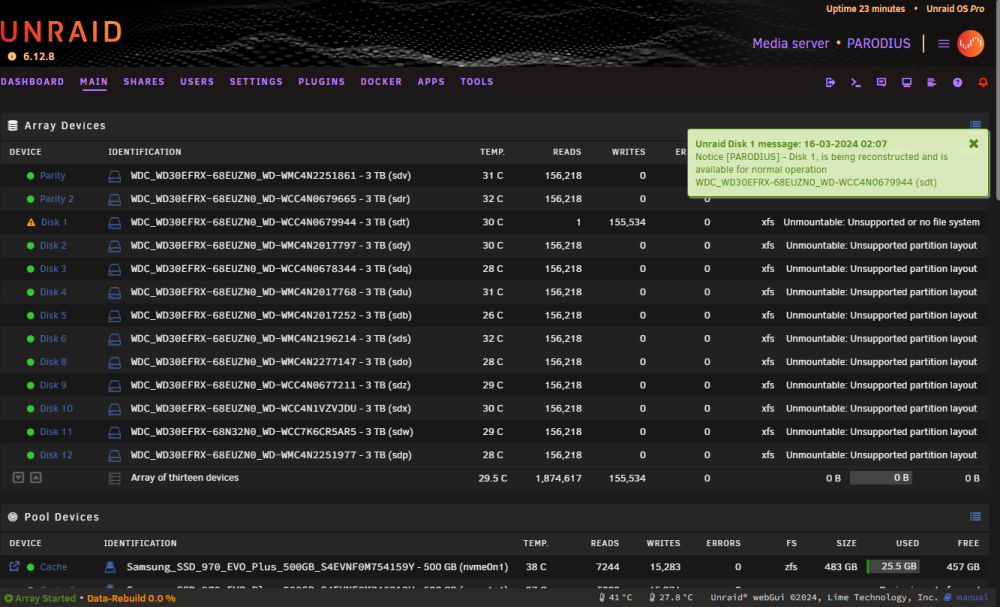
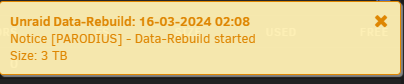

-
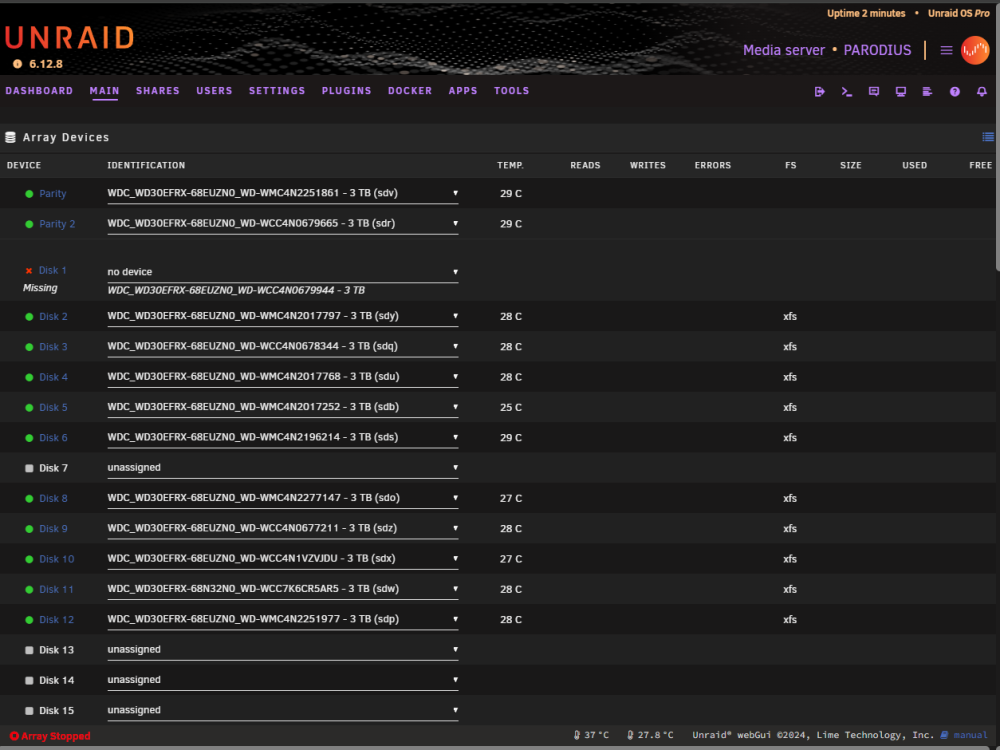
Ok. When the array is stopped, i mark 1 disk as no device ... ... On this way, i can't start the array, as its missing a disk. Note: disk7 is unassigned, but that was to replace a defective drive a few weeks (and reboots) ago. Note2: The Seagate 4TB drives are When i start the array with all the correct disks assigned: ... ... It wants me to format the WDC drives, ofcourse not doing so, as it contains data i would love to get it back.

-
Yea, i think as well something have to do with the expander, because that's the only component that was really changed. I have swapped disks in the past between direct to controller and expanders, never had such issue, although that was on HW raid. To my knowledge, expanders are just SAS switches, they don't do anything with data on drives. Unless this was a problem that started before the HW changes, and came up on the next boot, coincidentally after i moved to a new chassis. Tried to unassign one disk, but it wont allow me to start the array due Missing disk, or do i need to remove the drive physically ?

-
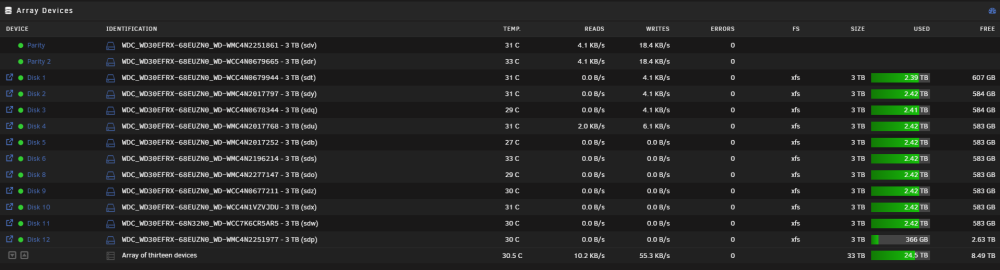
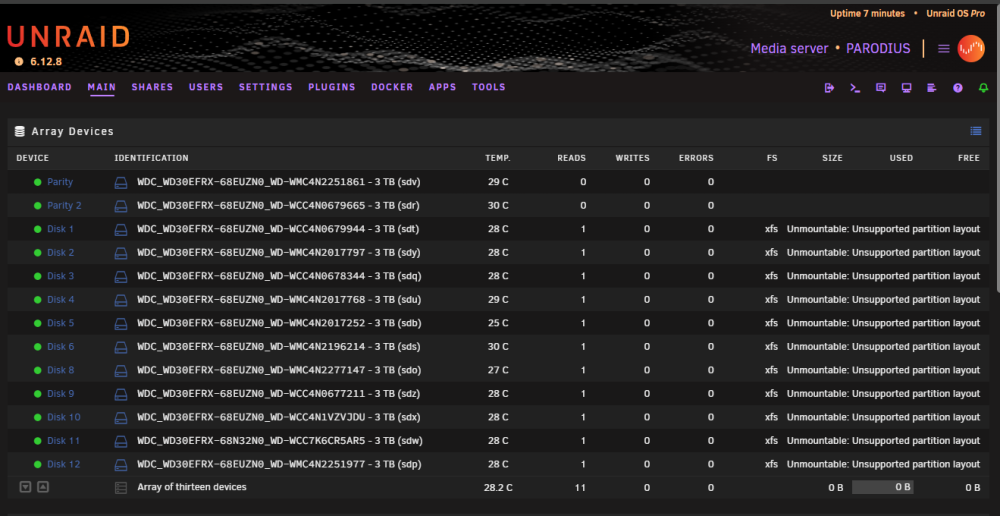
Seems i'm about having a bad weekend. As i decided to overhaul my tower build server to a rackmount Supermicro 36 slot SAS chassis, so i can add more disks. On my first startup, all my array drives got the status unmountable: Unsupported partition layout. All drives were XFS before this happened. I have no clue why this happened. I didn't change the mainbord or controller, it was a 1 to 1 transfer of all hardware into a new case, and added some disks (not formatted yet). The only difference is, before i used 3 mini-sas to 4 SATA cables to connect my harddrives, now i'm using a single SAS cable to the chassis expander. This shouldn't make that much of a difference ? Disks not having SMART errors, and are recognised by unraid. In maintenance mode, i click on a random disk, to perform a xfs repair, using the default -n option. This is the output: Phase 1 - find and verify superblock... bad primary superblock - bad magic number !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... would write modified primary superblock Primary superblock would have been modified. Cannot proceed further in no_modify mode. Exiting now. Any clues what happened, and more importantly, can this be fixed without loosing the data ? I've read something about running xfs_repair -V on each disk, but before doing that, wanted to consult this forum first In my diag file, you will also see 12 Seagate disks, those are new and unrelated to the array. I already tried to boot without those new disks, it made no difference. parodius-diagnostics-20240315-2035.zip
-
I have 2 internet lines, 1 i use for everything, the other just to download from one specific host. On my old Debian server, it was a simple and easy setup. 2 Physical network interfaces, ETH0 was getting IP address 192.168.8.x from DHCP, ETH1 had a manual IP address, 172.16.1.100 and not filled in any GW on this interface. (GW is 172.16.1.254) So i made a static route for this specific host (in example) 1.2.3.4, just by editing the network script in something that is similar to route add 1.2.3.4/32 via 172.16.1.254 dev eth1 This worked fine for years. Now in Unraid, im trying to re-create the same setup, by using it's CLI. So what i did. In the Network settings: ETH0, gets DHCP IP address within 192.168.8.x range, ETH1 have a manual IP address, 172.16.1.101 and not filling in any GW for this interface. Then at static route, i create 172.16.1.0/24 and put ETH1 in the second box, leave the metric at default, witch is 1. Then i add a second static route, 1.2.3.4/32 and on second box 172.16.1.254, metric also on default 1. This does not seem working. I can't ping the dedicated host for ETH1. When i remove both my static routes, it pings again, but obviously on ETH0. It's most likely an user error, but what I'm doing wrong here ?
-
Thank you very much @JorgeB👍
-
Ah my apologies, i just realised, in my test-setup i used 2 DC SAS3 SSD's as parity disk. In the final setup, they will be HDD's indeed. So building parity afterwards does seems like a good idea now My plan to connect the new drives to old server, booting Unraid, use a plug-in to read the current old EXT4 volumes and copy them all to the new Unraid array, would that be the best solution for my situation ? Or will i be better off buying 2 10GBe NIC's and transfer it all over network ?
-
Ah ok. I was planning to do the initial setup and migration with parity already build. In my test build, running latest Unraid, i had filled a nvme (cache) drive containing 50 10GB testfiles, and did a multithreaded copy to an 6+2p disk array with "Most Free" setting enabled. I saw all drives being used at ~125MB/sec each, what did look very promising to me. Doing parity afterwards, that will keep the array unprotected for several days i assume ?















