




EcN
Members
-
Joined
-
Last visited
-
Any solution to map ONLY /seafile/seafile/conf and /seafile/seafile/logs to point them to cache only?
-
If I switch to array -> cache, wouldn't my media files also end up in cache? I just want the logs to go to cache since it's being accessed so often. I just wish seafile had its logs in the appdata instead of the same directory as storing media files as well.
-
I was able to spin up seafile-12, but it's spinning up my drive constantly. Is there a way to map that particular directory to cache from unraid's docker settings? I was able to do this with frigate, but frigate's directory tree was much simpler. If I were to do the same method with seafile, I'd have to clutter up the shares. If /seafile is already mapped, would there be a conflict if I added another mapping of: /seafile/seafile/conf and /seafile/seafile/logs and point them to stay in cache? Side question, does another service like nextcloud respect hdd activity and spin down when not in use?
-
Crashed again around 14:37. Attached logs. syslog-10.0.1.61.log
-
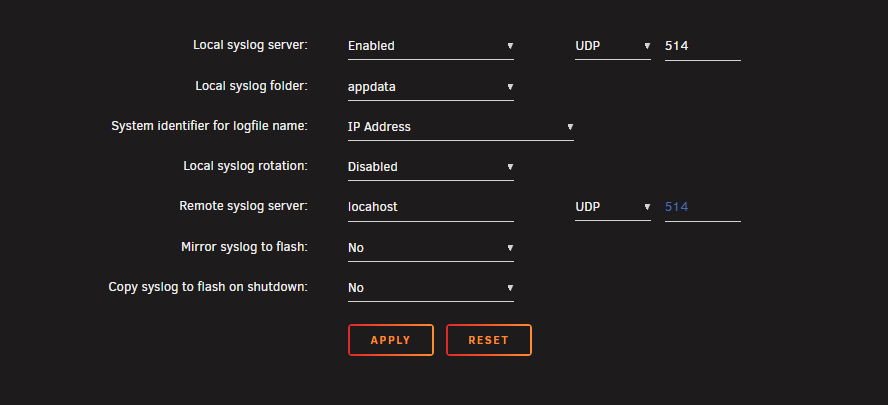
Yes that was my flashdrive. Oh so I didn't properly set up the syslog server? So set the server to localhost like this? (I've also turned off copy syslog to flash on shutdown) Would I go back and look in the appdata folder after the next time it crashes? Or just download diagnostics as normal?
-
After screenshotting my syslog settings, I noticed it said "copy syslog to flash on shutdown" is set to yes. I recall this time around I was able to gracefully shutdown via proxmox. I checked my flashdrive and looks like it does have logs right before the crash. I've attached it here. Side question: Should that setting be enabled? I noticed all my diagnostics are saved here: https://imgur.com/a/qFVfVJk syslog-previous
-
Here you go: https://imgur.com/a/ooTbeje I understand virtualizing is not supported and I'll keep that in mind and we can chalk it up to a virtualization issue in the end. I do want to exhaust all my options first and give as much logs/data as possible to see what troubleshooting can be done. I do plan to run bare metal eventually, but not for several months.
-
Unraid crashed again at 5:58am. got the syslog, but there isn't much in it? I had it save in appdata. Did I miss a setting to capture more data in that log? I've added grafana logs if anyone can understand it more than me: https://imgur.com/a/dHh4ava syslog-127.0.0.1.log ec-unraid-diagnostics-20250513-0731.zip
-
Crashed 10 min ago. Some context it may be totally unrelated, but the random crashing started when I added an old 1tb HDD in. It's not on the array, doesn't hold any system apps, only frigate. I previously had frigate on an SSD, but I was running out of space so I decided to let the HDD hold the bulk data via mover. Here's smart for the old hdd. Anyways, at random times, unraid would crash and I'd have to force shut down and start again. Happens every few days, no pattern, different times of day. Can a bad HDD not even holding any system app data and not on the array cause unraid to crash? Around the same time I noticed that my btrfs cache pool was getting errors, but I've since switched to zfs pool and has no error. I've also ran memtest overnight and passed with 2+ passes. At this point I'm at a loss. I installed grafana to watch my ram and cpu, but right before the crash, there was no change. No cpu spiking, no ram building up. I'm still working on figuring out how to capture data on each docker container. ec-unraid-diagnostics-20250509-2249.zip
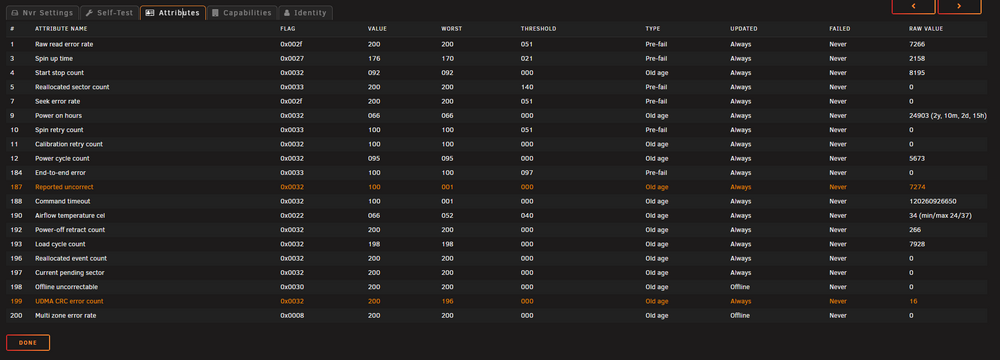
-
Memtest passed with 2 passes. Ended up changing to zfs instead on the 2 nvme's and I don't see any disk errors or io delay anymore.
-
If memtest is fine with multiple passes, what do you suggest be done next? Can I just format the drives and set up btrfs again? Use zfs instead? I just store cache, docker img, and system apps.
-
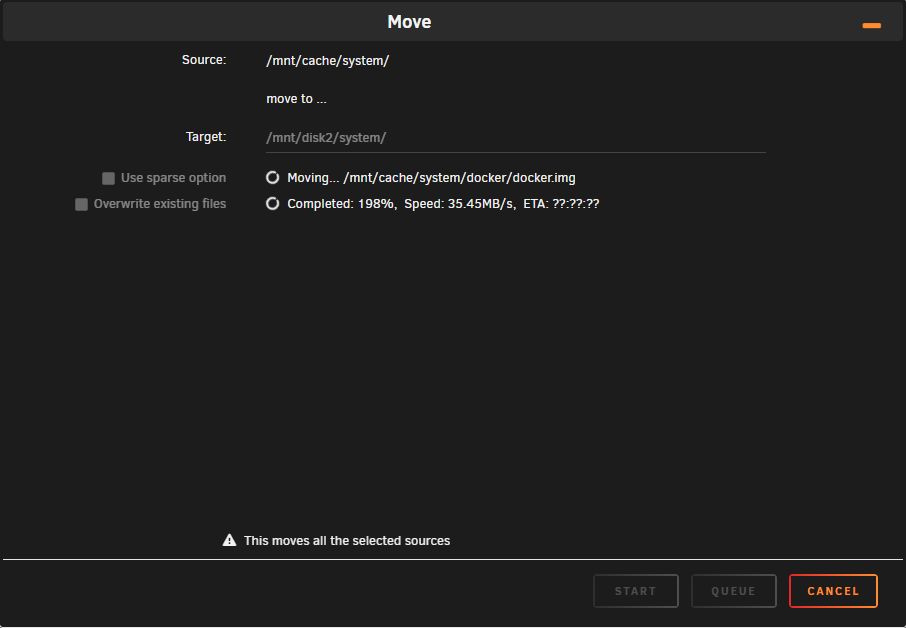
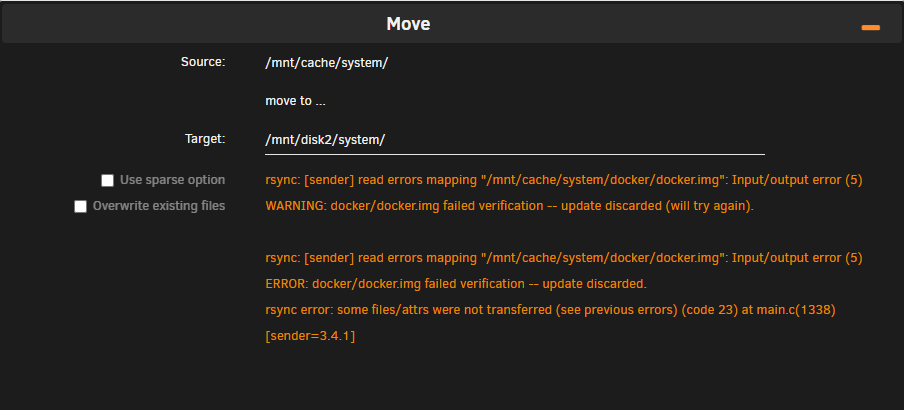
It looks like 006A has gone bad (actually I don't know which one) and not sure how to proceed from here. I'm trying to move system and appdata out currently, but it's hanging. What's the proper procedure to proceed? Should I be trying to drop the pool to 1 drive? ec-unraid-diagnostics-20250430-1130.zip


-
diagnostics attached ec-unraid-diagnostics-20250429-1413.zip
-
Context: Unraid VM via proxmox. I actually don't access my drive via smb often, but when I did it this time I was transferring a small amount of files, under 200MB. Then I noticed I wasn't able to access it anymore. I checked the unraid console and this is the last messages: link Any idea what happened? The spike in the end is after I had to stop unraid and spin it back up. I think I may just ditch smb/nfs and use some storage service like seafile/owncloud.
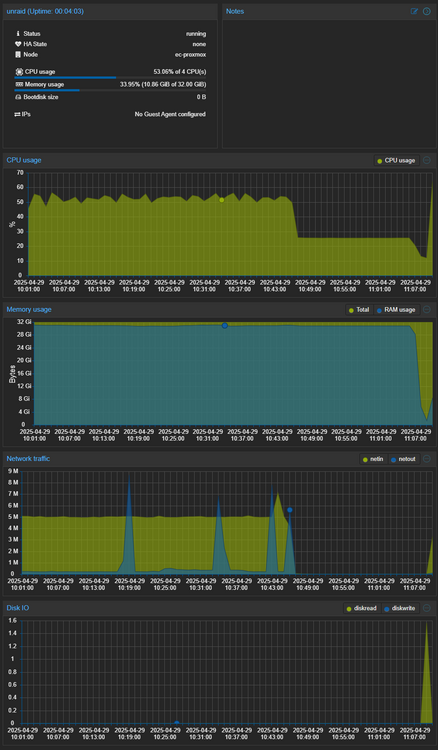
-
Removing mover tuning plugin fixed it for me. Did anyone re-install it? I don't think I was really using it.






