Mesias
Members
-
Joined
-
Last visited
Everything posted by Mesias
-
Thank you @JorgeB for your feedback and I'm sorry for the confusion.
-
Yes, just pre-clearing the device crashed the server. It turned the system unresponsive, same symptoms I've described before. No web access, no network access, nothing works.
-
Any heavy disk I/O is causing the crash... Based on the symptoms, what are the chances of this being a software issue and not hardware-related?
-
I added an unassigned SSD and the pre-clear process crashed it again... all this while the SABnzbd container is stopped. I don't know what to think anymore... I'd hate to spend on new hardware if this continues happening. Are there any other logs I can enable?
-
I was able to narrow it down to the SABnzbd container. It was in the process of repairing a large movie file and it seems to be causing the crash. There is no information in the SABnzbd logs or in syslog... I can see the intense CPU usage but nothing in the logs. I was reading around and I found a couple of interesting options to solve this: 1. ZFS cache drive vs BTRFS. My cache drive is currently on BTRFS but all other drives under the array are on XFS. Should I change the cache drive to match the rest of the drives? 2. SABnzbd hogging resources when the downloads are in the same drive as the appdata. Some people recommend having the downloads folders for the *arrs in a separate unassigned drive. Are these potentially viable solutions? Are you guys aware of any other option?
-
After a couple of days of uptime, I turned on the Docker service and, after a few minutes, it crashed. Here is the syslog from the bootup on 06/06 up to this last crash. I appreciate your help. syslog-MESIASUNRAID_20240606-0609.zip
-
Well, after canceling the parity check the system hasn't crashed. I notice now the shares are not visible in the network. I can still access them based on mapped drives through Windows but I can't see them in Explorer. Very odd... attached the syslog. This log should have everything since 2022. syslog-MESIASUNRAID.zip
-
I reboot it agan but cancelled the parity check. It's been 9 hours... Let's see tomorrow.
-
There is no error in the syslog. I think the diagnostics download includes it. I can only find multiple instances of these lines: Jun 5 17:51:20 MESIASUNRAID rsyslogd: action 'action-3-builtin:omfwd' resumed (module 'builtin:omfwd') [v8.2102.0 try https://www.rsyslog.com/e/2359 ] Jun 5 17:51:20 MESIASUNRAID rsyslogd: omfwd/udp: socket 2: sendto() error: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Jun 5 17:51:20 MESIASUNRAID rsyslogd: omfwd: socket 2: error 101 sending via udp: Network is unreachable [v8.2102.0 try https://www.rsyslog.com/e/2354 ] Jun 5 17:51:20 MESIASUNRAID rsyslogd: action 'action-3-builtin:omfwd' suspended (module 'builtin:omfwd'), retry 0. There should be messages before this one giving the reason for suspension. [v8.2102.0 try https://www.rsyslog.com/e/2007 ]
-
Yeah, that's what i did last night to find the server unresponsive again this morning. I'm back to square one.
-
Hey all, For a very long while, around three years or so, I've been dealing with Unraid hanging on me every time the parity check starts. After four or five minutes, the system would just hang, including all services. Thinking this was a hardware issue I've switched around pretty much all components to no positive result. More recently, the box started hanging randomly, not just after the monthly parity check started. There are no traces in syslog that could point me to what's going on. During these last two events, I noticed that the Docker service didn't start with the system booting. After a few minutes of starting the service manually, the box hangs. Today, just a few minutes ago, I started the machine to get the diagnostics file and again the Docker service didn't start automatically as it was supposed to. This time around I left it off and the system is still doing the parity check without problems. Even though I still have no clue what's happening, it's pointing to the Docker service or a particular docker and not a hardware issue. Would you be able to help me troubleshoot this further? I'm attaching the diagnostics file from this last boot-up. Thank you in advance! unraid-diagnostics-20240605-1800.zip
-
Hi there, I posted the problem I'm facing on the Unraid general support but I received no replies. I'm hoping I can get some feedback here. I changed from Letsencrypt to Swag recently and after the change i lose access to multiple sections in Unraid and all dockers stop functioning properly... I lose access thru the UI to the Dashboard, Docker and the bottom portion of the Main tab. The console gets unresponsive to any docker command and to the "powerdown" capability so every time I restart the system it has to do a parity check. Of course none of the apps using the reverse proxy are working to the outside. The migration was based on a fresh installation and I just copied the conf files from Letsecrypt. The Unraid logs show the following error (it varies depending on the page I'm trying): nginx: 2020/10/12 10:06:48 [error] 32315#32315: *246154 upstream timed out (110: Connection timed out) while reading response header from upstream, client ... upstream: "fastcgi://unix:/var/run/php5-fpm.sock" ... Any suggestion would be greatly appreciated. Please help!
-
I initially made a huge bulk import... all releases are in their folders. Clearing the queue definitely resolved the issue. I went to the Queue tab in the Activity screen and delete all from download client. Now the logs are clean of import service errors. Thanks again for all the assistance!
-
That didn't help... The import service is looking for versions never downloaded... all releases in both libraries (Radaar and Sonaar) are flagged "downloaded". I'm stuck, I don't understand yet the process of importing. Why, if a release is already flagged as downloaded, the import service continues trying to retrieve it from the download folder?
-
That's exactly what's happening... I tried a fresh request and it worked just fine. On the other hand, Sonaar and Radarr are still looking for releases already downloaded. Not sure how to clear that queue. Thanks for all the help!
-
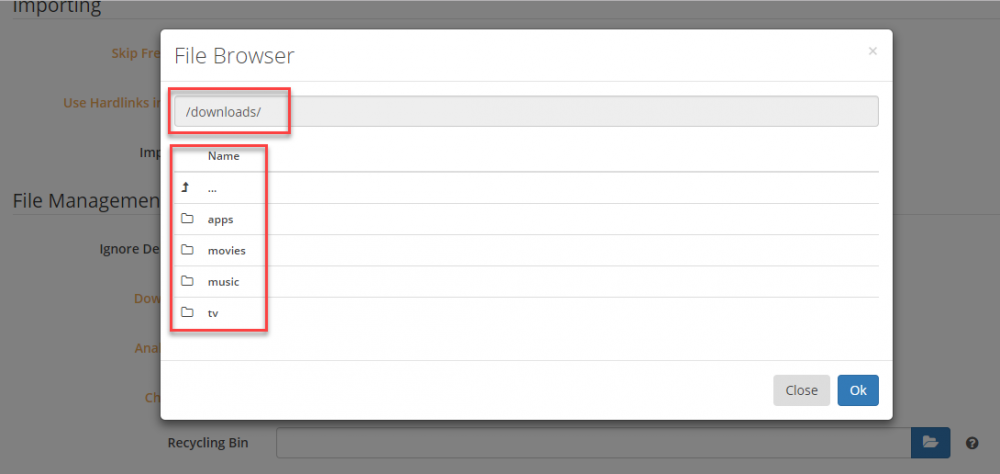
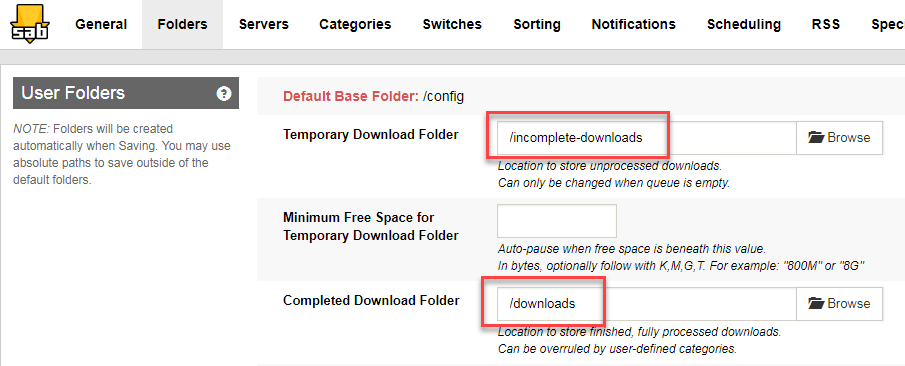
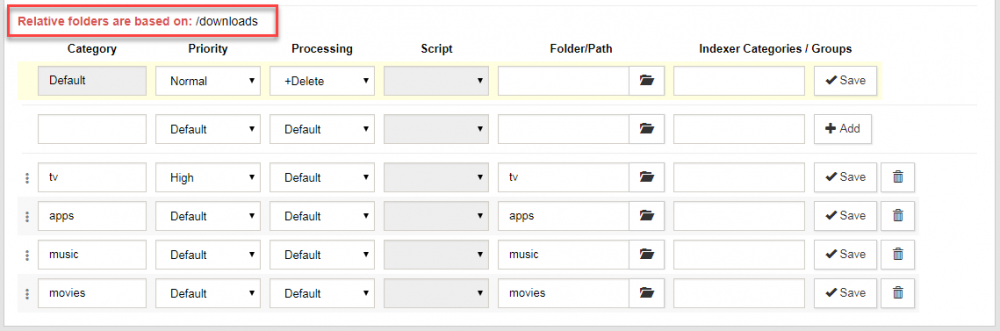
I changed the path to the Sabnzbd categories and it didn't help. I then changed its download folders to absolute paths but it didn't resolve the issue. Logs continue showing the default path. Note I restarted all three dockers. Screenshot to User Folders in Sabnzbd: Previous step changed the path for the categories folders. They are now relative to /downloads: After all this, the logs keep showing the default path: Is there any other log I can enable that can provide more info?


-
I'm going to try changing the path of Sabnzbd categories to absolute paths. Right now they are using the default, relative folders are based on: /config/Downloads/complete. This should fix it... Thanks for pointing this out!
-
I posted this in Radaar and Sonaar support forums but it looks to me this is a Docker issue... Something is off and I can't find where the issue lies... Radarr and Sonarr are not looking for the downloads folder in the correct path. Sonarr log message: Import failed, path does not exist or is not accessible by Sonarr: /config/Downloads/complete/tv/ Radarr log message: Import failed, path does not exist or is not accessible by Radarr: /config/Downloads/complete/movies/ For some reason Raddar and Sonnar are looking under the config folder instead of the path defined for the downloads folder. Here are the details of my setup: Both Sabnzbd and Radarr are installed dockers in an UNRAID box Sabnzbd path to downloads folder as defined in the docker: /downloads -> /mnt/user/appdata/sabnzbd/Downloads/complete/ Raddar path to downloads folder as defined in the docker: /downloads -> /mnt/user/appdata/sabnzbd/Downloads/complete/ Host for Sabnzbd in Raddar is the local IP address, "localhost" didn't work Permissions for completed downloads under Sabnzbd: 775 File chmod mask in Raddar: 0775 Any file browser within Raddar is able to see the correct downloads folder Screenshot of Docker settings: Screenshot of a file browser window within Sonarr showing it can see the /downloads folder and its content: Any idea where to look? Radarr Version: Version: 0.2.0.870 Mono Version: 5.4.1.6 (tarball Wed Nov 8 20:37:08 UTC 2017) AppData directory: /config Startup directory: /opt/radarr Sonarr Version: Version: 2.0.0.5085 Mono Version: 5.4.1.6 AppData directory: /config Startup directory: /opt/NzbDrone