

Koperfild
-
Posts
86 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Koperfild
-
-
45 minutes ago, johnnie.black said:
Do you have notifications enable? You should have noticed those issues before they were on so many disks.
Unfortunately not. Do you think that all disks except the secon one should be replaced? How high number for "reported uncorrect" is bad?
So it seems i can't make sure the files are OK. Some of them may probably be bit-rootten?
I think i will replace faulty drives and create new setup using btrfs...
-
Hi, my server has been running over 8 years without any big issues. Now the disks seem tired of. Ther SMART reports don't look good on four of the six drives. Have a look please.
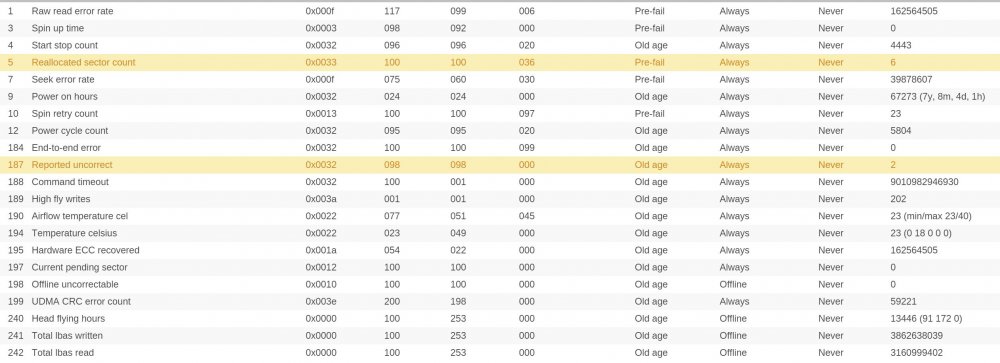
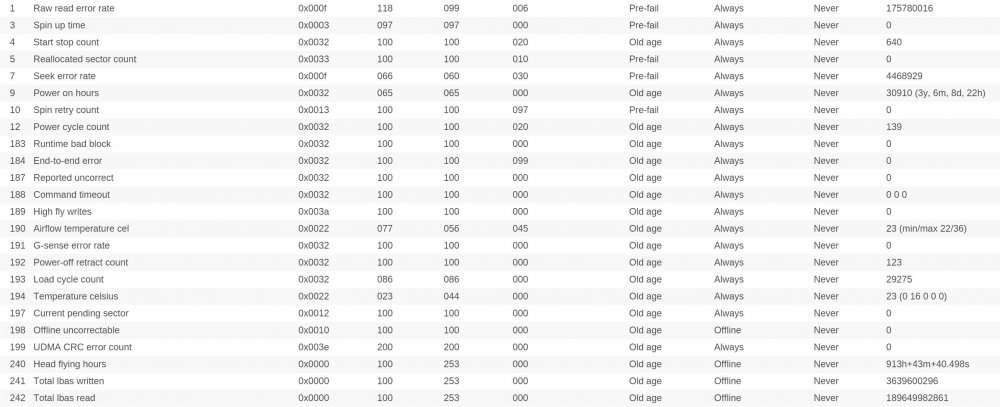
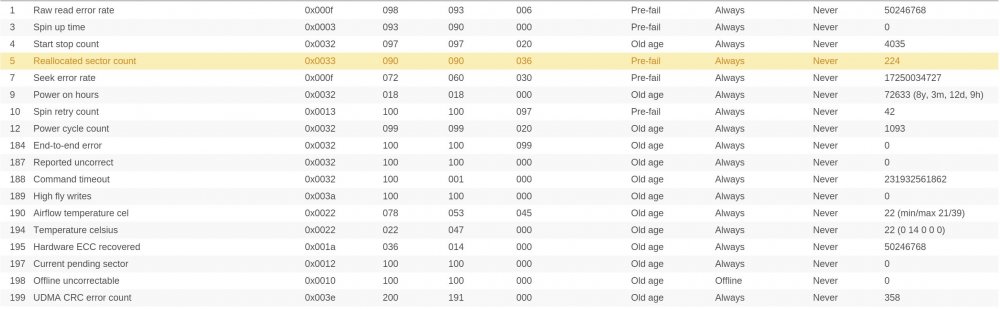
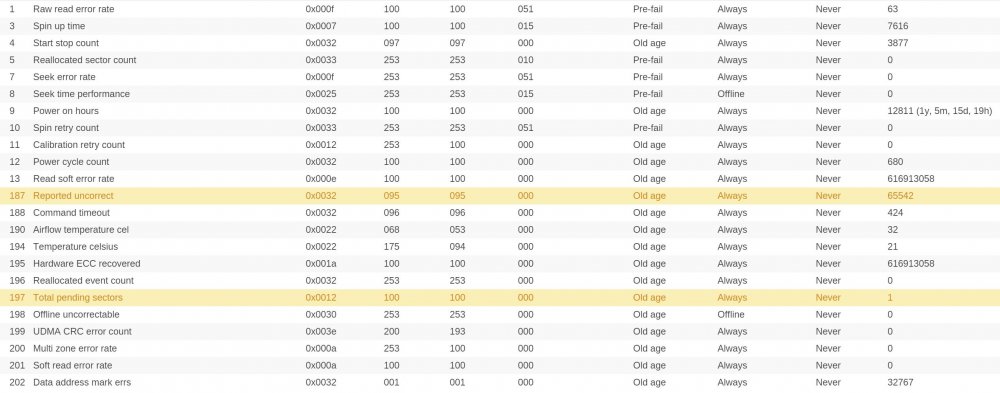
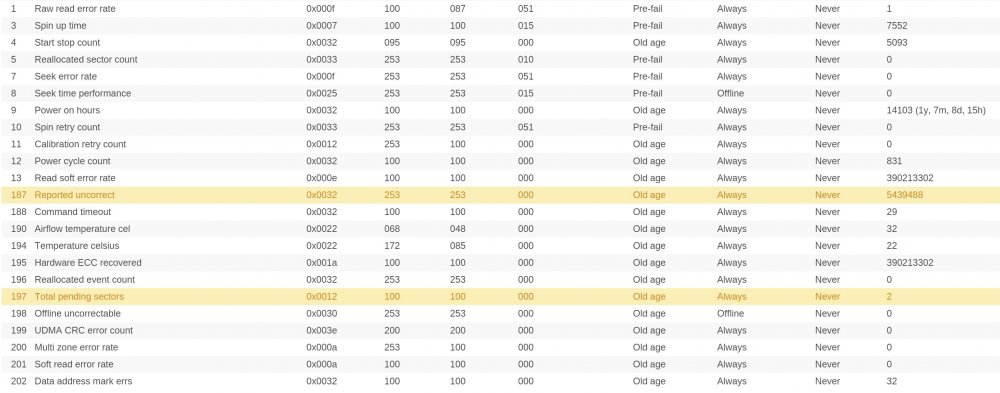
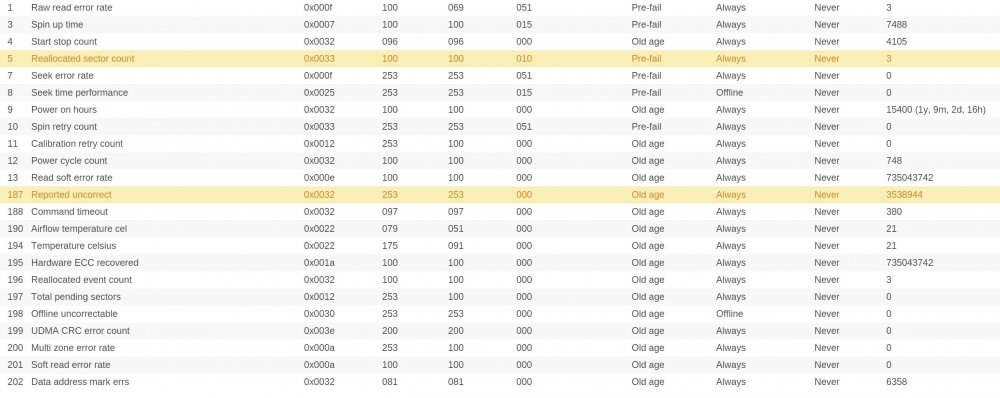
Now, the problem arised, becaused sync errors started to show up. They are here every time when i run parity check. Last time it completed with 100 of errors, earlier with 26 errors etc.

I ran reiserfsck on filesystems. Only one drive had problem, but was fixed using fix-fixable option. I know i have to replace faulty drives (with high allocated sector number, or report uncorrect number). I just have one question. How can i be sure that all of my files are OK if there are constantly sync errors. Is it even possible?
-
Smart report is OK. Nothing special in syslog. I tried to repair filesystem, but any reiserfsck command fails. What is interesting is that i cannot perform reiserfsck --check on any heatlhy disc, because it says that superblock is not found, even when the disc is properly mounted by unraid. Why is that? How can I rebuild the superblock on that failed disc (i mean what are the parameters)?
-
The rebuild has ended, the drive shows as unformatted. Possibly because some parity codes were messed. What should i do now?
-
I did as you suggested Webo, and everything would be fine but the parity check started even when i had ticked "parity is already valid"!!! This corrected 326 "errors" ony my parity drive. Thankfully i stopped it soon after that. So i think some files will be broken now. What should I do when the disk gets fully rebuilt?
-
I cant do anything with the failed drive. It doesnt even fully spin up. Looks like the bearing is destroyed.
Do you know how to make the array trust that it is correct and then se the replaced disk as invalid?
-
Hi, I'm back after three years of inactivity.
Something extremely bad happened to my
 (
(One of my disks failed today. I replaced it instantly with a new one. On the beginning of data rebuild a lot of errors appeared on another drive. Like i found later it was a problem with my case or Sata cable (most probably). I replaced the sata tape and reboot server. Now my disk which had been replaced is orange (indicates interrupted data rebuild) and the other one is blue. What can I do to make unraid know that the blue-one is actually a proper disk, and make it rebuild the new one??
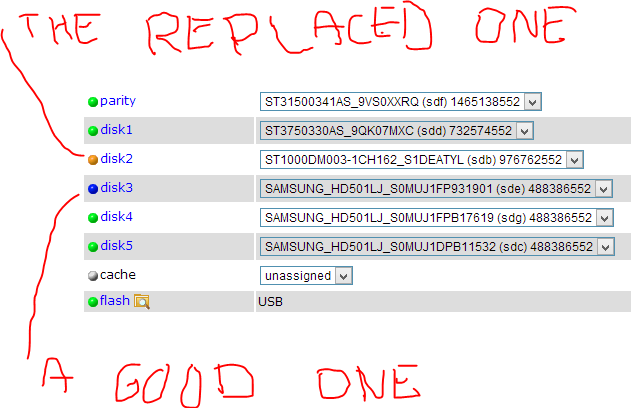
-
Hello!
I'm managing an unraid server over a year in a small company.
We decided to upgrade to 5.0-beta13, because in 4.7 we got a weird problem when adding new permisions (the list of users and shares has over 40 records). After adding new user or assigning new permissions emhttp went "Segfault error". Now, after upgrade I received the same error.
Syslog attached below:
-
After upgrading I cant see any file. It got fixed after I have set chmod to 777 for all files. What is the correct chmod setting?
-
When i try to add a torrent file it loads correctly but then, the whole interface freezes for some time and the torrent doesnt download at all.
How are you adding torrents? By dropping the links in the "auto" folder? Or from within the rtorrent screen? Or from the rutorrent web page?
Then what freezes? rtorrent or rutorrent?
I add it from the rutorrent web page and the downloading doesn't start. By freezing i mean that it sometimes takes very long time to load the gui after an action. I also receive that error occasionally
Bad response: (500) <?xml version="1.0" encoding="iso-8859-1"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head> <title>500 - Internal Server Error</title> </head> <body> <h1>500 - Internal Server Error</h1> </body> </html>
No torrent ever starts to download, though the same one works fine in a client on my pc.
-
When i try to add a torrent file it loads correctly but then, the whole interface freezes for some time and the torrent doesnt download at all. When i type rtorrent in the console it outputs "root@Tower:~# Error in option file: ~/.rtorrent.rc:17: Could not prepare socket for listening: Address already in use".
What should i do?
-
Well, it seems that I have found the solution
 And it takes about one minute to enable the recycle bin or whatever to call it. It doesn't work on file system level so deletions performed from console or other protocol (NFS) are still permanent, however when it comes to samba it works like a charm.
And it takes about one minute to enable the recycle bin or whatever to call it. It doesn't work on file system level so deletions performed from console or other protocol (NFS) are still permanent, however when it comes to samba it works like a charm. Like I wrote in the first post the only problem is caused by the way that unraid creates config files. Those files are created by an inner script so the user can't have full control of samba configuration, however we can create an smb-extra.conf file.
The workaround is to add a share in the top of the document before setting the recycle bin to [global]. This seems to be working even though the [recycle bin] share lines would overlap. So this is how my smb-extra.conf file looks like:
[bIN] path = /mnt/user/BIN read only = No [global] vfs objects = recycle recycle:repository = /mnt/user/BIN/%m recycle:keeptree = Yes recycle:touch = Yes recycle:versions = Yes recycle:exclude = *.tmp recycle:exclude_dir = /tmp recycle:noversions = *.doc
These setting create a new share called BIN which is split among(?)not sure about the expression:P the disks in our server. Any file deleted from any location will be placed there and remain until you delete it again (aka empty the recycle bin). Be careful! You can't empty the recycle bin by entering into it's folder through a disk share - it will be placed in the same folder again and again (vicious circle).
I attach some possible configurations of the vfs object
recycle:repository = PATHPath of the directory where deleted files should be moved.
If this option is not set, the default path .recycle is used.
recycle:directory_mode = MODE
Set MODE to the octal mode the recycle repository should be created with. The recycle repository will be created when first file is deleted. If recycle:subdir_mode is not set, MODE also applies to subdirectories.
If this option is not set, the default mode 0700 is used.
recycle:subdir_mode = MODE
Set MODE to the octal mode with which sub directories of the recycle repository should be created.
If this option is not set, subdirectories will be created with the mode from recycle:directory_mode.
recycle:keeptree = BOOL
Specifies whether the directory structure should be preserved or whether the files in a directory that is being deleted should be kept separately in the repository.
recycle:versions = BOOL
If this option is True, two files with the same name that are deleted will both be kept in the repository. Newer deleted versions of a file will be called "Copy #x of filename".
recycle:touch = BOOL
Specifies whether a file's access date should be updated when the file is moved to the repository.
recycle:touch_mtime = BOOL
Specifies whether a file's last modified date should be updated when the file is moved to the repository.
recycle:minsize = BYTES
Files that are smaller than the number of bytes specified by this parameter will not be put into the repository.
recycle:maxsize = BYTES
Files that are larger than the number of bytes specified by this parameter will not be put into the repository.
recycle:exclude = LIST
List of files that should not be put into the repository when deleted, but deleted in the normal way. Wildcards such as * and ? are supported.
recycle:exclude_dir = LIST
List of directories whose files should not be put into the repository when deleted, but deleted in the normal way. Wildcards such as * and ? are supported.
recycle:noversions = LIST
Specifies a list of paths (wildcards such as * and ? are supported) for which no versioning should be used. Only useful when recycle:versions is enabled.
And here is the document about possible smb.conf configurations (enviromental variables is what you'll look for in there
 )
)http://www.samba.org/samba/docs/man/manpages-3/smb.conf.5.html
Regards!
-
Hi,
I was skimming through the forum looking for a recycle bin solution for unraid an I've found one which is actually already in unraid - vfs_recycle. All that needs to be done is to add some lines of code in the config file. The only problem is that there is no direct access to the smb.conf so the only thing I could do was to create smb-extra.conf file and apply a [global] configuration there, which refereed to every share. The problem in such a case is that the [global] configuration covers the recycle bin share too and it is a vicious circle (you can not delete anything from the recycle bin).
I also tried to apply vfs_recycle settings per-share, but it didn't work I guess share configuration cannot be split in two lines like that:
[Multimedia]
(...)
[Multimedia]
(...)
I need a solution for that or a workaround.
Strange is that Tom has not yet implemented the feature officially. It's easy, and a lot of people are looking forward to seeing that.
-
Thanks for your answears prostuff. Can you help me with this issue? It is the major question now:
"If you log to the server as someone who's got limited privileges and want to re-log, how can you do this without unloging from windows (it remembers the session and doesn't ask another time for username when you access a share)?"
-
Active Directory support has been added to unRAID so you probably want to read up on that.
I know, but the computers do not belong to any domain and there is no windows server in the company. As far as I know unraid does not intagrate AD server. It acts as a client. Am I right?
-
Hi,
some time ago I built an unraid-based file server for a small company, which consisted that time of three people. Now, it has grown bigger and the executive demanded new features. Instead of simple sharing of disk1 he wants password-secured shares with ability to trace activity on them. I tried to figure out how to do that tracing, but i don't have such an experience in UNIX. Can you help me?
Having written this topic I'd like to ask some questions.
If you log to the server as someone who's got limited privileges and want to re-log, how can you do this without unloging from windows (it remembers the session and doesn't ask another time for username when you access a share)?
Is there any way you can manage object's privileges from within windows computer? When I open 'properties' of an object located on unraid server and try to change privileges it doesn't work. They seem incompatible.
-
I've bought some gigabyte yellow cables (lockable as you recommended)

and replaced with the old ones

Now I'm trying to load the server as much as possible. I make 300gb's of data from various disks go around my home network (download and upload to the server) and run parity checks repeatedly. We'll see the result.
-
The temperatures are shurely fine. I placed the motherboard on a sound foam now and directed two 120mm to flow on it. I will buy new cables. Do you think that these will be ok: http://allegro.pl/item635734847_kabel_dla_koneserow_sata_chieftec_katowy_do_dysk.html ?
And what if replacing cables doesnt help?
-
My server failed for the first time like that about 2 months ago. Everything worked fine until tons of errors popped up on one of the disks. What was interesting was that the disks appeared to be OK tested with mhdd, and passed the smart test so i remounted it and rebuilt the data. Since the time i started to experience such a behaviour repeatedly. It happened very irregularly sometimes few times a week, sometimes not at all. First thing i thought it might have been was the PSU (Be Quiet 450W) so i swapped it with Corsair 450W (which has one 12v rail) but it didn't change anything. Then i decided to rewire the server and neither did it help. Couple of days ago i, fed up with the problem, put all the parts out of the case, placed on the table, cabled, updated the bios and run initial configuration of unraid 4.5-beta6. Everything seemed to be OK for 48 hours of running high-loaded (parity checks, file movements, reboots) and then it failed again.
I have no idea what may cause the server fail. I used all my experience and have done any test i know and i haven't found the answer.
I checked voltages, temperatures, memory. I tried changing disks' order. I tried variety of sata configuration - AHCI, IDE Enhanced, IDE Compatible, as well as many unraid distro's - 4.3.3, 4.4.2, 4.5-beta4 and 6. It didn't change a thing.
I attach syslog after a failure and current smart reports:
-
Hi,
I've got Asus P5E-VM Do motherboard with ICH9R chipset. Is there any way I can disable staggered spin up feature or is it up to the PSU? The time needed to spin the disks up one by one becames very annoying since the quantity of disks exceeded 6.
-
Besides the problem i wrote about here - http://lime-technology.com/forum/index.php?topic=3114.msg26053#msg26053 there is something else i consider a bug. When the array is stopped and the disks are spun down and you try to start the array it will show some of disks unformatted (i guess it won't manage to spin them up in time and think the filesystem is broken).
-
I think it's not just a case, because i started to experience red-balls since i updated to 4.4.2 too. In syslog it looks like this:
Jan 16 00:43:13 Tower kernel: ata5: hard resetting link Jan 16 00:43:13 Tower kernel: ata5: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Jan 16 00:43:13 Tower kernel: ata5.00: configured for UDMA/33 Jan 16 00:43:13 Tower kernel: ata5: EH complete Jan 16 00:43:13 Tower kernel: sd 5:0:0:0: [sdd] 976773168 512-byte hardware sectors (500108 MB) Jan 16 00:43:13 Tower kernel: sd 5:0:0:0: [sdd] Write Protect is off Jan 16 00:43:13 Tower kernel: sd 5:0:0:0: [sdd] Mode Sense: 00 3a 00 00 Jan 16 00:43:13 Tower kernel: sd 5:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Jan 16 00:43:13 Tower kernel: ata5.00: exception Emask 0x10 SAct 0x5f SErr 0x400100 action 0x6 frozen Jan 16 00:43:13 Tower kernel: ata5.00: irq_stat 0x08000000, interface fatal error Jan 16 00:43:13 Tower kernel: ata5: SError: { UnrecovData Handshk } Jan 16 00:43:13 Tower kernel: ata5.00: cmd 60/f8:00:ff:d8:bd/00:00:0a:00:00/40 tag 0 ncq 126976 in Jan 16 00:43:13 Tower kernel: res 40/00:34:7f:d8:bd/00:00:0a:00:00/40 Emask 0x10 (ATA bus error) Jan 16 00:43:13 Tower kernel: ata5.00: status: { DRDY } Jan 16 00:43:13 Tower kernel: ata5.00: cmd 60/08:08:9f:00:14/00:00:2e:00:00/40 tag 1 ncq 4096 in Jan 16 00:43:13 Tower kernel: res 40/00:34:7f:d8:bd/00:00:0a:00:00/40 Emask 0x10 (ATA bus error) Jan 16 00:43:13 Tower kernel: ata5.00: status: { DRDY } Jan 16 00:43:13 Tower kernel: ata5.00: cmd 60/08:10:e7:34:2d/00:00:0d:00:00/40 tag 2 ncq 4096 in Jan 16 00:43:13 Tower kernel: res 40/00:34:7f:d8:bd/00:00:0a:00:00/40 Emask 0x10 (ATA bus error) Jan 16 00:43:13 Tower kernel: ata5.00: status: { DRDY } Jan 16 00:43:13 Tower kernel: ata5.00: cmd 60/08:18:bf:28:00/00:00:00:00:00/40 tag 3 ncq 4096 in Jan 16 00:43:13 Tower kernel: res 40/00:34:7f:d8:bd/00:00:0a:00:00/40 Emask 0x10 (ATA bus error) Jan 16 00:43:13 Tower kernel: ata5.00: status: { DRDY } Jan 16 00:43:13 Tower kernel: ata5.00: cmd 61/30:20:4f:d6:bd/02:00:0a:00:00/40 tag 4 ncq 286720 out Jan 16 00:43:13 Tower kernel: res 40/00:34:7f:d8:bd/00:00:0a:00:00/40 Emask 0x10 (ATA bus error) Jan 16 00:43:13 Tower kernel: ata5.00: status: { DRDY } Jan 16 00:43:13 Tower kernel: ata5.00: cmd 60/80:30:7f:d8:bd/00:00:0a:00:00/40 tag 6 ncq 65536 in Jan 16 00:43:13 Tower kernel: res 40/00:34:7f:d8:bd/00:00:0a:00:00/40 Emask 0x10 (ATA bus error) Jan 16 00:43:13 Tower kernel: ata5.00: status: { DRDY }It results either in ATA bus error or in Timeouts and other issues that eventually cause a red ball on a random disk. It never took a place when i was using an older distro (i guess something is wrong with current kernel and ICH9R controller), though i'm thinking of re-wiring the whole server. Cables attached to my hot-spare bays dont seem to be well-made. Can you advise which cables are the best? (the shorter the better)
-
All the versions marked as stable are relatively stable
It's impossible to judge which one is the best. -
It works like a chain of updates. First you install full 0.7, then you upgrade to 0.8 and then to 0.9.










Bad smart readings, errors in sync...
in General Support (V5 and Older)
Posted
So i replaced disks, verified data with my backups and run into another problems ehhh Could you help me johnie? Because i can't figure out what went wrong. Btw can i buy you a coffe somehow?
Could you help me johnie? Because i can't figure out what went wrong. Btw can i buy you a coffe somehow?
I bought two brand new Seagate 2TB pipeline HDD and also used 1TB drive from my previous server because it was fine (according to SMART). I created new config and everything was fine for two days. Then i noticed REPORTED UNCORRECT flag on one of the new 2TB discs. I quickly bought another one and replaced the drive (also put new sata cable).
The new one started to produce the same errors very quickly. Just after data rebuild i run parity check and there were errors. Both REPORTED UNCORRECT and REALOCATED SECTORS flags were rising after each parity verification. unraid reported errors in the webgui (over 1400 errors). Today i tried to access server and... all the data from the drive was missing. I downloaded diagnostics, rebooted the server. The drive was shown as unmountable!
So i tried to mount it a few times, and when it didnt work i just disabled it. The problem is that even with disabled disc and emulated data. there is no data at all It's not yet a tragedy, because i have fresh backups, but i dont know what i did wrong. I don't want to repeat problems, so could you please look into my syslogs? The file named -1 is before reboot and -2 is after reboot.
It's not yet a tragedy, because i have fresh backups, but i dont know what i did wrong. I don't want to repeat problems, so could you please look into my syslogs? The file named -1 is before reboot and -2 is after reboot.
syslog-1.txt
syslog-2.txt