

dAigo
-
Posts
108 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by dAigo
-
-
4 hours ago, itimpi said:
I think this is a problem that only some people encounter? As far as I know everyone who tried the betas eventually got it working (unless they quietly rolled back to Stable without mentioning it) so it was not obvious that many users might encounter an issue?
Have you tried the suggested solution of disabling VT-D to see if it works for you?
I did not follow Betas or RCs, but from the Post that was linked on page 1, it looks, those that were effected changed controllers.
Disabling VTd is not an option for me, so it won't help.
I am not saying it should or can be fixed, but a note that this has happened so some people may be helpful.
And if you follow the link to the bugreport, it was changed to a specific controller.
It matches my controller and not those that have no issues.
summary: - amd_iommu conflict with Marvell Sata controller
+ amd_iommu conflict with Marvell 88SE9230 SATA Controller
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1810239
[1b4b:9230] 02:00.0 SATA controller: Marvell Technology Group Ltd. 88SE9230 PCIe SATA 6Gb/s Controller (rev 11)
3 hours ago, johnnie.black said:Marvell/VT-D issues are nothing new, see for example this thread, some users are more affected than others, it might get better or worse with any newer kernel, nothing that LT can fix directly, anyone than can afford to get them replaced with for example an LSI HBA should.
Yes, I knew that before I tried it. I had no issues until 6.7.0.
I don't mind, just feedback for those that might also have that exact model.
-
1 hour ago, calypsoSA said:
Also upgraded and missing drives all over due to the marvell issue. Never had a problem before.
Rolling back.
Should this not be noted as a breaking change, as I imagine many people are going to be in the same situation.
Same issue here, during boot it tried to access the drives but eventually gave up.
Havent tried anythig that could change something, like a diffrent PCI-Slot or ACS override.
Reroll worked.
Agree on having a note in this thread or the release notes.
It seems this is a known "potential" issue since RC and has not been fixed for those that are effected.
IOMMU group 1: [8086:1901] 00:01.0 PCI bridge: Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor PCIe Controller (x16) (rev 07)
[8086:1905] 00:01.1 PCI bridge: Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor PCIe Controller (x8) (rev 07)
[1b4b:9230] 02:00.0 SATA controller: Marvell Technology Group Ltd. 88SE9230 PCIe SATA 6Gb/s Controller (rev 11)
-
- VLAN and multiple Ethernet support
I am currently looking into vlans in unraid. I could not find any detailed discussion/explanation, so i'll ask here.
http://blog.davidvassallo.me/2012/05/05/kvm-brctl-in-linux-bringing-vlans-to-the-guests/
From what i can see, LT went the first route, because I can see multiple sub-interfaces on eth0 when enabling VLANs.
The difference is that when subinterfaces are defined on eth0, as noted previously Linux will strip the vlan tag, but when defined on the bridge, the vlan tags are kept. The vNICs are both members of the bridge, with the result that the tagged traffic is presented directly to them, with the VLAN tagging intact.So you could send tagged traffic out, but the returning traffic won't be tagged anymore and, unless defined as PVID/native vlan, therefore ignored by the application inside your VM.
If you need ONE inteface in your VM with MANY vlans you would need to add every br0.X interface to the VM and build a bridge in the VM. (packets still wouldn't be tagged)
IF kvm would be the main reason for adding/using vlan (in my case it is...) the second way would be far better.
I think you could still use br0.X if your vm can't handle vlans (windows vm...).
I was looking into pfsense, vmware and other "vlan-aware" applications, but from what I see, that won't work?
I am not sure what a change from the current system would mean for other vlan use-cases or even normal usage, maybe it could get changed without harm?
Could I still disable vlans in the gui and manually add vlans to the bridge, or does it actually disable any vlan-functionallity?
If it was already discussed, i missed the party, sry

I could open another thread if you want to keep the anouncement clean
-
I'm interpreting your results a little differently, and I could be wrong, but it looks like the report may have aborted in both cases, more obviously in the first case. From what I read, the symbol /dev/nvme0 is the broadcast address, for all devices associated with nvme0, and /dev/nvme0n1 is the specific device. That results in different report results.
Thats why I said "don't ask me why" it works
I am under the same impression as you are. Maybe its a smartmontools bug (experimental after all) but clearly nvm0 gives correct results in regard of the nvme-logs that are specified in the official specs.Currently the GUI ALWAYS states "Unavailable - disk must be spun up" under "Last SMART Results". But I am writng this on a vm thats running on the cache disk, so its NOT spun down. That also changed with nvm0, but the buttons for smart tests were still greyed out.
I am not sure, that nvme devices even works the same as old devices. It was designed for flash memory, so most of the old SMART mechanics are useless, because sectors and read/write operations are handled differently.
Not sure a "Self Test" makes sense on a flash drive due to that reason... why running a self test, if the specs makes it mandatory to log every error in a log? As long as there is free "Spare" space on the disk, "bad/worn out" flash cells should be "replaced".
More importantly, I don't see the device type listed in the identity info, so I think you need to specify that with the -d option, -d nvme. Try using the command smartctl -a -d nvme /dev/nvme0n1. If you prefer, use -x instead of -a.
Same result, nothing changed as far as I can see.
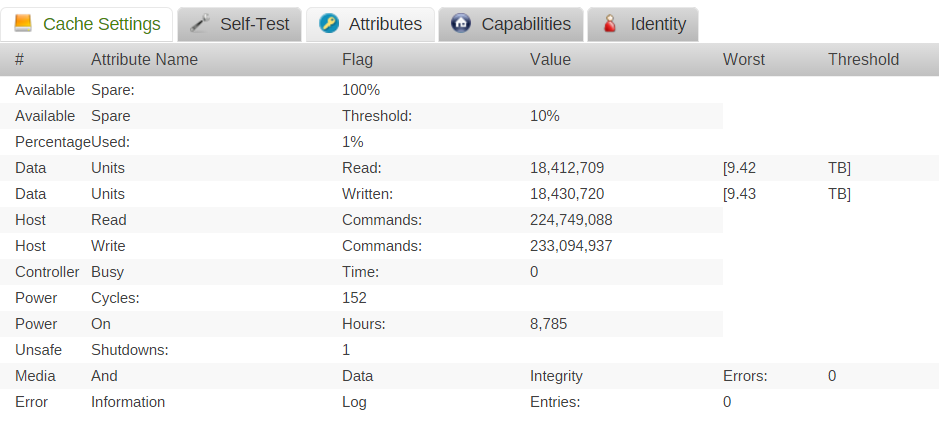
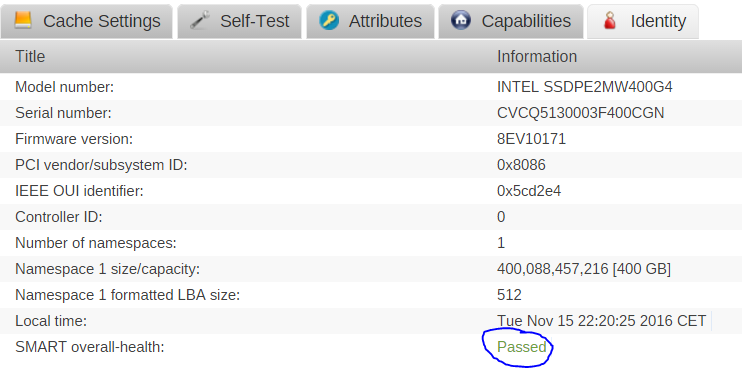
root@unRAID:~# smartctl -a -d nvme /dev/nvme0n1 smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Wed Nov 16 07:06:07 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === Read NVMe SMART/Health Information failed: NVMe Status 0x02
root@unRAID:~# smartctl -a -d nvme /dev/nvme0 smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Wed Nov 16 07:06:11 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff) Critical Warning: 0x00 Temperature: 23 Celsius Available Spare: 100% Available Spare Threshold: 10% Percentage Used: 1% Data Units Read: 18,416,807 [9.42 TB] Data Units Written: 18,433,008 [9.43 TB] Host Read Commands: 224,801,960 Host Write Commands: 233,126,889 Controller Busy Time: 0 Power Cycles: 152 Power On Hours: 8,794 Unsafe Shutdowns: 1 Media and Data Integrity Errors: 0 Error Information Log Entries: 0 Error Information (NVMe Log 0x01, max 64 entries) Num ErrCount SQId CmdId Status PELoc LBA NSID VS 0 2 1 - 0x400c - 0 - - 1 1 1 - 0x400c - 0 - -
-
I almost forgot:
"Print vendor specific NVMe log pages" is on the list auf 6.6 smartmontools.
Not sure if the vendors will find a common way, but at least for current Intel NVMe SSDs, there is a nice reference:
Intel® Solid-State Drive DC P3700 Series Specifications (Page 26)
-
Partition format:
GUI shows "Partition format: unknown", while it should be "GPT: 4K-aligned".
SMART Info
Back in 6.2 Beta 18, unRAID started support for NVMe devices as cache/pool-disk.
Beta 22 got the latest version of smartmontools (6.5)
Smartmontools supports NVMe starting from version 6.5.Please note, that currently NVMe support is considered as experimental.
While the CLI output of smartctl definitly improved, GUI still has no SMART info. Which is ok, for an "experimental feature".
It even gives errors in the console, while browsing through the Disk-Info of the GUI, which was reported HERE, but got no answer it seems.
I have not seen any hint in the 6.3 notes, so I asume, nothing will change. Probably low priority.
I think the issue is a wrong smartctl command issued through the WebGUI.
In my case, the NVMe disk is the cache disk and the gui identifies it as "nvme0n1", which is not wrong, but does not work with smartmontools...
root@unRAID:~# smartctl -x /dev/nvme0n1
smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Tue Nov 15 20:21:12 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === Read NVMe SMART/Health Information failed: NVMe Status 0x02
Don't ask me why, but if you use the "NVMe character device (ex: /dev/nvme0)" instead of the "namespace block device (ex: /dev/nvme0n1)" there is a lot more information.
Like "SMART overall-health self-assessment test result: PASSED"
root@unRAID:~# smartctl -x /dev/nvme0
smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Tue Nov 15 20:37:58 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff) Critical Warning: 0x00 Temperature: 24 Celsius Available Spare: 100% Available Spare Threshold: 10% Percentage Used: 1% Data Units Read: 18,412,666 [9.42 TB] Data Units Written: 18,429,957 [9.43 TB] Host Read Commands: 224,748,225 Host Write Commands: 233,072,991 Controller Busy Time: 0 Power Cycles: 152 Power On Hours: 8,784 Unsafe Shutdowns: 1 Media and Data Integrity Errors: 0 Error Information Log Entries: 0 Error Information (NVMe Log 0x01, max 64 entries) Num ErrCount SQId CmdId Status PELoc LBA NSID VS 0 2 1 - 0x400c - 0 - - 1 1 1 - 0x400c - 0 - -
According to NVME Specs (Page 92-94) the output does contain all "mandatory" information. (so it "should work" regardless of the vendor...)
Its probably a PITA, but I guess there are not many common information between SATA/IDE and NVMe Smart Infos... which means the GUI needs some reworking in that regard.
I guess "SMART overall-health self-assessment test result", "Critical Warning", "Media and Data Integrity Errors" and "Error Information Log Entries" would be most usefull in terms of health info and things that could raise an alert/notification.
Depending on the amount of work it needs, maybe monitoring "Spare Threshold" as an indication of a "soon to fail" drive (like reallocated events/sectors).
For science:
I changed the "$port" variable in "smartinfo.php" to a hardcoded "nvme0", ignoring any POST values.
See attachments for the result... not that bad for the quickest and most dirty solution I could think of

-
I normally shut vm's down manually as I've had the shutdown process hang a few times when I forgot to do that first.
Curious how many others have had this as an issue before...
I definitly had issues in the past, stopping the array without manually shutting down VMs/Docker. (once the array stopped, I never had issues though)
If I remember correctly, it was a thing in 6.1. Spinning up all disks and shutting down every VM and Container one by one, has become a habit.
I think the "stop Array" did not work, when I was logged into the console and had the prompt somewhere in the array (/mnt/user/...).
The web-gui was not responding until the array was stopped, which never happened, so I could not restart the array or cleanly shut down the server.
I couldn't even tell in which state the VMs/container were, so at first I thought the VMs/Container were causing the issue.
And because of the 6.2 (beta) issues with the complete array lockdown ("num_stripes"), I still do it as a precaution.
So, if anything happens after I press "stop array", at least I know there is no VM/container running/shutting down that could be the issue.
The system usually runs 24/7, so it's not a big deal, but since you asked...
Due to that habit, I can't tell if its still an issue or not.
That beeing said, no issues in 6.2.4 that I can speak of

I had a system freeze due to an GPU-overclock attempt and fat-fingering a '9' instead of '0'...

The unclean shutdown was correctly recognized, parity check started, 9 errors corrected with normal speed.
That did not happen during beta array-lockups and may have been a result of the fixes 6.2.3.
-
I choose to use the Plugin "Open Files" to do the job.
Find the entry that locks the .vhdx file and you are fine.
cleanest way would be to disconnect the disk through windows before you reboot, but you are probably as lazy as I am ;-)
-
Well, as it was said, it worked due to a bug.
I actually have not tried any other version than RC3, but that one worked.
Maybe that bug was only present in the kernel used in 6.2 RC3... or maybe not even every Skylake board is affected.
There is a workaround which more or less reproduce the effects of the bug. (not beeing able to load a module)
If you blacklist the driver, that prevents any device in the iommu grp to be passed through, it seems to be working.
I have not yet seen any side effects, but since I do not 100% know what that device does, its on your own risk
Go to "Main" -> "Boot Device" -> "Flash" -> "Syslinux configuration"
Add "modprobe.blacklist=i2c_i801,i2c_smbus" somewhere between "append" and "initrd=/bzroot".
It should look like this:
label unRAID OS menu default kernel /bzimage append modprobe.blacklist=i2c_i801,i2c_smbus initrd=/bzroot
Then save and reboot and see if you can start the VM with the onboard sound attached.
If not, you should post a diagnostics (tools -> diagnostics) or at least tell us what the iommu grps look like. (tools -> sytem devices)
Even if it works, keep in mind its a workaround, not a solution. A solution would probably to buy an additional pci-soundcard and pass that through.
There is a chance, that Intel just broke the passthrough of the onboard sound by grouping it up with another device. Maybe intentional, to push virtualisation to their workstation/Server hardware... or its an ASUS thing, because we both have ASUS.
-
You can't pass the integrated video/audio to a VM.
Right for iGPU, wrong for audio...
due to a bug in older kernels, it worked although it should not have due to the iommu grps.
Go HERE for Details...
Its just RC4 that does this, due to its newer kernel. Go with RC3 until they fix it... There are several ways to fix this, I think they are looking for the best way.
-
Weird. When I enable virbr0 I get most of what I thought you wanted with a Windows 7 VM. I cannot browse the network and I cannot connect a mapped drive to another server on my network but I am able to browse the internet. So I must not have understood what you wanted or I just don't know how to get around it in Windows like you must.
Like I said, the description of virbr0 suggests, that there is no firewall in place, just NAT (Network Adress Translation).
So, your VM is placed "behind" your server in a diffrent subnet, like your LAN is placed behind your router. Your router has a firewall, unraid does not. Adding a firewall to the virbr0 could be another solution.
There are many things that wont work through NAT. Like browsing the network, which is reliant on broadcasts and netbios.
If you disable the firewall on the other server and try to PING its IP-Adress (not hostname) it should work.
But you are still releativly "safe" because unless someone knows your real LAN and its ip-adresses, they would not know where to start. Malware however could just scan any private network and would eventually find your LAN and its devices and could do whatever it would do if it was in the same network.
In fact, I just looked into it, and it seems iptables is already running and active, to provide the docker network with everything it needs... (so the wiki is inacurate
)I asume the following rule is in place for the virbr0 network:
Chain FORWARD (policy ACCEPT) target prot opt source destination ACCEPT all -- anywhere 192.168.122.0/24 ctstate RELATED,ESTABLISHED ACCEPT all -- 192.168.122.0/24 anywhere
Which means the private network is allowed to go anywhere and all data that was requested from inside is allowed to go there.
I am very rusty with iptables, but if you add a DENY rule for your LAN, in front of the second rule that allows all, everything in your LAN should be "safe"...
To access this a VM with virbr0 from the internet (like rdp), would also require to add/modify itaples rules.
If anyone is interested, I would suggest the libvirt-wiki:
Forwarding Incoming Connections------------------------------------------
By default, guests that are connected via a virtual network with <forward mode='nat'/> can make any outgoing network connection they like. Incoming connections are allowed from the host, and from other guests connected to the same libvirt network, but all other incoming connections are blocked by iptables rules.
If you would like to make a service that is on a guest behind a NATed virtual network publicly available, you can setup libvirt's "hook" script for qemu to install the necessary iptables rules to forward incoming connections to the host on any given port HP to port GP on the guest GNAME:
-
Or, very quick, cheap and probably dirty...
You could use a firewall on the VM (windows fw may already do the trick).
Just block all of your internal IP-Addresses for outgoing and incoming traffic, except your router.
As long as you make sure, that your guests cannot alter these firewall-rules (no admin!), it should be "safe".
You could even consider using RemoteApps instead of a full blown Remote-Desktop.
That is possible even with a normal Windows: RemoteApp-Tool
Your possibilitys depend on your available hardware (router/switch) outside of unraid, if you post them, somebody may help with a more specific answer.
-
Use a virtual nic in the VM with the virtio drivers. Setup the nic to use virbr0. See "Configure a Network Bridge" in the wiki here: http://lime-technology.com/wiki/index.php/UnRAID_6/VM_Management#Configure_a_Network_Bridge
It states:
isolated from all other network services except internet access and the host's network file sharing protocolsHe writes:
(no SMB, nothing)And it seems to be NAT that "prevents" access from LAN->VM not a firewall. I do not know the specific configuration, but usually, VM->LAN should still work, so the VM could access unriad and other ressources on the LAN, just not the other way around (without specific ports forwarded to the VM). Unless the private bridge/kvm has some sort of firewall that can and does block traffic, in which case, access to the host maybe could be blocked as well.
I guess to be 100% sure, he would need to create a second subnet/VLAN on his router (wich is not a normal feature for consumer stuff, custom firmware may be needed) and either use VLANs or a diffrent physical port on the router and unraid.
Or buy a second router/firewall basicly do the same.
Or create a second VM, a router/firewall like pfsense, and declare that as the default GW for his vm. He could block all traffic from his vm to his LAN on that gateway.
Or, if his router has wifi with a guest SSID, he may try to passthrough a (USB/PCI) WiFi-card to the VM and use the guest SSID, wich should be isolated...
-
The problem is that a bug fix in the kernel indirectly "broke" Skylake onboard audio pass through. In Skylake, Intel put the onboard audio in the same IOMMU group as the SMBus controller. A kernel bug prevented this SMBus controller from being recognized correctly, thus preventing assignment of the SMBus driver. But once this bug got fixed, we now have a situation where a device in an IOMMU group has a kernel driver assigned, preventing it, and any other device in the same IOMMU group from being assignable to a VM. Hence, for Skylake, onboard audio passthrough was working "by accident" in 4.4.17 and below

I asumed exactly that and did not post a Bug report.
dAigo, I have a old diagnostics zip (4-5 months old) from you and it looks like your on-board sound card was probably disabled back then?
With your on-board sound card enabled, is it showing up under PCI Devices like this now?:
00:1f.3 Audio device [0403]: Intel Corporation Sunrise Point-H HD Audio [8086:a170] (rev 31)
Yes to both, wich is why I did not post new diagnostics while using a touchscreen... Too lazy and you should know my system by now
-
Same issue here.
Passing through onboard sound worked suprisingly well (no acs needed), considering then iommu groups.
After going to rc4 I got the same error mentioned above. Turned on acs and updated bios, no effect.
Went back to rc3, its working again.
-
I am thinking to buy a 256GB Samsung SM951, M.2 (22x80) PCIe 3.0 (x4) AHCI SSD, MLC NAND, Read 2150MB/s, Write 1200MB/s, 90k/70k IOPS and use this to store vm images on.
I currently have a sandisk x400 512 ssd 540/520 as cache (were i store my vms and dockers) but was thinking maybe would i be better to buy another x400 and use a raid 0 btrfs cache pool. I know the speeds will not be as high as the samsung drive (but i guess should be faster than a single x400 cache drive) but the plus is i would have more capacity.
I am a bit worried to change from my cache as xfs to btrfs.
What are your thoughts guys?
First of, I can't see any nvme related question, so you are probably in the wrong place ^^
Second, as far as I now, there is currently no raid0 (stripe) cache option, just a pool of disks.
One file wont be sperated(striped) between disks, so read/write for one file cant be faster than your fastest drive.
If you read/write diffrent files, that happen to be on diffrent disks in the pool, you could achive faster speeds in total.
In addition to that, most tasks in your vm are probably 4k random read/write, so your limit would be IOPS rather than bandwith. And in that case, both share the ahci/sata limit of ~80-90k IOPS.
If you are concerned about speed, I would recommend one of the disks outside of the array, that removes a software layer that your writes/reads have to go through and therefore should increase your IOPS.
I dont see any workload where ONE ahci pci device could use its high bandwith, maybe loading stuff (games/videos) into ram, but even with 4 GB ram, you could reduce filling the ram from ~8s to ~2s... but thats probably unlikely to happen.
To get back on topic, samsung released the successor to the oem SM951.
Its the SM961 and only available with nvme. (see HERE and HERE)
So you might get a good deal for the now obsolete 951, but dont expect nvme-perfomance from an ahci drive.
-
True, but that's because smartmontools does not yet support it, only temp info for now, nothing LT can do about that.
Yes and and no, according to b23 notes, they use 6.5 smarttools, which states:
8 Date 2016-05-079 Summary: smartmontools release 6.5
10 -----------------------------------------------------------
11 - Experimental support for NVMe devices on FreeBSD, Linux and Windows.
12 - smartctl '-i', '-c', '-H' and '-l error': NVMe support.
13 - smartctl '-l nvmelog': New option for NVMe.
14 - smartd.conf '-H', '-l error' and '-W': NVMe support.
15 - Optional NVMe device scanning support on Linux and Windows.
16 - configure option '--with-nvme-devicescan' to include NVMe in
17 default device scanning result.
18 - Device scanning now allows to specify multiple '-d TYPE' options.
From what I read (could be wrong), to include nvme, you would need to add "--with-nvme-devicescan" in /etc/smartd.conf.
Mine just states "DEVICESCAN" without any parameters. Not sure If anything should/could be done to activate that "experimental support".
smartctl -A on nvme actually already has a result. However, format is completly diffrent, probably because "experimental".
But I am sure it should be possible to extract some health info and put it into the gui or even create warnings on "error log entrys" or "Spare percentage used".
I know that LT is watching the smarttools notes for nvme related stuff, so I am sure its somewhere on their priority list.
Maybe quite low at the moment, which is fine for me. Others may think diffrently, but unless they say so, it will just come "eventually" rather than "soon".
root@unRAID:~# smartctl -A /dev/nvme0 smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.13-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF SMART DATA SECTION === SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff) Critical Warning: 0x00 Temperature: 36 Celsius Available Spare: 100% Available Spare Threshold: 10% Percentage Used: 0% Data Units Read: 13,711,975 [7.02 TB] Data Units Written: 13,529,802 [6.92 TB] Host Read Commands: 171,734,949 Host Write Commands: 191,229,783 Controller Busy Time: 0 Power Cycles: 129 Power On Hours: 5,441 Unsafe Shutdowns: 0 Media and Data Integrity Errors: 0 Error Information Log Entries: 0
root@unRAID:~# smartctl -A /dev/sdc smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.13-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 1 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 9 Power_On_Hours 0x0032 096 096 000 Old_age Always - 16289 12 Power_Cycle_Count 0x0032 097 097 000 Old_age Always - 2336 177 Wear_Leveling_Count 0x0013 091 091 000 Pre-fail Always - 293 179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0 181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0 182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0 183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0 187 Uncorrectable_Error_Cnt 0x0032 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0032 069 052 000 Old_age Always - 31 195 ECC_Error_Rate 0x001a 200 200 000 Old_age Always - 0 199 CRC_Error_Count 0x003e 253 253 000 Old_age Always - 0 235 POR_Recovery_Count 0x0012 099 099 000 Old_age Always - 411 241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 38543025273
-
Just thought I'd chime in as another person interested in adding nvme to their unraid server. I'm looking to purchase the Samsung 950 Pro nvme with a pcie slot card.
NVMe devices are already supported on v6.2-beta.
Some things, like SMART Infos are still missing in the latest beta (6.2 b23).
For critical data, maybe thats something to be considered.
-
Well, that was fast! Thanks again.
I added a new subdomain (owncloud -> nextcloud
 ), and everything went its way.
), and everything went its way.Folder got deleted and everything seems fine for now.
-
there was a disclaimer in the description of the container.
I probably read it and forgot about it when I added the subdomain
There is log rotation built in to nginx. I'll check to see if it's not working properly.
Hm, thats not what I can read here, but maybe thats an older version.
The email related error could be a temporary glitch likely on the server side because this container uses the same script for cron renewals and during startup. If you just let it run, it would have attempted again the next night and likely would have gone through
To be precise, renewal was up yesterday, so it failed twice, 17th and 18th with the same error.
cronjob running at Thu Jun 16 02:00:01 CEST 2016 Updating certbot script. It will display help info, which you can ignore deciding whether to renew the cert(s) Existing certificate is still valid for another 31 day(s); skipping renewal. <-------------------------------------------------> <-------------------------------------------------> cronjob running at Fri Jun 17 02:00:01 CEST 2016 Updating certbot script. It will display help info, which you can ignore deciding whether to renew the cert(s) Preparing to renew certificate that is older than 60 days Temporarily stopping Nginx * Stopping nginx nginx ...done. letsencrypt: error: argument -m/--email: expected one argument Restarting web server * Starting nginx nginx ...done. <-------------------------------------------------> <-------------------------------------------------> cronjob running at Sat Jun 18 02:00:01 CEST 2016 Updating certbot script. It will display help info, which you can ignore deciding whether to renew the cert(s) Preparing to renew certificate that is older than 60 days Temporarily stopping Nginx * Stopping nginx nginx ...done. letsencrypt: error: argument -m/--email: expected one argument Restarting web server * Starting nginx nginx ...done.
But if the whole process was "broken", because I added the subdomain and did not proberly remove any folders, who knows what other glitches could be a result of that.
I have your container running on two other servers, I'll see how it goes there
Thanks for the quick reply and have a nice weekend
-
Renewal was up, but failed:
cronjob running at Sat Jun 18 02:00:01 CEST 2016 Updating certbot script. It will display help info, which you can ignore [...] URL is XXXX.XX Subdomains are deciding whether to renew the cert(s) Preparing to renew certificate that is older than 60 days Temporarily stopping Nginx * Stopping nginx nginx ...done. Generating/Renewing certificate [...] letsencrypt: error: argument -m/--email: expected one argument Restarting web server * Starting nginx nginx ...done.
Restarting the container did the trick, but thats not how its upposed to work
*** Running /etc/my_init.d/00_regen_ssh_host_keys.sh... *** Running /etc/my_init.d/firstrun.sh... Using existing nginx.conf Using existing nginx-fpm.conf Using existing site config Using existing landing page Using existing jail.local Using existing fail2ban filters SUBDOMAINS entered, processing Sub-domains processed are: -d XXX.XXXX.XX -d XXX.XXXX.XX -d XXX.XXXX.XX -d XXX.XXXX.XX -d XXX.XXXX.XX -d XXX.XXXX.XX Using existing DH parameters <-------------------------------------------------> <-------------------------------------------------> cronjob running at Sat Jun 18 12:13:19 CEST 2016 Updating certbot script. It will display help info, which you can ignore [...] URL is stweb.pw Subdomains are extern,unraid,owncloud,prtg,vpn,3cx deciding whether to renew the cert(s) Preparing to renew certificate that is older than 60 days Temporarily stopping Nginx * Stopping nginx nginx ...done. Generating/Renewing certificate ...done. Generating/Renewing certificate 2016-06-18 12:13:32,741:WARNING:certbot.main:Renewal conf file /etc/letsencrypt/renewal/XXXX.XX.conf is broken. Skipping. IMPORTANT NOTES: - Congratulations! Your certificate and chain have been saved at /etc/letsencrypt/live/XXXX.XX-0001/fullchain.pem. Your cert will expire on 2016-09-16. To obtain a new or tweaked version of this certificate in the future, simply run certbot-auto again. To non-interactively renew *all* of your certificates, run "certbot-auto renew" - If you like Certbot, please consider supporting our work by: Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-le Restarting web server * Starting nginx nginx ...done. * Starting nginx nginx ...done. fail2ban.sock found, deleting * Starting authentication failure monitor fail2ban ...done. *** Running /etc/rc.local... *** Booting runit daemon... *** Runit started as PID 207 Jun 18 12:13:43 db60a164cff2 syslog-ng[215]: syslog-ng starting up; version='3.5.3' Jun 18 12:17:01 db60a164cff2 /USR/SBIN/CRON[231]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)
Maybe the Warning about the "broken" renewal conf had something to do with it?
Or some typo in your renewal cron that misses the mail parameter?
Or is it something on my end?
EDIT: Spoke to soon. Renewal worked, but its still using the old certs and is therefore renewing on every restart and maybe every cronjob...
Probably a broken !keys link? I think its supposed to point to ... /etc/letsencrypt/live/<domain> which it probably does, but the new certs are now in <domain>-0001. Not sure which one is wrong, folder or symlink.
EDIT2: I think I found the reason, you added some mechanism to identify changed domains... probably because you ran into the same issue?
2016-06-03 - Added ability to change url and subdomains (container will automatically recognize changes to the variables upon start, and will update the cert accordingly)I asumed is would recognize past changes and did not double check your tracking file.
I changed the domain (added a subdomain) before you patched it, so it couldn't just renew everthing but had to create a new folder... maybe also the reason for the "boken" renewal conf and maybe even the missing mail parameter?
Maybe you should not have tracked the docker parameter in your file, but the domains that are currently in the cert and compare them on start with the parameter? You would have been able to recognize past changes.
Now it should be fine, but if someone changed their domain before you added this feature, they may run into the same issue.
Maybe adding a reason for a change to your release notes or in this case mention that it would ONLY recognize future changes not past ones?
I would have been warned that way
I am not complaining, just some suggestions if you are interested
I usualy read patchnotes and enjoy detailed ones, with explanations. Obvoisly timeconsuming, so I understand If you dont explain everything I guess I will clean up the cert folder and start clean.
EDIT3: Oh and one last thing. My access.log is already 14MB+ and its not even a heavily used proxy. Do you have any kind of log-rotation in place? if not maybe add some and compress old logs? Maybe size depended or every 90 days or on every renewal? Just some suggetions

-
Sorry for posting my request in someone elses thread
, but while my motives are diffrent (privacy/security), it would result in less "useless stuff" in syslog.txt and therefore reducing its size, which is part of this threads intention...Mover entrys are very verbose, a cache folder with many items can spam in syslog.
While the share-names are masked, subfolder/file names are not, but in my opinion should be for the same reason.
While masking would not really reduce the syslog size, maybe just measuring the amount of moved items?
I am fine with "281 items moved" an a per share basis, at least in the default/anonymized diagnostic.
Mover-realated issues, could be investigated with the non-anonymized version through pm I think.
I could edit this post and create a new thread I you want, because some of your requests are already live it seems.
I had a 17MB Syslog1.txt in todays diagnostics due to a full cache disk and the rather long mover entrys hours later.
That was over a week ago and completly unrelated to the reason I posted my diagnostics.
-
Anomaly #1: I then did a New Config, and assigned the same two parity drives and 7 of the data drives (excluding the one I didn't want to use) ... and then Started the array. The system did NOT start a parity sync, but claimed that parity was already good
Clearly it was NOT.Are you sure you didn't check the "parity is already valid" checkbox by mistake? It happened to me sometimes since it's in the same place as the "I'm sure I want to this" checkbox (when displayed).
I've done tens of new configs with single and dual parity and a parity sync always begins if not checking the trust parity box.
Maybe related, but probably not.
I just finished my scheduled 2-Month parity check and it came back with 60748078 errors...
I was one of the people who had trouble with the freezing server and the resulting hard-resets. I also reproduced theese freezes and tried my best to make sure all of my disks are indeed spun down before cutting power.
I was always wondering, because after rebooting, unraid never started a parity check, I was thinking it was due to my best efforts. I have not yet seen any corrupt data, not in or outside of any VM, so I think/hope, that the data was written correctly, but due to the lockup in the unraid driver, changes didn't make it to parity. No disks, parity or data, show any errors or SMART warnings.
While the lock-up were definitly annoying, I think not starting a partiy check when it should be is a more severe issue.
The other thing that may have something to do with it, I switched one of the disks from xfs to reiserfs and back again.
But I always moved every file to another disk before I took the array offline, changed the filesystem, started the array, and hit "format" in the gui. I think that should not invalidate parity or because its an easy task through gui, at least warn the user that it does and start a new parity sync?
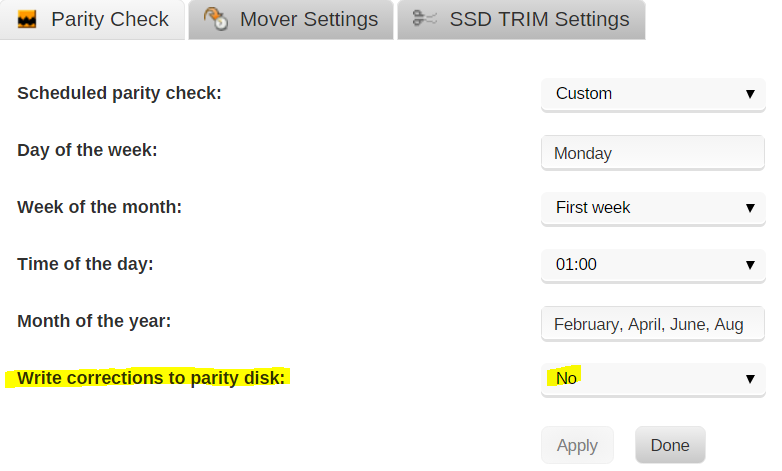
However, the most concerning thing for me is, the scheduled parity check runs with "nocorrect" in case I need to manually check if parity or data is wrong.
With 60748078 errors and nocorrect, shouldn't parity be invalidated? it still states "parity valid"...
I am tempted to run a manual parity check with "write corrections", but I would be willing to run another "check only" If you think it helps to find the issue.
Last option would be, I am confused and everything is as it should be, but an explanation would be nice in that case
Jun 6 01:00:01 unRAID kernel: mdcmd (117): check NOCORRECT Jun 6 01:00:01 unRAID kernel: Jun 6 01:00:01 unRAID kernel: md: recovery thread: check P ... Jun 6 01:00:01 unRAID kernel: md: using 1536k window, over a total of 5860522532 blocks. Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=0 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=8 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=16 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=24 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=32 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=40 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=48 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=56 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=64 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=72 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=80 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=88 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=96 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=104 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=112 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=120 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=128 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=136 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=144 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=152 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=160 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=168 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=176 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=184 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=192 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=200 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=208 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=216 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=224 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=232 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=240 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=248 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=256 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=264 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=272 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=280 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=288 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=296 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=304 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=312 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=320 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=328 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=336 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=344 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=352 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=360 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=368 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=376 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=384 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=392 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=400 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=408 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=416 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=424 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=432 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=440 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=448 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=456 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=464 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=472 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=480 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=488 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=496 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=504 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=512 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=520 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=528 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=536 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=544 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=552 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=560 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=568 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=576 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=584 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=592 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=600 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=608 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=616 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=624 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=632 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=640 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=648 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=656 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=664 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=672 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=680 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=688 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=696 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=704 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=712 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=720 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=728 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=736 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=744 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=752 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=760 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=768 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=776 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=784 Jun 6 01:00:11 unRAID kernel: md: recovery thread: P incorrect, sector=792 Jun 6 01:00:11 unRAID kernel: md: recovery thread: stopped logging Jun 6 17:55:24 unRAID kernel: md: sync done. time=60923sec Jun 6 17:55:24 unRAID kernel: md: recovery thread: completion status: 0
Diag. & screenshots attached...

-
anyone using this container along with linuxsever.io owncloud. their owncloud container uses ngix, mariadb and ssl.
I have lets encrypt working great with my two duckdns domains, when i type the address from the internet i get the landing page. been looking at the examples of the config files but when i modify mine it breaks. SO i am wondering if the use of there own ssl is causing the problem?
I am using it, and have no issues, from inside or outside my network.
I have done NO change to the OwnCloud docker, so it still runs on port 443 with whatever cert they are using.
The docker itself runs on port 8000 and proxy passed through nginx like any other docker. No issues so far.
site-conf/default:
server { listen 443 ssl; server_name owncloud.domain.com; location / { include /config/nginx/proxy.conf; proxy_pass https://<unraid_ip>:<oc-docker Port>/; }




 ), and everything went its way.
), and everything went its way.


Unraid OS version 6.8.2 available
in Announcements
Posted
I cannot get nested hyper-v to work in 6.8.2, while everything is woking in 6.7.2.
Anybody using nested Hyper-V VMs with 6.8.2? (Possibly even running a Skylake CPU)
Should I start a Bugreport (incl. diagnostics) or did I just miss anything obvious?
Existing VMs with hyper-v enabled won't boot (stuck at TianoCore)
Removing "hypervisorlaunchtype auto" from bcd makes the VM boot (but disables hyper-v)
Brand new VMs (default Server 2016 template) get stuck after the reboot to enable Hyper-V.
Should be easy to reproduce if it was a general problem. Just install server 2016/2019, enable hyper-v and reboot.
Testet with cpu paththrough (default) and cpu emulation (skylake-client), i440fx (default) and q35.
coreinfo.exe always shows vmx and ept present in windows.