lennygman
Members
-
Joined
-
Last visited
Everything posted by lennygman
-
Thank you.. That helped.. I fixed my Flash. Then i also tried to update code to stable version and was getting MD5 error. Suspected Ram issue. Ran MEMTEST and Ram failed it. I took out the sticks and tried to test each one separately and they both passed on their own :). I put back both and tested again and MEMTEST passed. Strange. Maybe Ram is about to fail soon or maybe was not very well seated in the slots. After starting OS , i am able to update to highest stable level and VMs started as well after a little repair of the bad shutdown. Thank you again for directing me in the right direction.
-
I shut down docker and restarted the array. Now I can see my shares. I am guessing an auto update happen on docker and maybe it screwed up my array. my VMs having issues now as well. They keep crashing and going into recovery . Array parity started I figured i let it run to make sure all my drives are ok. Then i will enable docker one at a time to see which one is crashing the array. Also probably need to rebuild my VMs? tower-diagnostics-20231017-2159.zip
-
Hello, I am not an expert. Not sure what happen. Array was running for a long time without any issues. Today in AM, noticed that I cant connect to a VM. Check array and it was shut down with error for a missing drive. I rebooted and it found the disk and came up fine after that. But now I see that shares are not showing. Not sure where to start. If this happen before, maybe someone can direct me to another thread for this issue. I saw a few about permissions issues on mnt/user but I did not touch anything. Thank you tower-diagnostics-20231017-2025.zip
-
Thank you.. Is there a recommended combo for CPU/Mobo for good performance like running multiple VMs, Dockers (Plex) etc..? Thanks
-
I upgrade to ASUS PRIME X670-P with AMD RYZEN 9 7900X a little while back. My Unraid started crashing every 15-30 min. I upgraded BIOS and UnRaid to 6.12.0 rc1 based on recommendation in attached thread and it seems to stabilize. Today it crashed again. First time from March 24th. Unlike before, now i was capturing logs on flash so attaching with diagnostic. I just upgraded to 6.12.0 rc2 (latest possible) as well Was hoping the experts here maybe can spot something in the logs that I can do to make my Unraid stable. Crash happened 4/1/23 I think around 18:xx or so. Thank you in advance. syslog 4.1.2023 tower-diagnostics-20230401-2146.zip
-
Its been stable since my last post. till running 6.12rc1 and the only thing i did was change IP to static. dont know if that helped somehow but only change i did after i upgraded BIOS and unraid to 6.12rc1
-
Spoke too soon. Crashed again. Run for a 5-7 hours. It completely goes dead. Even keyboard and monitor connected directly to the server have no response or even display. And it somehow kills my home network. Not sure what it is doing with the ethernet but a bunch of devices on my flat home network go down every time server crashes and cant even connect on their ethernet ports (few ethernet connected PCs, Wifi Mesh router, etc) . As soon as I unplug the UnRaid ethernet port, all devices instantly reconnect. Not IP confict. Some sort of LAN broadcast storm or something. I figured out how to save logs to flash. Will see if I capture anything that way
-
Thank you for the feedback. I had the latest ver of BIOS running and upgraded to Unraid to 6.12 and so far the server running the longest without crash. I hope that was it.. if i make it for a few days, it would mean problem solved. On a side note. what is C-States as I could not find that in my BIOS settings. Power efficiency feature?
-
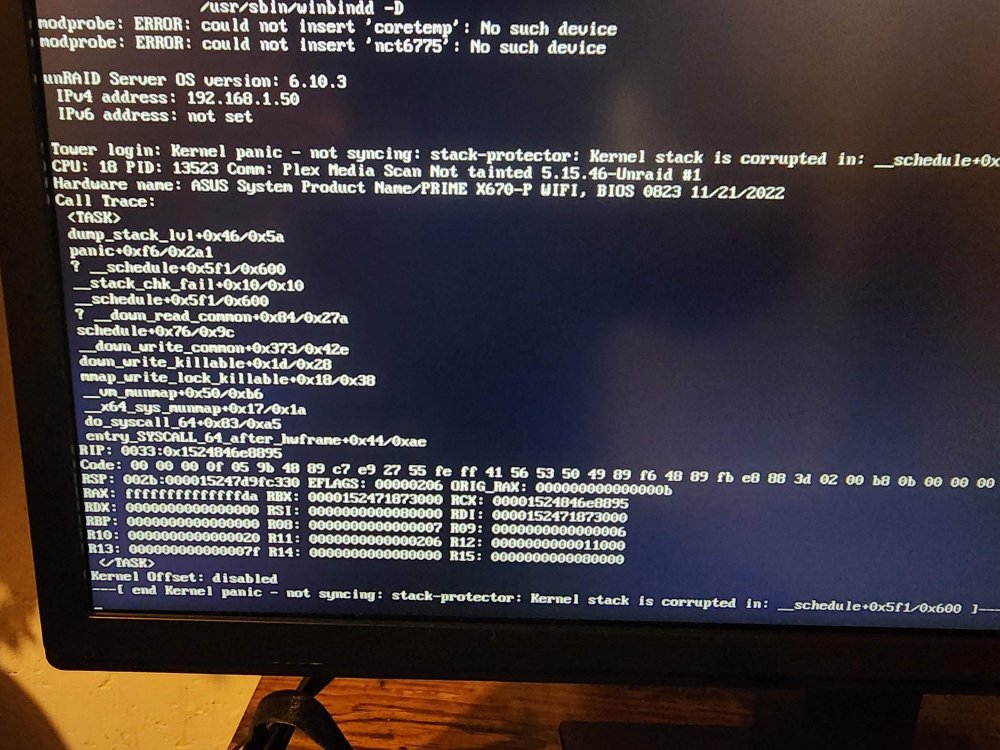
Hi. hopefully someone can help me out with what i can do to recover. I had an Unraid running 6.10.3 and wanted a faster CPU. I initially updated the software to latest 6.11.5. Then I swapped my mobo and cpu to the new hardware (ASUS PRIME X670-P with AMD RYZEN 9 7900X) and started the array. Everything came up fine and i used it for a day but during normal use, my shares disappeared a few times, some strange container issues. Some posts suggested an it worked to reboot to fix that. I figured I have an issue with 6.11.5 and reverted to 6.10.3. The situation now my array runs and then just crashes. Can not connect, console as you see in the attached pic shows kernel crash it seems. the strangest thing is when it crashes it takes out my home network until i pull out ethernet cable which restores connectivity. I dont think that is critical but wanted to mention. Attached are some files i can capture while array stays up. Also started to get USB error for USB stick with config. I think USB is fine, it was fine for a few days with this array and it starts fine but then I guess gives this error. USB flash drive failure: 17-03-2023 03:17 Alert [TOWER] - USB drive is not read-write Cruzer_Fit (sda) When its down i cant connect and nothing responds. Snapped a pic of the screen. I am not an expert on UnRaid or linux but it was a very stable system for a long time. Maybe an issue with the Mobo or CPU? Any thoughts are greatly appreciated tower-diagnostics-20230316-2214.zip tower-syslog-20230317-0215.zip