




sincero
Members
-
Joined
-
Last visited
Everything posted by sincero
-
This is a follow up to: I replaced Disk 4 since it was already throwing a ton of errors and reading at 1MB/s. I still have another 12TB drive that I would like to add to the array but I don't want to expand the number of drives (power is one aspect, but there is also the failure rate of having too many drives, plus I don't trust some of these drives anymore), so I would like to replace another drive. I've attached new diagnostics; promathia-diagnostics-20231219-1401.zip I'm thinking disk1 should go as it has had some spurious "errors" (from the dashboard) at times, though the SMART data is clean. tldr; you have to replace one of these drives, which would you choose? I will be draining the disks to swap filesystems later.
-
All the disks in this machine are from 2014/2015. I figure they're probably going to all be dying over the next few years so I'm considering whether it makes sense to replace them all with 6TBs or 8TBs to get fresh drives and another 5-10 years out of them. Thoughts? My server lately grows at about 1.2TB per year, so I'll need more space eventually anyhow.
-
Thanks! I'm planning maybe to upgrade over half the disks anyway (or maybe replace them all with 8TB) so I think this should take care of it since they'll have all new filesystems. I'll probably just wait until Black Friday for some of them.
-
Thanks! So if I understand correctly, I can proceed with a parity swap once I order a new disk?
-
promathia-diagnostics-20230929-0159.zip
-
It looks like I should replace Disk 4 which has terrible performance and is barely able to read data from (though, I can.. I did manage to copy a few files off it to test). Disk 2 seems fine from a performance standpoint. unRAID has not marked Disk 4 as bad. However, the syslog has a ton of sector read errors. It has to be replaced, clearly. How should I proceed? Should I manually remove this disk from the array and let parity take over? The disk is not marked as bad. Can I buy a couple 8TB disks to take over? This should give me a bit more room and get some of the ageing disks out of the array. Or should I shut it down and replace them then? I have a full backup at home on another machine, so there is no concern there. But it would be nice to avoid needing to copy all 14TB back over gigabit slowly
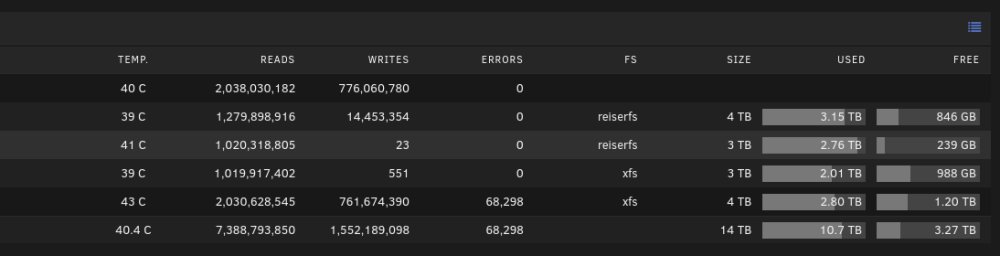
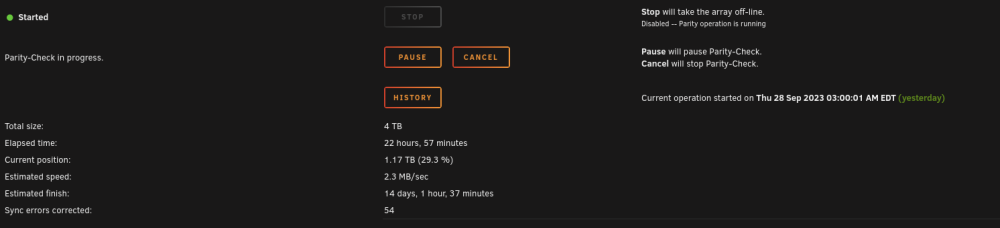
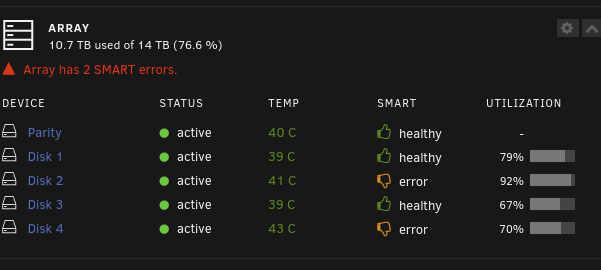
-
FYI this is a bit older but make sure to to the Config in Sab and go to "Special" and scroll down to the bottom. There's a section for a whitelist, make sure it reads "tower" or "Tower" depending on how you are trying to access it (or whatever hostname you use for your Sab box) The case sensitivity is key -- it matters.




