

ruablack2
-
Posts
29 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by ruablack2
-
-
https://forums.unraid.net/topic/42274-docker-pipework/
I used it a couple years ago before unraid/docker had the custom IP option. I can't seem to find it on CA anymore. Haven't used it in years, I just remembered it.
-
Would pipework fix this?
-
I've been having this issue every since I updated to 6.9. rc beta. I did this clear back last year to get the updated nvidia driver, little did I know that would cause utter chaos. I'm to the point where I'm thinking i need to rebuild my entire config from scratch or even an entire system upgrade, which I've been wanting to do but don't really need it. Anyways.
About every 24-48 hours my system will just freeze up and stop all network traffic. Sometimes I can get in on the console and it seems fine and but when I try to reboot/shutdown from console it will start the shutdown process but get hung somewhere. When this freeze happens I usually just hard reboot with the front button and it boots up just fine and we're good for another day. I've look at the logs and have sometimes found some erorrs but I'm just so lost and desperate at this point. I'll venmo you $25 if you can figure this out for me.
That one syslogs pretty juicy at 11mb and I can see lots of errors but can't make anything at of it.
-
Just discovered this on community applications and since I have a spare drive, a gig unmetered internet connection and static IP, I figured why not. But I can't get it to run. Just fails first thing. Any idea? I created my identity stuff on windows and moved it over, all the paths are right that I'm aware of.
Here's what it returns.
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='storagenode-v3' --net='host' -e TZ="America/Denver" -e HOST_OS="Unraid" -e 'TCP_PORT_28967'='28967' -e 'WALLET'='[Redacted]' -e 'EMAIL'='[Redacted]' -e 'ADDRESS'='[Redacted]:28967' -e 'BANDWIDTH'='20TB' -e 'STORAGE'='5TB' -e 'TCP_PORT_14002'='14002' --mount type=bind,source="/mnt/user/appdata/storj/identity/storagenode/",destination=/app/identity --mount type=bind,source="/mnt/user/StorjData/“,destination=/app/config 'storjlabs/storagenode:beta' The command failed.
-
Hmm ok thanks for the response. Ill try disabling my dockers with custom ip and re-create the image one more time. If not I might try moving my drive to a different sata port or to my LSI controller.
-
7 minutes ago, johnnie.black said:
Delete and recreate docker image.
I've done that multiple times. I've even gone as far as moving my appdata off the cache drive, formatting the whole cache drive clean and then creating a new docker image then moving back over only the appdata I need and then adding dockers back in from the templates. Nothing is on that cache drive but appdata and the new docker image.
-
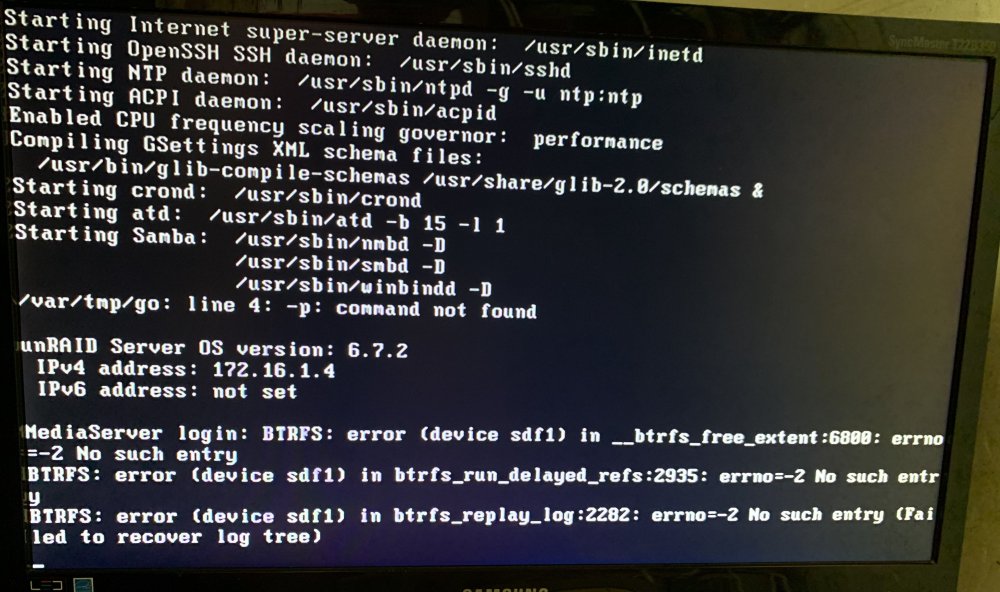
I've reformatted, redone the docker image, everything and still getting this error?
Aug 27 23:29:08 MediaServer kernel: verify_parent_transid: 36 callbacks suppressed Aug 27 23:29:08 MediaServer kernel: BTRFS error (device loop2): parent transid verify failed on 248840192 wanted 6627 found 6614Just a quick look at my syslog and you can see it's flooded by this error.
Is it a hardware error? Drive failing? Bad sata controller? Why is this now just coming up when everything has been working fine for 4+ years now? Any insight would be much appreciated.
-
Update: I ran
btrfs rescue zero-log /dev/sdf1and it fixed it to be able to mount but what would cause this in the first place?
-
My server just took a big crap. It's been working fine but the last few days quite a few errors have popped up.
Recently it would just be totally unresponsive on the network. I could still access it from console but nothing else. I usually would just reboot it from there and all is good. Last week my docker image got corrupted so I had to start a new one but no it looks like my whole cache is all wonky.
I just rebooted and am getting these errors and it says BTRFS filesystem is unmountable. It looks like the smart on one of the cache drives is reporting a Reallocated sector count of 10 and CRC error count of 2. Nothing like critical. I was going to replace that soon but did it die on me?
How should I proceed?
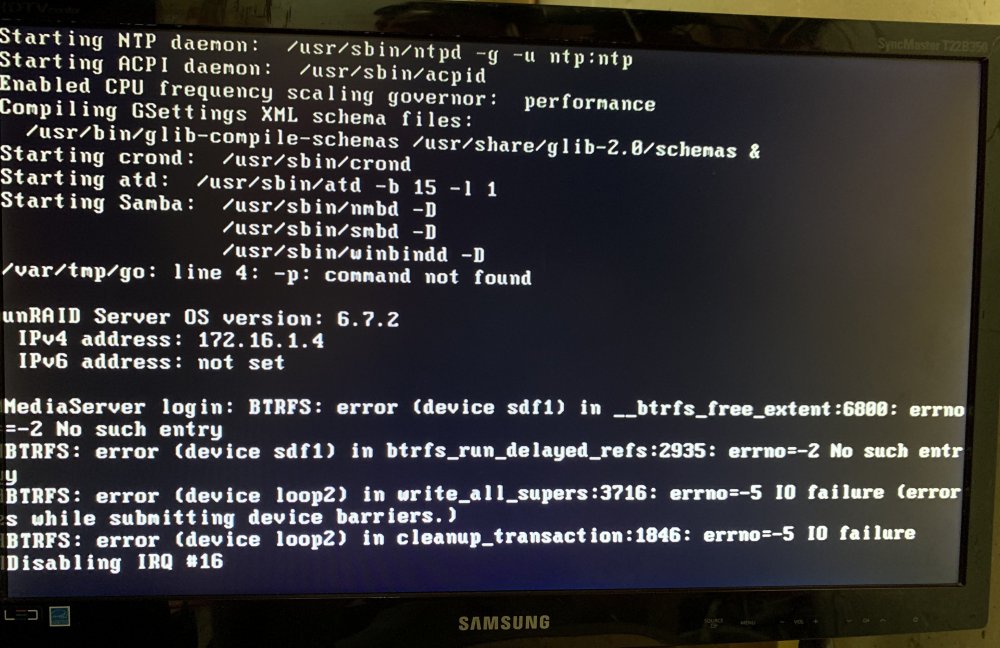
mediaserver-diagnostics-20190811-2028.zip
-
Hi, guys, I have a problem with my main server. The SMB on it is acting all weird. First just to gather some information. Does unraid still use SMB v1? I've read some stuff on SMB v1 being discontinued on fresh installs of Windows
I first encountered this problem when I got a new server, a Dell R620 with windows server 2016 on it and it fails to see it on the network. They're all on the same Workgroup but even when I put \\localip instead of \\mediaserver it still fails to connect. On the same server, I can type mediaserver\ in chrome and it loads the Web GUI fine. But then I booted up on my extra Unraid USB and I still can't connect to my main server through unassigned devices plugin over SMB. But on my windows 10 desktop, I can see it fine and connect to it just like normal.
What's going on here? Does anyone have any insight? I want to get this new server up and running so I can move Plex to it.
Main server:
Unraid 6.6.6
ASRock - C226 WS
Intel Xeon CPU E3-1246 v3 @ 3.50GHz
16GB EEC Ram
26TB array with 250GB Cache and various unassigned drives
10Gig SFP+
Dell R620:
Unraid 6.6.6/Windows Server 2016
2x Intel Xeon CPU E5-2650 v2 @ 2.60GHz
128GB EEC Ram
500GB SSD Array (Just holding docker and VM's)
10Gig SFP+
-
Its a Plex problem. Rolled out with the new 1.5.3 update.
https://forums.plex.tv/discussion/265492/transcoder-fails-when-transcode-is-on-a-network-share
NOW WHY DON'T THEY JUST ROLLBACK the update for docker. Like this screwed a lot of people! Kinda really frustrated with this.
And I cannot delete my config folder. I have wayy too much custom meta data. It would take forever to get it how it is now.
Anyone know the full release version number for 1.5.2? (eg 0.9.12.4.1192-9a47d21) I can't find it anywhere, so I can just put the tag <specific-version> on docker to get it back.
-
I think its more of an uraid thing.
It started last week when I was syncing a bunch of stuff to my phone, and filled up my cache drive. I was going out of town. Came back yesterday and I guess its been doing it all weekend.
But I'll post there too.
-
K I am having a big problem and it just happened recently.
I've used plex for years now and have never had a problem like this.
It simply will not play certain things. It says "Server too slow" but I know its not. Not even using much CPU. PlexPy says transcoder is under 1x which is weird.
Its really unexplained. Things I know.
- It happens with all dockers. Not just LinuxServer.
- I've reapplied permissions. Still nothing.
- It only happens on some of the recent movie/tv shows I've added. But not all.
- Direct play works fine. Its only when I transcode it.
I honestly don't know whats going on here. Can someone help?
-
Yep just realized that, it worked! Thank You sooo much!
-
Sorry for all the hassle.
When I execute the command
root@MediaServer:~# btrfs device remove /dev/sdi /mnt/cache
If the array is started I get
ERROR: error removing device '/dev/sdi': Device or resource busy
If the array is stopped I get
ERROR: cannot access '/mnt/cache': No such file or directory

-
I cannot find any documentation on balancing cache pools.
I go to the 1 cache drive, on that page it says this.
No balance found on '/mnt/cache'
I clicked balance and in the syslog it prints
Oct 29 11:49:48 MediaServer php: /usr/local/emhttp/plugins/dynamix/scripts/btrfs_balance 'start' '/mnt/cache' '-dconvert=raid1 -mconvert=raid1'
I don't know if that worked or not, if it's in the process of balancing or what.
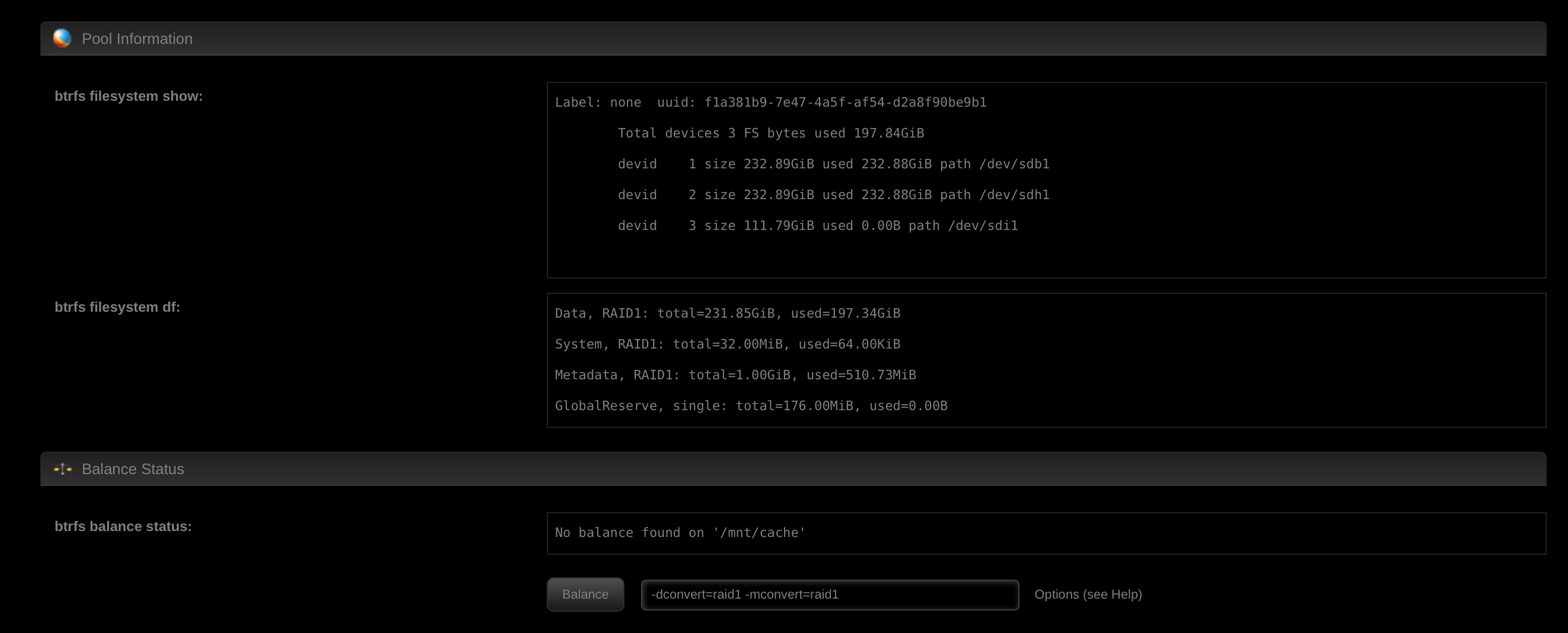
-
That still didn't work.
I stopped the array. Unassigned the drive. and then physically removed it. (I have hot-swappable bays so its pretty easy.)
started the array back up and it still "Unmountable"
-
You have to wipe the ssd? I backed everything up. But that still scares me.
-
When I do that is just says "Unmountable" when I start the array back up.
-
So I had 2 250Gb SSDs as my main cache. They were in RAID1.
I used this cache as a temp download for SAB. And as much as I download I didn't like all the extra writes to the drive.
I got another 120Gb SSD and want to use it as a scratch disk for mainly downloads, and didn't care for any protection on it.
I tried using Unassigned devices to mount it, but docker and SAB didn't play very nicely.
So I just ended up going to the cache tab and adding the 120Gb ssd to the 2 250Gb.
Now it created a pool of 310Gb. but I want to get the drive out. When I remove it, it freaks out.
When I connect to the share, it still says its only 250Gb.
I haven't balanced it the pool or anything.
I just want to know how to remove it before I screw it up more and lose the data.
I just want the drive back out of the "pool" and the orginal 2 250 back in RAID1.
-
Nope still don't have a solution. I've tried everything. It's sad, I really wanted to use plexWatch.
-
eroz, ivez, I've tried that many times.
clowrym, I think I have seen a related problem to mind a couple months ago and that was the solution but I use Plex Home and don't really want to turn it off. I just don't see how Plex Home can effect whether or not it can access it's database.
Is anyone else using Plex Home with a working plexWatch?
-
Still doesn't work.
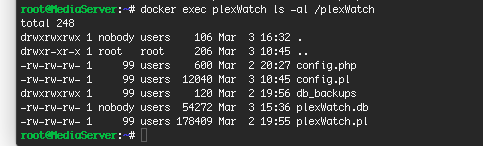
-
It can access Plex fine but not it's own database.






Hardware Upgrade Recommendation
in Hardware
Posted
Hey y'all, log time unraid user here. I have my trusty ole server I built in 2014. It's been great but now going on 8 years old and it's time for an upgrade. My current server basically runs Plex, Emby, the 'arrs, Home Assistant, etc. and it a local file store for the network, but it mainly a Plex box. I also have a Windows VM that I use (primary Mac user, so any Windows needs I RDP into this, super handy). While I don't find it slow because the P2000 is doing the heavy Plex lifting. 32GB ram is becoming slim. I'm also moving to a new house with 10 gigabit internet here in a couple months and I'm out of PCIe slots to add a 10Gb SFP+ card.
CPU: Xeon E3-1246 v3 @ 3.50GHz (Haswell, 7200 CPU benchmark, ouch, I know)
Mem: 32GB Quad channel 1600Mhz ECC
Mobo: ASRock C226 WS
PCIe: LSI HBA 8 SATA (PCIe x8)
Quadro P2000 (PCIe x16)
Samsung 3.2TB F320 NVMe (PCIe x8) (Drive is just plex appdata)
Mellanox 2-port SFP+ card (not in the server, ran out of PCIe slots, when I got the NVME)
Wanting to just do Mobo/CPU/Ram upgrade, keeping PCIe devices, power supply and case. Looking to spend maybe $2000 tops.
Couple quick question as with so much change in 8 years not sure what unraid does best on.
- ECC RAM? How important is it now days?
- Whats everyones thoughts on 1st gen threadripper? Or newer ryzen desktop with non-ecc? Don't need to go Intel for quicksync because I got the P2000. But 12th gen Intel is looking pretty nice.
- IPMI? I've play around with some iDracs on some dells and it sure is nice. Any recommended mobos with IPMI?
TYIA