

pyrosrockthisworld
-
Posts
24 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by pyrosrockthisworld
-
-
Hmm, that is some very interesting information, thanks for that.
Is there a way to circumvent this problem that i am experiencing?
Ideally obviously, I will change to a non raid card. The chassis has a 12port backplane in the front with 3 sas ports (SFF-8087 i think). what card would people recommend?
-
I am trying to move to a more flexible setup but having problems. not sure if new MB or the HBA but all drives report differently and therefore cant start the array. how can i tell it to try these disks?
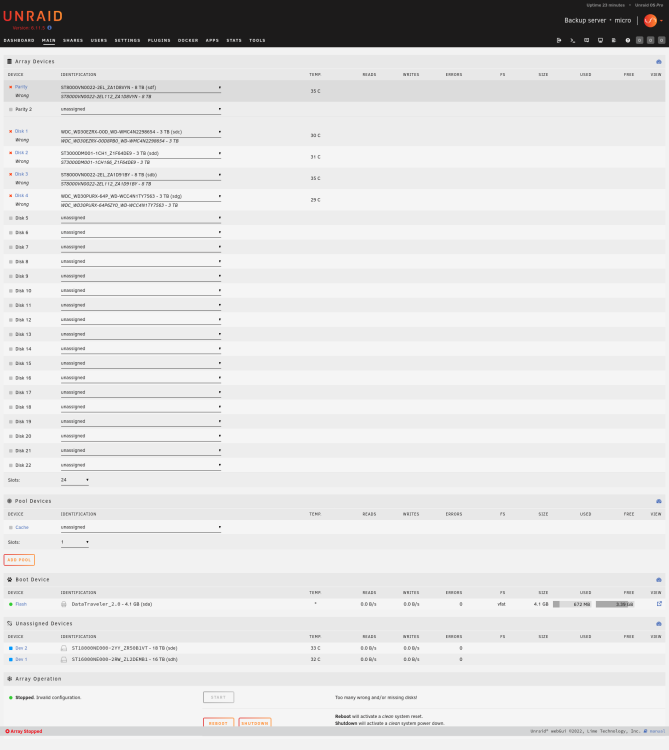
-
8 minutes ago, trurl said:
The purpose of UPS is to allow safe shutdown, not to allow running on batteries. If you run the batteries down you will have to let them recharge sufficiently before starting your server again or you won't have enough battery for safe shutdown.
After a short time on batteries, you can assume the power is going to be off for an unknown time and it should just go ahead and shutdown.
While this is true yes 99% of the power outages where I live are less than 15min. Which is easily within the run time of my UPS when foldingathome is not running, but, would require a shutdown if it is.
I have the system setup to shutdown at 15min reported runtime remaining
-
Hi, can any one tell me if there is a way to stop docker containers when the server is running off ups power?
I have a foldingathome container which i have running on the server which I need to stop if the power goes out and is running on the UPS
My UPS is capable of running my unraid server for over 45min if I do not have the foldingathome docker running but only 10min if everything is running at 100%Thanks
-
11 hours ago, trurl said:
Your user share named "all" still has files on cache. Do you know how to see what those are?
It has a hidden folder named .AppleDB
-
On 8/17/2020 at 6:27 AM, trurl said:
- Go to Settings - Docker and disable Docker. Also, delete docker.img from that same page. There are several other changes to make here later. Don't enable Docker again until instructed.
- Go to Settings - VM Manager and disable VMs. Don't enable VMs again until instructed.
- Go to each of your User Shares and set them to Use cache: Yes
- Go to Main - Array Operation and click Move. Wait for it to finish.
Then post new Diagnostics.
OK, here is the new diagnostics
Is now a good time to upgrade to the beta?
-
OK just got home from work, Mover is running now.
-
The 500G docker.img was because I was troubleshooting something and I forgot to change it back, thanks for reminding me.
As to the docker and vm not on Cache, I am unsure, I don't remember changing anything but it could be because I only installed the Cache later down the track. Though I believe some of the Vdisk.img are on there. Any hints on remedying that would be appreciated.
The Cache also gets used for when dumping files onto the server as fast as possible, so that I can get them in a second location after I for example pull footage off a camera.
-
43 minutes ago, trurl said:
to my questions without having to ask them, possibly requiring multiple posts that might even take a while since I might go to bed soon.
Cache pools technically don't have parity disks. What filesystem is your cache now?
ah,
My Cache Drive is currently btrfs
-
11 minutes ago, trurl said:
Depends on the answer to some questions. The easy way to get the answers is to
Go to Tools - Diagnostics and attach the complete Diagnostics ZIP file to your NEXT post.
I'm happy to include a diagnostics file but I'm not trying to diagnose anything. How would that be useful?
I want to know if making the SATA SSD a Parity Cache drive. then removing the M.2 drive from the system is a safe way to go about swaping drives.
I cant think why it wouldn't work but, has it been done? I'm just asking before I try it, in case I have overlooked something major.
Thanks
-
Hi Guys,
I am looking to "upgrade" my cache drive and want to know if my "easy" way of doing it will work or if it will cause trouble.
I was just going to shove my larger SSD into the system and tell it to use it as cache parity drive. Then once its all synced up then remove the old SSD cache drive.
I have searched how to upgrade the Cache drive and everyone seems to do it manually, so I wanted to ask if my lazy way would work or if I have to do it manually for a reason.
You may be wondering why I don't just leave the old one there for Parity. Well I am going down the route of changing motherboards to a dual socket server board which does not have any M.2 to be able to use the current Cache drive so I want to swap from it (256GB) to a SATA (1TB) SSD that I have lying around. Because I no longer do anything directly on the UnRaid server the loss of speed from the NVMe is no penalty as network infrastructure would be the bottleneck.
Thanks for any thoughts and or feedback
-
So after a frustrating conversating on the phone with the fred.com.au tech support, I have been told that they dont support Linux based systems.
When i asked why the DHCP server was on there server they said that they recomend because some crap about there programme knows where all the computers are or something but gave no actual details.
So i asked why it is sending the ssh and telnet requests and he basically just fobbed me off refusing to place fault with there server saying that the requests must be forewarded through there server because it is the DHCP and DNS server.
I have checked the router at 0.1 is just set as a DHCP relay sending everything to 0.2
I will take the test server home tonight and run it there to check that it wont fall over in my home network environment.
-
If nothing else, you need answers from someone about that rental server!
* Who's maintaining it, and is it secure? Are they sure it hasn't been hacked? It's on your internal network, with access to everything!
* Why is it providing DHCP services, instead of the gateway machine?
* Why is it providing the same local IP to 2 different machines?
* Why is it telnet'ing into your server?
* What else is it doing on your server?
* Especially, what is it doing about 5 seconds after the telnet connection, that causes emhttp to crash?
*It is maintained by our software main software vendor fred.com.au and yes it has full access unfortunatly
*Im not realy sure it was setup before i started
* I dont know
* no clue
* probably all sorts
-
What can you tell us about 192.168.0.2? And is it necessary? Couldn't 192.168.0.1 provide DHCP services? You could stop the DHCP confusion by setting static IPs on both servers, but that won't stop the bad stuff that 192.168.0.2 is spewing.
interesting i hadn't considered something else on the network knocking it over.
yes i do need 192.168.0.2 , it is the a rental server from one of our software vendors.
It was installed before i started and i don't have any access to the server as they don't want us running anything on there server.
It is running some sort of windows server edition and runs the domain and DHCP.
-
You say you changed memory but you never answered the question of whether or not you had actually done memtest.
sorry, yes i have. it ran with no errors.
For how long?
about 18h
-
So, I have a second server the exact same minus the ram upgrade. I have been using it as a test ubuntu server for a while.
I installed to a new flash drive a freshly unziped copy of 6.01 made bootable and chucked a drive in it.
As i was just trying to register a trial key to test the different set of hardware, BOOM, same issue.
Here is the syslog.
-
You say you changed memory but you never answered the question of whether or not you had actually done memtest.
sorry, yes i have. it ran with no errors.
-
I initially thought that the ram was the issue too when 5.x and 6b6 did it but after swapping out the original 2gb stick for 2 4gb sticks the issue was still there.
Yes totaly stock unmodified thus I found out about unmenu and installed that so i could clean shutdown the array.
I can now report that with the server booted up in safe mode the issue persists.
Jul 17 10:03:58 micro ntpd[1271]: kernel reports TIME_ERROR: 0x41: pll unsync Resource temporarily unavailable (Errors) Jul 17 10:25:32 micro sshd[8777]: Bad protocol version identification ' ' from 192.168.0.2 port 56823 (System) Jul 17 10:25:32 micro in.telnetd[8822]: connect from 192.168.0.2 (192.168.0.2) (Routine) Jul 17 10:25:32 micro telnetd[8822]: ttloop: peer died: EOF (Logins) Jul 17 10:25:37 micro kernel: emhttp[1327]: segfault at 0 ip 00002af1bac67426 sp 00007ffdbe6f13d8 error 4 in libc-2.17.so[2af1babe0000+1bf000] (Errors)
I also have a unraid server running at home and it works like a charm but different hardware.
-
I have just booted into safe mode now to see what happens, i will let you know.
BUT
when i first booted the server with a clean install before i even got to register the server with a key it crashed.
so to set it up i had to keep rebooting it, each time getting it a little more setup.
-
it looks like the web server daemon just dies.
(from /usr/bin/top -b -n1) top - 09:22:37 up 15 min, 1 user, load average: 1.65, 1.24, 0.64 Tasks: 109 total, 2 running, 107 sleeping, 0 stopped, 0 zombie Cpu(s): 8.0%us, 8.7%sy, 0.0%ni, 66.8%id, 16.3%wa, 0.0%hi, 0.2%si, 0.0%st Mem: 8051740k total, 407164k used, 7644576k free, 5752k buffers Swap: 0k total, 0k used, 0k free, 297952k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6107 root 20 0 11616 3440 2484 S 2 0.0 0:01.87 preclear_disk.s 1 root 20 0 4368 1572 1472 S 0 0.0 0:19.37 init 2 root 20 0 0 0 0 S 0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0 0.0 0:00.11 ksoftirqd/0 5 root 0 -20 0 0 0 S 0 0.0 0:00.00 kworker/0:0H 7 root 20 0 0 0 0 S 0 0.0 0:02.18 rcu_preempt 8 root 20 0 0 0 0 S 0 0.0 0:00.00 rcu_sched 9 root 20 0 0 0 0 S 0 0.0 0:00.00 rcu_bh 10 root RT 0 0 0 0 S 0 0.0 0:00.09 migration/0 11 root RT 0 0 0 0 S 0 0.0 0:00.07 migration/1 12 root 20 0 0 0 0 S 0 0.0 0:00.19 ksoftirqd/1 14 root 0 -20 0 0 0 S 0 0.0 0:00.00 kworker/1:0H 15 root 0 -20 0 0 0 S 0 0.0 0:00.00 khelper 16 root 20 0 0 0 0 S 0 0.0 0:00.00 kdevtmpfs 17 root 0 -20 0 0 0 S 0 0.0 0:00.00 netns 19 root 0 -20 0 0 0 S 0 0.0 0:00.00 perf 248 root 0 -20 0 0 0 S 0 0.0 0:00.00 writeback 250 root 25 5 0 0 0 S 0 0.0 0:00.00 ksmd 251 root 39 19 0 0 0 S 0 0.0 0:00.01 khugepaged 252 root 0 -20 0 0 0 S 0 0.0 0:00.00 crypto 253 root 0 -20 0 0 0 S 0 0.0 0:00.00 kintegrityd 254 root 0 -20 0 0 0 S 0 0.0 0:00.00 bioset 255 root 0 -20 0 0 0 S 0 0.0 0:00.00 kblockd 378 root 0 -20 0 0 0 S 0 0.0 0:00.00 ata_sff 396 root 0 -20 0 0 0 S 0 0.0 0:00.00 devfreq_wq 492 root 0 -20 0 0 0 S 0 0.0 0:00.00 rpciod 493 root 20 0 0 0 0 R 0 0.0 0:01.42 kworker/0:1 519 root 20 0 0 0 0 S 0 0.0 0:00.00 kswapd0 589 root 20 0 0 0 0 S 0 0.0 0:00.00 fsnotify_mark 609 root 0 -20 0 0 0 S 0 0.0 0:00.00 nfsiod 613 root 0 -20 0 0 0 S 0 0.0 0:00.00 cifsiod 625 root 0 -20 0 0 0 S 0 0.0 0:00.00 xfsalloc 626 root 0 -20 0 0 0 S 0 0.0 0:00.00 xfs_mru_cache 663 root 0 -20 0 0 0 S 0 0.0 0:00.00 acpi_thermal_pm 707 root 0 -20 0 0 0 S 0 0.0 0:00.00 kworker/u9:0 708 root 20 0 0 0 0 S 0 0.0 0:00.12 kworker/u8:2 709 root 0 -20 0 0 0 S 0 0.0 0:00.00 kloopd 770 root 0 -20 0 0 0 S 0 0.0 0:00.00 vfio-irqfd-clea 794 root 20 0 0 0 0 S 0 0.0 0:01.28 kworker/1:2 865 root 0 -20 0 0 0 S 0 0.0 0:00.00 bioset 872 root 0 -20 0 0 0 S 0 0.0 0:00.00 deferwq 875 root 20 0 0 0 0 S 0 0.0 0:00.00 scsi_eh_0 876 root 0 -20 0 0 0 S 0 0.0 0:00.00 scsi_tmf_0 877 root 20 0 0 0 0 S 0 0.0 0:00.15 usb-storage 932 root 20 0 21664 2452 2016 S 0 0.0 0:00.14 udevd 978 root 20 0 0 0 0 S 0 0.0 0:00.00 scsi_eh_1 979 root 0 -20 0 0 0 S 0 0.0 0:00.00 scsi_tmf_1 980 root 20 0 0 0 0 S 0 0.0 0:00.00 scsi_eh_2 981 root 0 -20 0 0 0 S 0 0.0 0:00.00 scsi_tmf_2 982 root 20 0 0 0 0 S 0 0.0 0:00.00 scsi_eh_3 983 root 0 -20 0 0 0 S 0 0.0 0:00.00 scsi_tmf_3 984 root 20 0 0 0 0 S 0 0.0 0:00.00 scsi_eh_4 985 root 0 -20 0 0 0 S 0 0.0 0:00.00 scsi_tmf_4 988 root 20 0 0 0 0 S 0 0.0 0:00.02 scsi_eh_5 989 root 0 -20 0 0 0 S 0 0.0 0:00.00 scsi_tmf_5 990 root 20 0 0 0 0 S 0 0.0 0:00.01 scsi_eh_6 991 root 0 -20 0 0 0 S 0 0.0 0:00.00 scsi_tmf_6 993 root 20 0 0 0 0 S 0 0.0 0:00.12 kworker/u8:7 1074 root 20 0 0 0 0 S 0 0.0 0:00.00 kworker/0:2 1113 root 20 0 228m 2384 1988 S 0 0.0 0:00.02 rsyslogd 1229 bin 20 0 7424 1572 1464 S 0 0.0 0:00.00 rpc.portmap 1233 rpc 20 0 12836 1944 1780 S 0 0.0 0:00.00 rpc.statd 1243 root 20 0 6460 1588 1484 S 0 0.0 0:00.00 inetd 1253 root 20 0 24952 2652 2248 S 0 0.0 0:00.00 sshd 1265 root 20 0 96884 8840 5688 S 0 0.1 0:00.10 ntpd 1273 root 20 0 4384 1552 1420 S 0 0.0 0:00.00 acpid 1286 messageb 20 0 17436 204 0 S 0 0.0 0:00.00 dbus-daemon 1288 root 20 0 6468 1452 1344 S 0 0.0 0:00.00 crond 1290 daemon 20 0 6460 100 0 S 0 0.0 0:00.00 atd 1295 root 20 0 191m 4708 3528 S 0 0.1 0:00.05 nmbd 1297 root 20 0 267m 13m 12m S 0 0.2 0:00.07 smbd 1304 root 20 0 9380 2200 1984 S 0 0.0 0:01.36 cpuload 1601 root 20 0 9368 1572 1368 S 0 0.0 0:00.00 uu 1602 root 20 0 4356 632 564 S 0 0.0 0:00.00 logger 1605 root 20 0 6472 1660 1556 S 0 0.0 0:00.00 agetty 1606 root 20 0 6472 1580 1472 S 0 0.0 0:00.00 agetty 1607 root 20 0 6472 1660 1552 S 0 0.0 0:00.00 agetty 1608 root 20 0 6472 1656 1552 S 0 0.0 0:00.00 agetty 1609 root 20 0 6472 1576 1468 S 0 0.0 0:00.00 agetty 1610 root 20 0 6472 1668 1560 S 0 0.0 0:00.00 agetty 1614 root 20 0 23540 7400 2964 S 0 0.1 0:00.42 awk 1617 root 0 -20 0 0 0 S 0 0.0 0:00.00 md 1625 root 20 0 0 0 0 S 0 0.0 0:00.00 mdrecoveryd 1633 root 20 0 0 0 0 S 0 0.0 0:00.00 spinupd 1634 root 20 0 0 0 0 S 0 0.0 0:00.00 spinupd 1635 root 20 0 0 0 0 S 0 0.0 0:00.00 spinupd 1660 root 20 0 0 0 0 S 0 0.0 0:00.01 unraidd 1674 root 0 -20 0 0 0 S 0 0.0 0:00.00 reiserfs/md1 1675 root 0 -20 0 0 0 S 0 0.0 0:00.00 kworker/1:1H 1685 root 0 -20 0 0 0 S 0 0.0 0:00.00 reiserfs/md2 1697 root 20 0 149m 1108 664 S 0 0.0 0:00.01 shfs 1723 root 20 0 45540 2916 2484 S 0 0.0 0:00.05 netatalk 1728 root 20 0 46172 4300 3756 S 0 0.1 0:00.00 afpd 1729 root 20 0 34928 3656 3244 S 0 0.0 0:00.00 cnid_metad 1736 avahi 20 0 34320 2452 2188 S 0 0.0 0:00.06 avahi-daemon 1737 avahi 20 0 34188 236 0 S 0 0.0 0:00.00 avahi-daemon 1745 root 20 0 12744 1480 1364 S 0 0.0 0:00.00 avahi-dnsconfd 3959 root 20 0 285m 13m 11m S 0 0.2 0:00.03 smbd 3992 root 20 0 285m 13m 11m S 0 0.2 0:00.05 smbd 5312 root 20 0 185m 9240 8040 S 0 0.1 0:00.08 in.telnetd 5313 root 20 0 13316 3296 2708 S 0 0.0 0:00.04 bash 6447 root 20 0 21660 2280 1836 S 0 0.0 0:00.00 udevd 6449 root 0 -20 0 0 0 S 0 0.0 0:00.00 kworker/0:1H 6451 root 20 0 0 0 0 S 0 0.0 0:00.00 kworker/1:1 10421 root 20 0 0 0 0 S 0 0.0 0:00.00 kworker/u8:0 17722 root 20 0 19528 2936 2624 S 0 0.0 0:00.00 gawk 17725 root 20 0 9328 2268 2136 S 0 0.0 0:00.00 sh 17726 root 20 0 13280 2200 1920 R 0 0.0 0:00.00 top 17728 root 20 0 4364 720 656 S 0 0.0 0:00.00 sleep
-
"falls over" means what exactly? (Assuming clicking a link just causes a hang). Please obtain syslog after server is in this state. Also have you tried 'safe mode' (boot option) in order to discount plugin causing this?
That syslog was after it had fallen over.
When i say falls over it just acts like there is no web server at all. When i get to work i will re boot the server and get another syslog for you again.
-
yes it is clearing the disk but that is unrelated to the issue at hand.
what is the preclear script?
-
unraid 6.01
My server runs quite well but every time after about 1/2 hour the web interface totally falls over. the shares and everything else continues to work and i can get to it using telnet or the unmenu plugin interface.
This is the same as it was with v5.x and v6beta6 and i had hoped that it would be fixed with v6.01.
I can reproduce it every time i boot the server
I am using a HP ProLiant MicroServer.

New system all wrong disks
in General Support
Posted
Thanks for all the info. have ordered a card per the recommended controllers.
I also noticed that the firmware on my card (RS25DB080) was very very old(23.7.XXX) so i updated it to the newest version (23.34.0-0019). This has actually solved the issue with the disks having different identification and the array now loads up perfect.
Will add in the new card still when i get it