chazlarson
Members
-
Joined
-
Last visited
-
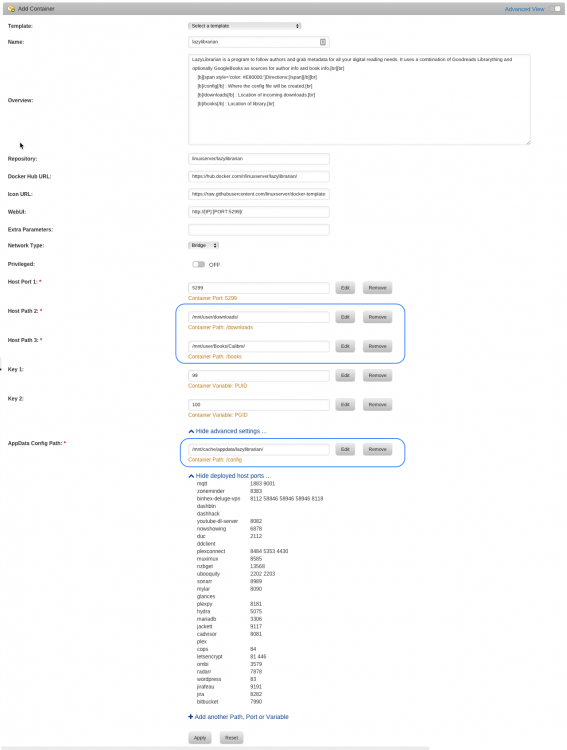
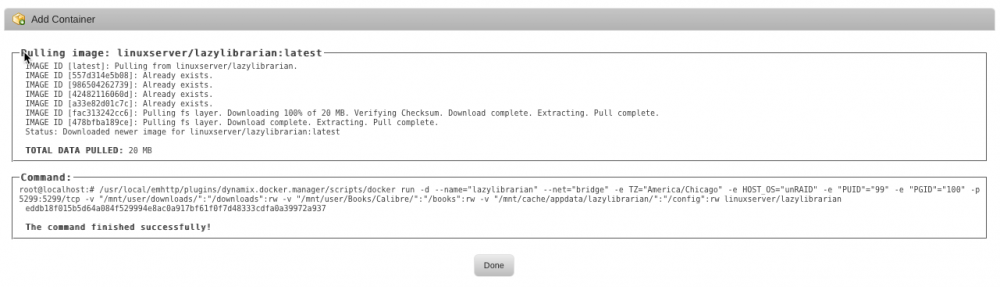
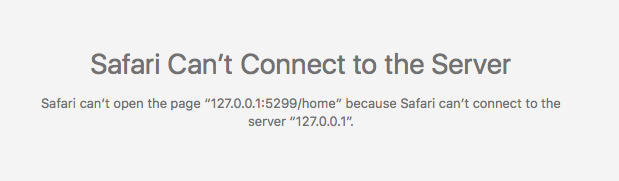
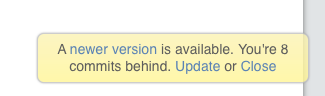
EDIT: Apparently I just needed to wait for a while, as both of these are now cleared up. I did install and subsequently remove the activ-lazylibrarian docker in there to see if it showed the same problems, but used a different port and app data location [it was 830 commits behind and didn't show the "127.0.0.1" problem]. Aside from that this one was just running for about 50 minutes. Two issues, one of which makes configuring it further difficult. I've just installed this fresh; there was no app data folder to start. Docker setup: [I only changed the indicated fields] Startup showing docker command: It's running, and lists the IP as I'd expect. The WebUI menu item seems to be pointing to the right place: Issue 1: When I select "WebUI" from the menu, or click the "192.168.1.2:5299" link, I get this: The URL in the address bar is now 127.0.0.1:5299. If I edit it to 192.168.1.2:5299, the UI loads. I can then bring up the settings panel, but clicking the save button gives me the can't connect because it's again going to 127.0.0.1. Changes are saved, but I have to edit the URL again to get back to the UI. Issue 2: Restarting the docker and forcing an update have no effect. Log is attached. Any suggestions on either front? ll-log.txt