htpcguru
Members
-
Joined
-
Last visited
Everything posted by htpcguru
-
By reading the two posts above yours. Awesome, that was easy!
-
root@UnRaid:~# docker inspect -f '{{ index .Config.Labels "build_version" }}' linuxserver/transmission Linuxserver.io version:- 126 Build-date:- June-01-2018-22:08:29-UTC Container version 126 contains Transmission 2.94. I need to downgrade Transmission to 2.93 as one of my trackers rejects the latest Transmission 2.94. How would I do that?
-
Thanks for the tip. Now things are much better: root@UnRaid:~# du /mnt/disk3/ -s 1727843185 /mnt/disk3/ root@UnRaid:~# du /mnt/disk4/ -s 1725260516 /mnt/disk4/ Moving onto other Reiserfs disks...
-
I believe I found where the problem is. Somehow, a vdisk1.img is copied with a much bigger size: root@UnRaid:~# ls -l /mnt/disk4/vm_backup/Windows\ 10\ Workstation/ total 398458884 -rwxrwxrwx 1 root root 408021893120 Mar 1 2016 vdisk1.img* root@UnRaid:~# ls -l /mnt/disk3/vm_backup/Windows\ 10\ Workstation/ total 40994716 -rwxrwxrwx 1 root root 408021893120 Mar 1 2016 vdisk1.img* I know that KVM/Qemu sizes the vm disk dynamically, so that could explain why on disk3 the actual image size of 40994716 is much smaller than the allocated size of 408021893120. However, I cannot explain why the copied image file is not the same size.
-
I have the same line of thinking - the difference is too much to consider normal. root@UnRaid:/mnt/disk3# find /mnt/disk3 -type f | wc -l 8109 root@UnRaid:/mnt/disk3# find /mnt/disk4 -type f | wc -l 8109
-
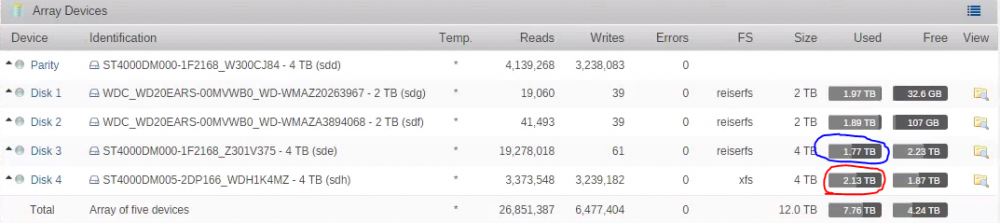
I followed the wiki and step 8 of the first Reiserfs disk is done. However, I notice on the unRaid main page that the used size of the destination XFS disk is larger than the source disk. On the ssh console: root@UnRaid:~# du -s /mnt/disk3 1727843185 /mnt/disk3 root@UnRaid:~# du -s /mnt/disk4 2083663832 /mnt/disk4 root@UnRaid:~# df /mnt/disk3 Filesystem 1K-blocks Used Available Use% Mounted on /dev/md3 3906899292 1727914992 2178984300 45% /mnt/disk3 root@UnRaid:~# df /mnt/disk4 Filesystem 1K-blocks Used Available Use% Mounted on /dev/md4 3905110812 2083701224 1821409588 54% /mnt/disk4 Is this expected? Does XFS use more space than Reiserfs? Please see attached screenshot. The red circle is the used size of the XFS disk (should have the same content of disk3), and blue is the used size of the Reiserfs source disk3.