




neztach
Members
-
Joined
-
Last visited
-
if I remove them both, array greys out "start array", unless I commit to them being out ....makes me nervous. Would it be better to wait for my replacement cache drive to arrive? or if I do unassign them, can I then put them back in case something goes wrong?
-
says can't because disk is mounted, but can't get to the rest of the pool if its unmounted

-
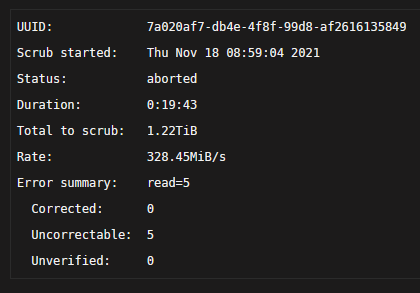
it appeared to have gotten further, and I believe I now have both cache drives in SATA slots, diagnostics included to confirm. Nothing I can do to possibly limp it along to get a copy of the contents? Some of it? all of it? like I said, all I really want is my VMs ...specifically one of them. after that, I don't mind decomissioning the bad SSD and formatting the remaining one as cache. I already have a new 2TB en route. eden-diagnostics-20211118-0919.zip
-
I think the device dropping issue is probably symptomatic of the drive dying, in which case, what could I really do about it? Having said that, I'll shuffle the drives around again, and send another diagnostics. In the mean-time, If-after I shuffle the cache drives to both be on SATA the device still drops, is there something I can do after that to attempt to copy data off?
-
To reiterate, I would love for there to be some kind of method to just change the pool back to using a single drive (the 1 of 2 drives in the cache pool still good). Of I would be willing to buy a new 2TB SSD to replace both drives in the pool. At this point, I would just like some way (ANY. way.) - that would allow me to at least copy off whatever files are essential - especially my VMs. Is there anything I can do here?
-
well based on your original response, I rearranged my cache drives to what I thought was the LSI. Can you confirm? and I feel like I'm coming across as dense, but which are my intel ports? eden-diagnostics-20211117-1340.zip
-
you're absolutely right, and I'm perfectly willing to try. I'm just wondering which log you got that from, so I can look at the previous diagnotics and see if either cache drive was previously in an LSI to narrow down what ports I could try, then self-verify so I can follow your advice and get both of them on an LSI controller.
-
I guess I don't understand how one SSD appears to be connected differently than another SSD. It's a single backplane, and both are connected to the same backplane. Perhaps in my previous diagnostic, one of the drives was hooked up to an LSI controller then as well? If I knew which was was on the LSI controller both then and now I can perhaps shift them around so they are both in a slot previously recognized as LSI. If-not, which part of the diagnostics would I look at to see LSI vs SASLP?
-
also, I have a HUGE PlexMediaServer folder on cache that I wouldn't be upset about if I trashed all together. Would it help - or make it worse - or change nothing?
-
I keep rebooting and scrubbing ....sometimes it gets father, sometimes not. Shall I continue, or is there a better approach?
-
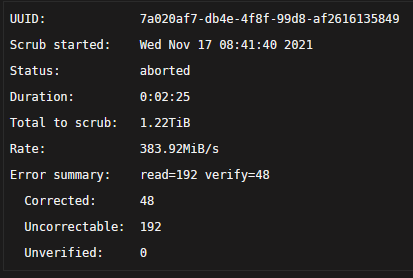
I have a backplane, so I can't really plug directly into the board, but I switched the slots for both cache drives, and the corrective btrfs scrub started fine, then aborted. eden-diagnostics-20211117-0845.zip
-
wow I'm such a rookie! Apologies, see attached. eden-diagnostics-20211116-1542.zip
-
https://drive.google.com/drive/folders/1P4ck5oJ1ko4VGZyHPu7m6qGHRF6IMsc7?usp=sharing hopefully that link works.
-
So I have a cache pool /dev/sdj and /dev/sdk and /sdj is throwing errors, so probably going bad. For a minute, restart I was able to get it to be recognized and come online, and I stupidly missed my window to copy my windows VM from within. At this point, if I spin up the array normally, the cache pool will say "no file system" seemingly no matter what. Whatever section of /sdj1 that's bad is right in the section where mover needs to move, so I can't move anything. I also can't run dockers, as they were built dependent on cache, so no krusader. I found a link here which allows me to make the cache pool read only, which lets me look at things via console. btrfs rescue zero-log /dev/sdj1 I've attempted multiple variations of rsync to copy the vdisk.img to a location on the array, all of which fail. The latest being rsync -avh --progress --sparse /mnt/user/domains/Windows\ 10/vdisk1.img /mnt/user/Archives/VMBackup/Win10/ which results in the following (bear in mind only 200G is allocated to that VM): 214.75G 100% 63.13MB/s 0:54:04 (xfr#1, to-chk=0/1) rsync: [sender] read errors mapping "/mnt/user/domains/Windows 10/vdisk1.img": Input/output error (5) WARNING: vdisk.img failed verification -- update discarded (will try again). 214.75G 100% 51.68MB/s 1:06:02 (xfr#2, to-chk=0/1) rsync: [sender] read errors mapping "/mnt/user/domains/Windows 10/vdisk1.img": Input/output error (5) ERROR: vdisk1.img failed verification -- update discarded. I also tried cp -av --sparse=always <source> <destination> '/mnt/user/domain/Windows 10/vdisk1.img' -> '/mnt/user/Archives/VMBackup/Win10/vdisk1.img' cp: error reading '/mnt/user/domain/Windows 10/vdisk1.img': Input/output error I'm at a loss. Any advice? Honestly, if I could remove the pool, and put all of cache on /dev/sdk1 then I'm sure all would be well.


