

jedimstr
-
Posts
124 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jedimstr
-
-
16 hours ago, tigger2k said:
You need to connect by ssh, or open the web console for this container.
Then type:venv/bin/chia wallet showThen you can press S to skip. The wallet will by synced after some hours.
Thanks! Worked well.
-
 2
2
-
-
First of all, thanks for this!
Having an issue with an imported mnemonic. Summary shows "Unknown" for Total Chia and Wallet shows:
QuoteNo online backup file found, Press S to skip restore from backup Press F to use your own backup file: Exception from 'wallet' EOF when reading a line
But the Settings/Keys tab shows the correct Fingerprint, Public Keys, and First Wallet Address that I have on one of my Windows PC's running the Windows Chia client with the same mnemonic/wallet. Any idea on how I can fix? -
Am I the only one who thinks its a bad idea to put out a version update with "DO NOT INSTALL ON 6.8" in the default update path? Wouldn't it have been better to put out a separate plugin beta for manual install for 6.9 RC2 and keep the plugin that's compatible on the current stable versions on the regular plugin? What about those users who just click Update All and don't check the release notes?
-
Unfortunately I'm hitting the Exit code '56' from all the port-forward capable endpoints on the list. Tried ca-vancouver and ca-toronto first (I'm usually on ca-toronto anyway) but they've been on a constant retry loop for the last few hours. None of the others are working either.
-
1
-
-
-
I'm in the middle of a Parity Rebuild (upgrading one of my array disks from 10TB to 16TB Exos), and started getting hanging issues with my cache pool that lead to docker and the webGUI to timeout. When I do get through to Settings or Tools tab (other tabs hang, sometimes I get partial load on Main and shows Array is reading/writing), the parity rebuild is progressing (footer progress still going up in percentage) so I'm hesitant on doing a 'powerdown -r' or a physical reboot. There are long stretches when I can't access the WebGUI at all (max_children errors, I've already raised the level in www.conf for next reboot).
So is there a way to check Parity Rebuild process from the commandline so I can do a powerdown -r when it finishes?
-
Probably more of a feature request, but is there a way to get Privoxy working with a Wireguard VPN provider instead of an OpenVPN provider? The goal would be for speed.
-
1
-
-
On 12/21/2019 at 9:59 AM, itimpi said:
This almost invariably turns out to be the disk is continually resetting for some reason. It is often a cabling issue but since it recovered when left alone there my just be a dodgy area on the drive. It might be worth running an extended SMART test on the drive to see what that reports.
That particular drive ended up having multiple read errors and just dying even on a new pre-clear pre-read. Ended up RMA'ing it.
After taking that drive out of the equation, I still get relatively slow parity syncs/rebuilds, but never as slow as with the RMA'd drive. Slowest now is in the dual digit MBs range (but it goes back up to the high 80's or 90's again). -
8 hours ago, gfjardim said:
Thanks. You have another plugin using utempter (probably for screen) and the plugin saw that as a problem. Just issued an upgrade, please tell me if it fix your problem.
Yup it looks like that fixed it. Thanks!!!
-
3 hours ago, gfjardim said:
Please remove the plugin, install it again and send me all the content from the installation process.
Removed and re-installed from CA. Here's the installation output:
plugin: installing: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/plugins/preclear.disk.plg plugin: downloading https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/plugins/preclear.disk.plg plugin: downloading: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/plugins/preclear.disk.plg ... done plugin: downloading: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/archive/preclear.disk-2020.01.13.txz ... done plugin: downloading: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/archive/preclear.disk-2020.01.13.md5 ... done tmux version 3.0a is greater or equal than the installed version (3.0a), installing... +============================================================================== | Skipping package tmux-3.0a-x86_64-1 (already installed) +============================================================================== libevent version 2.1.11 is greater or equal than the installed version (2.1.11), installing... +============================================================================== | Skipping package libevent-2.1.11-x86_64-1 (already installed) +============================================================================== utempter version 1.1.6 is lower than the installed version (1.1.6.20191231), aborting... +============================================================================== | Installing new package /boot/config/plugins/preclear.disk/preclear.disk-2020.01.13.txz +============================================================================== Verifying package preclear.disk-2020.01.13.txz. Installing package preclear.disk-2020.01.13.txz: PACKAGE DESCRIPTION: Package preclear.disk-2020.01.13.txz installed. ----------------------------------------------------------- preclear.disk has been installed. Copyright 2015-2020, gfjardim Version: 2020.01.13 ----------------------------------------------------------- plugin: installed Updating Support Links preclear.disk --> http://lime-technology.com/forum/index.php?topic=39985.0
-
Both version 2020.01.12 and 2020.01.13 are showing the "unsupported" warning even though it was updated for 6.8.1 support.

-
To update, I was eventually able to complete the rebuild after a reboot.
But then I have more disk replacements to do, so I'm in my second data drive replacement now on 6.8.0 and it slowed to a crawl again after a day. I rebooted the server again, which of course restarted the rebuild from scratch, but this time I saw slowdowns again down to the dual digit KBs range. This time I just left it running and eventually it bumped back up to around 45MBs, and a day later up to 96.3MBs... still crazy slow but better than the KB range. Hope the general slow parity/rebuild issue gets resolved.
-
4 hours ago, johnnie.black said:
Not seeing anything that explains that, and the rebuild looks to be completely stalled now, there are some DMA read issues but seem unrelated.
I would try a reboot, if it stalls again try to take notice of the time it happens and post new diags.
You can also run the diskspeed docker to check all disks are performing normally.
Thanks, I rebooted and I see Parity run at better speed now. Started from scratch and still slower than usual but at least its in the 3 digit MB range.
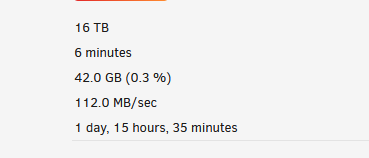
There was also an Ubuntu VM I had running that often accesses a share that's isolated to one of the drives being rebuilt, so just in case that has anything to do with it, I shutdown that VM.
I'm not the only one seeing this slow to a crawl issue though. Another user on Reddit posted this:
-
After upgrading to 6.8.0, I replaced my parity drives and some of my data drives with 16TB Exos from previous 12TB and 10TB Exos & IronWolfs. Initial replacement of one parity went fine with full rebuild completing in normal fashion (a little over 1 day). For the second parity, I saw that I could replace it and one of the data drives at the same time, so went ahead and did that with the pre-cleared 16TB drives. The parity-sync/data-rebuild started off pretty normal with expected speeds over 150+MBs most of the time until it hit around 36.5% where the rebuild dramatically dropped in speed to between 27/KBs to 44/KBs. It's been running at that speed for over 2 days now.
At first I thought this was somehow related to the 6.8.0 known issues/errata notes that mentioned an issue with slow parity syncs on wide 20+ arrays (I have 23 data drives and 2 parity), but my speeds are much slower than those reported in the bug report for that issue by an order of magnitude.
Here's what I'm seeing now and my diagnostics attached.
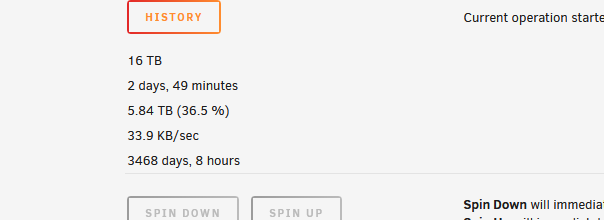
-
3 minutes ago, johnnie.black said:
It's here, but that's way too slow, you should start a thread in the general support forum and please attach the diagnostics.
Thanks I'll post in general support. My results definitely seem much slower by an order of magnitude than the slowdowns mentioned in the bug post.
-
Is there an active bug posted around the slow Parity-Sync/Data-Rebuild for wide arrays mentioned being looked at in the errata?
I can't find it in the bug forums.
I'm definitely seeing this problem with my 23 data and 2 parity drive array. I've replaced both a data drive and one of the parity drives in the same rebuild session so that may be a contributing factor. I wanted to see if there's any data I can gather that would help in your investigation on the issue and see if there were any stop-gap solutions in the meantime but like I said, I can't find an active bug post for this.
Here's my rebuild's current progress:
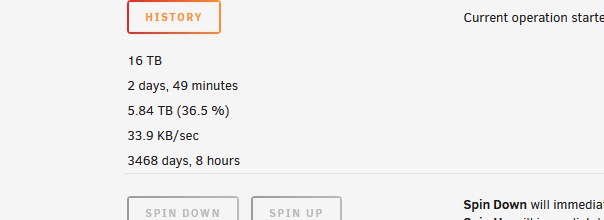
-
Congrats on moving forward with this new container and giving everyone what they wanted whether they wanted to stay on older versions or leap ahead to current released versions. I've already moved on to other container providers, but happy to see you guys take critique and release a better product that should please everyone.
-
I'm sorry for causing such a hubub. I really didn't mean for this to get out of hand.
-
6 minutes ago, aptalca said:
You're literally missing the point.
It just says we maintain images. Nothing about versions. Even if we maintain a working image that contains a version 5 years old, it satisfies the above criteria as long as it still works.
Let me make one thing clear. Lsio is a group of volunteers who got invited to become team members based on their contributions or commitment (with the exception of the original founders). We are not elected public officials. We owe nothing to you. We do not serve at your pleasure. I serve at my pleasure. I do what I want.
With that said, we are nice people and we try to give back to the community. Do not confuse our good will with any false sense of obligation.
As an FYI, the constant badgering of unify users on multiple forums, discord, Reddit, GitHub and private messages every time there is a new version pisses me off so much that I have 0 interest in touching the unifi repo for any reason even though I myself am a user of that image.
Look, I'm sorry if I came off in a bad way and really don't want to badger.
But the criteria mentioned in the past on why things aren't updating "not until it shows up on their download page" occurred and things still weren't updated. So if that's no longer the case, then you guys should stop saying it. Nice and easy, just don't say it. Keep a 5 year old version, fine. Don't say you'll update when their software page is updated. That's no longer a valid excuse.
You should also maybe think about rewording this then:
"Our build pipeline is a publicly accessible Jenkinsserver.
This pipeline is triggered on a weekly basis, ensuring all of our users are kept up-to-date with latest application features and security fixes from upstream."
-
5 minutes ago, CHBMB said:
"We make and maintain container images for the community."
Where does that say we promise updates immediately?
If you're running critical network infrastructure that demands 0 day patching, then you should be looking at maintaining your own software or contracting out to someone who will do it for you. Or get involved and help maintain it, rather than rely on other people volunteering their free time to do it for you.
I'm sorry if I've been ticking you off. That's definitely NOT my intention.
But I want to make clear that previous criteria claimed for keeping this particular repo up to date have been met days before the weekly update cycle, but that weekly cycle didn't pick up this update on the unstable tag. So lets keep this to the technical reasons why this was, not on a personal level. If there's some other reason fine. I'm just calling out that something broke here.
Also the reasoning of why to choose LinuxServer.io's repos versus others, is because they have been reliable in pretty much every other repo.
-
1 minute ago, CHBMB said:
We do make and maintain container images, but as people we don't exist purely to do so at the drop of a hat, now you claim you don't have enough free time to help but then give me this shit. I work well in excess of full time, have a wife and a daughter, am doing professional exams. Still manage to dedicate what I can here.
It's not a case of I don't have enough free time, what you're actually saying is "I'm not willing to donate any of the free time I have"
So get off your high horse and wind it in.
Fair enough, I wasn't proposing to do things at the drop of a hat.
I was proposing that if the source of the images were posted as has been deemed as the previous requirement for updating the unstable tag, then the pipeline should have picked up that version on the weekly update, but didn't, then something is wrong.
It's not a personal attack against you, so don't take it as such. My response to yours was because your response went against what even LinuxServer.io's site says.
As for the importance of this release... 5.10.12 is actually very important from a security perspective due to an open known exploits in the wild. Lots of us really do need this version to mitigate possible attacks/scans that are occuring: https://community.ubnt.com/t5/UniFi-Updates-Blog/UniFi-Network-Controller-5-10-12-Stable-has-been-released/ba-p/2665341
-
14 minutes ago, CHBMB said:
... you all need to start bearing in mind that we don't live to purely exist every repository as soon as software is updated. EVERYTHING we do is in our limited spare time, we all have families, jobs and other commitments.
Also... if you want to claim that, then don't have this on your website's main motto:
"We make and maintain container images for the community."
Because if you claim that, then yes, Linuxserver.io DOES purely exist to keep every repository software updated. That's the point.. If not why use Linuxserver.io in the first place. I love you guys for keeping one place where to have reliable repo sources, but to claim that it's not why you're here is disingenuous at best.
-
Just now, CHBMB said:
We are migrating everything to a new pipeline system for our builds and Unifi hasn't been tackled yet.
Understood and much appreciated on the family/lives front. Wish I had time to contribute as well.
That said, previous excuse of "it has to be on the download page" rarely applies anymore, so its probably best not to use it and just say "we'll get to it when we get to it". And yes, it is stuck on 5.9.x on unstable at the moment so don't know why you wouldn't think that. If you create a new container and point it to the unstable tag, you don't get 5.10.x so yes, stuck meaning it's still on previous version release is valid.
Side request (and probably can't be tackled for awhile so I guess more of a wishlist item): since naming conventions count to some of us for tags, and fully understanding previous issues leading to your team keeping the latest "stable" releases from Ubiquiti as "unstable" tags because of their software f' ups. Can we have something like this instead?
Long Term Release: /latest
Latest UBNT deemed stable release: /ubntstablerelease
Latest UBNT beta release: /beta
That way default is always longterm and more likely to be stable.
This also avoids calling something "unstable" when that particular beta or "stable" release may actually be really stable.
-
2 hours ago, CHBMB said:
Read the posts further up regarding 5.10.12
Sent from my Mi A1 using Tapatalk
Have you read some of them?
Previous criteria was that latest releases are available in UBNT's download page before they appear in Unstable tag.
UBNT has had 5.10.12 available on it's download page for a few days now: https://www.ui.com/download/unifi
The Unstable tag had an update 2 days ago (more than a day after 5.10.12 was available from the download page) yet its still stuck on 5.9.x.
So...





[6.8.0] Extremely slow Parity-Sync/Data-Rebuild
in General Support
Posted
it could actually be any of your drives that could be dying not just the one you’re rebuilding. Parity operations use all your array drives and are limited by your slowest drive. So if any of your drives are dying or have other issues it’ll slow any parity operation like a rebuild.