

swells
-
Posts
150 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by swells
-
-
4 hours ago, nicksphone said:
ok first thing its looking like your kill stalled is not working correctly now i know the software is not great with ts files so if you delete .ts and .m2ts from the scanned for files in your lib containers your likely to get rid of this issue it solved it for me. For .ts and .m2ts files use the recording converter app its made for ts files will put them in mp4 files for you. it will still fail on some but its alot better than this at the moment. maybe when they are out of beta it will work better with .ts files.
Yeah, I was just coming here to say I think I have tracked the issue to the "Auto-cancel stalled workers" option being on. I turned it off last night and have not had an issue since. I have had a few fail, most are .ts or .m2ts.
Thanks for the help!
-
6 hours ago, nicksphone said:
everything seems fine with what you sent are any of these files .ts it hangs on?
Ok it started happening again this today and I was able to catch it early.
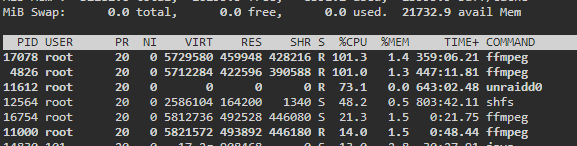
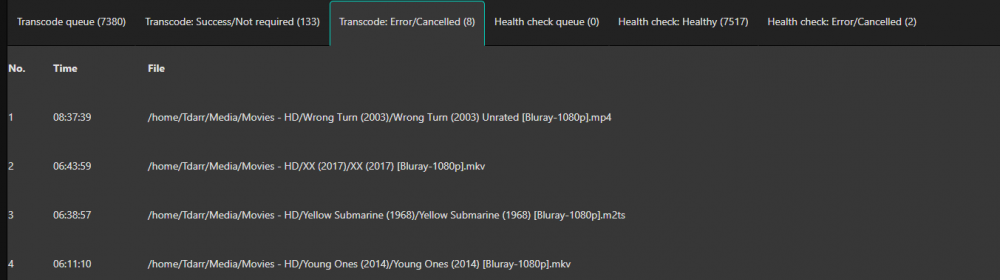
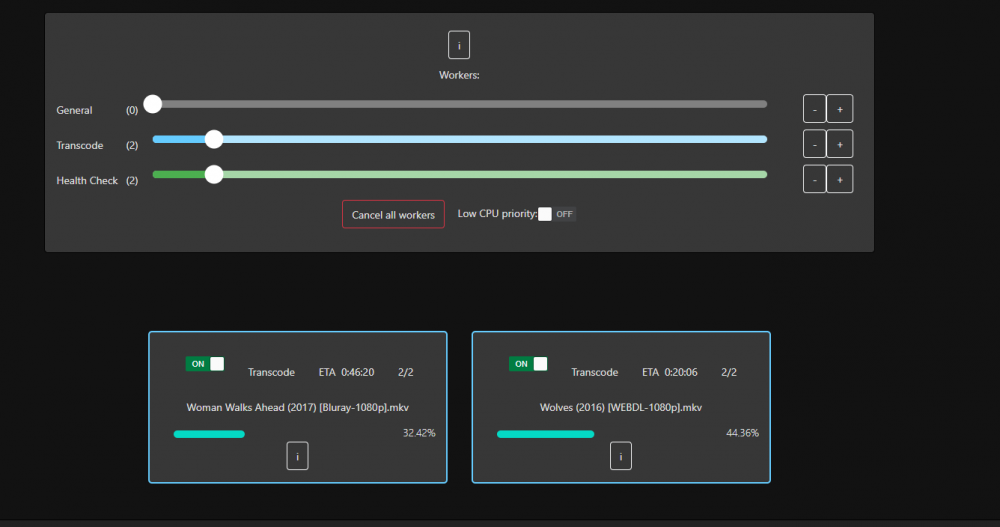
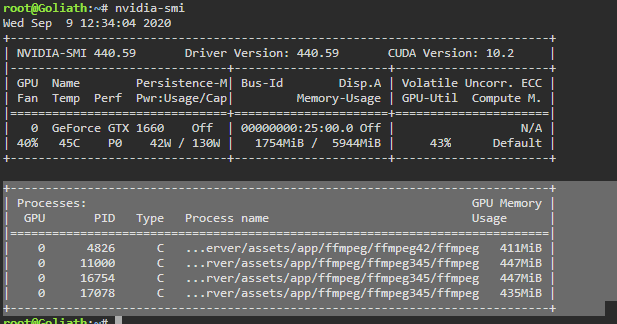
I have two threads enabled for transcode and two health check. There are currently 4 processes running, two of them are movies that are now in the Transcode: Error/Cancelled column. Both of them say "Item was cancelled by user."
I'm attaching some screenshots from the time I noticed this.
Here are the processes:
17078 100 1.3 5729580 459948 ? Rl 06:38 355:59 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/XX (2017)/XX (2017) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/XX (2017) [Bluray-1080p]-TdarrCacheFile-u9gUbCn-z.mkv
4826 100 1.2 5712284 422596 ? Rl 05:11 444:04 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg42/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Young Ones (2014)/Young Ones (2014) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/Young Ones (2014) [Bluray-1080p]-TdarrCacheFile-_olUQbBMe.mkv
16754 21.9 1.4 5812736 492792 ? Sl 12:33 1:13 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Wolves (2016)/Wolves (2016) [WEBDL-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -map -0:a:0 -c:s copy -map -0:s:0 -max_muxing_queue_size 4096 /home/Tdarr/cache/Wolves (2016) [WEBDL-1080p]-TdarrCacheFile-6mulRpdAg.mkv
11000 13.7 1.5 5821572 494684 ? Sl 12:29 1:18 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Woman Walks Ahead (2017)/Woman Walks Ahead (2017) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/Woman Walks Ahead (2017) [Bluray-1080p]-TdarrCacheFile-dN0kys-vG.mkv
-
59 minutes ago, nicksphone said:
Which version are you running Tdarr or Tdarr_aio? what plugin are you using? can i get a screen shot of your docker config and the data from the info tab for one of these glitched transcodes plz also in the options tab do you have
Auto-cancel stalled workers: ON
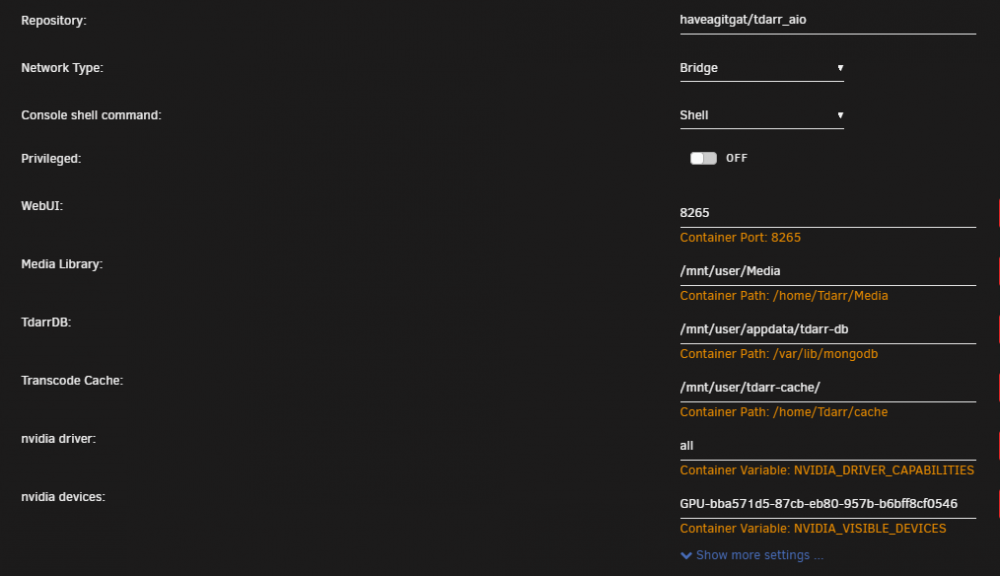
I'm using tdarr_aio. I am running two plugins, Migz-Order Streams and DOOM Tiered H265 MKV. Attached a screen grab of the docker config. I will wait and see if/when this happens again and send the info tab while its happening if possible. Otherwise, when I recover all they ever say is "
Item was cancelled by user". I have both Auto-cancel stalled workers and Linux FFmpeg NVENC binary (3.4.5 for unRAID compatibility) set to ON.
Last night I completely uninstalled/removed the tdarr docker and reinstalled everything starting fresh. So far it is running without issue, we'll see if it lasts.
-
Hey all.
I posted about this on the subreddit for tdarr but figured I would post here as well. At this point I’m not running tdarr because of the problem I am having.
Every few days or so I run into an issue where tdarr spawns a ton (20-30) ffmpeg processes and my server comes to a crawl.
When this happens I have to shutdown my server hard as I can’t seem to get it back when it’s pegged at 100%. When I get tdarr back running there’s a bunch of new “cancelled by user” items in the cancelled column. Like those were the ones transcoding and they never finish.
I have tdarr set to do two transcode threads and two health check.
Here is a screen cap to the process list when one of these situations occurred.
-
52 minutes ago, trurl said:
Why are you running mover every 3 hours?
Why were you running a correcting parity check? Did you have sync errors?
I used to have a much much smaller SSD as my cache drive (200GB), I ran the mover often to keep some room on the cache for downloads, etc. I just never changed this behavior because it has never been a problem.
My scheduled parity check does not do parity corrections. It's possible the auto parity check after an unclean shutdown does? I'm not 100% certain on the behavior of that.
39 minutes ago, Frank1940 said:You should also read this post from LimeTech:
https://forums.unraid.net/topic/49598-unraid-server-release-620-rc4-available/#comment-487759
Dual parity calculation is a major CPU hog for any CPU that does not have the AVX2 instruction set. I don't think yours does.
Thanks for this! Indeed it looks like it does not. I might just drop back down to single parity until I upgrade hardware in the future.
-
Sorry I meant to attach it and completely forgot.
-
Hello all,
I recently moved to dual parity with 2x 10TB drives. My first monthly parity check began yesterday morning. I noticed when I returned from work that I could not access any of my dockers or the webgui. I tried to access the server via SSH but that failed as well. Pings were also timing out. I did notice that all of the activity LED's were active on the HDD's as if the parity check was still underway. I forced the server down and rebooted, which kicked off another parity check of course. I let this go a while and all seemed well. Until this morning. The parity check was at around 35% and the dockers were really slow to respond and would often time out. The webgui was having the same problem and file transfers to or from the array would not complete. I tried to grab a 2GB file copied to my desktop and it started at full speed and slowed to 0bps.
Before cancelling the parity check I stopped all of my dockers, this did not help. I stopped the parity check and that cleared everything up. What should I be looking at here? Any suggestions would be appreciated.
Thanks!
-
Thanks for your help!
-
Well that explains that. I can move the drive(s) that are connected to it to free slots on the H310. Is there a 2 port SATA3 card that is recommended to replace it?
-
Looks like it is. This is the card. One of the reviews states the card has a Marvell 88SE9128.
https://www.amazon.com/gp/product/B003GS8VA4/ref=oh_aui_search_detailpage?ie=UTF8&psc=1And this is from my diagnostics. Marvell no bueno?
04:00.0 SATA controller [0106]: Marvell Technology Group Ltd. 88SE9128 PCIe SATA 6 Gb/s RAID controller [1b4b:9128] (rev 20)
Subsystem: Marvell Technology Group Ltd. 88SE9128 PCIe SATA 6 Gb/s RAID controller [1b4b:9128]
Kernel driver in use: ahci
Kernel modules: ahci -
Hi All,
Looking for some help with an issue. I searched around here a bit and couldn't find anything specific to what I am seeing, but if there is something out there, please forgive me and point me in the right direction please.
I am having an issue that has occurred since the beginning of the year. I have been having an issue with parity sync and have been getting 5 sync errors every other month or so, then I correct them usually after I confirm they are there, and then wont see them for a month or so and then they come back. And they are always in the same sectors. I started tracking the sector a few months ago and copied them off into a separate text file to keep. Below are the details. Current state of my server is, I just within the past two weeks transferred all hardware from a Antec 900 with three 5in3 cages to a norco 4224. So all cables, back planes, caddies, etc are all different since the last time I saw the sync errors. If it was memory I would think it would be at different sectors right? Could it be bad sectors on a single drive? What do I need to do? Long SMART test on each drive? All the SATA cards stayed the same, I have a Dell PERC H310 and a single 2 port card coupled with my 6x on board ports currently in use. When I moved to the norco chassis I added an additional H310 but it is currently not in use.
As you can see here, I will get the sync errors, run again with correct again, they get corrected and then i get a month or more of no errors and then they return.
2018-09-21, 14:34:05 19 hr, 35 min, 41 sec 113.4 MB/s OK 0
2018-09-18, 08:56:43 20 hr, 49 min, 55 sec 106.7 MB/s OK 5
2018-08-02, 01:59:33 23 hr, 59 min, 32 sec 92.6 MB/s OK 0
2018-07-01, 22:05:41 20 hr, 5 min, 40 sec 110.6 MB/s OK 5
2018-06-01, 20:42:18 18 hr, 42 min, 17 sec 118.8 MB/s OK 0
2018-05-21, 15:50:31 18 hr, 29 min, 50 sec 120.2 MB/s OK 5
2018-05-19, 04:26:08 18 hr, 37 min, 32 sec 119.3 MB/s OK 5
2018-05-18, 01:45:21 18 hr, 44 min, 55 sec 118.6 MB/s OK 0
2018-05-01, 19:08:03 21 hr, 34 min, 27 sec 103.0 MB/s OK 0
2018-04-29, 15:57:07 21 hr, 7 min, 35 sec 105.2 MB/s OK 0
2018-04-28, 16:28:48 20 hr, 49 min, 35 sec 106.7 MB/s OK 0
2018-04-27, 18:42:46 20 hr, 42 min, 24 sec 107.3 MB/s OK 5
2018-04-01, 22:57:58 20 hr, 57 min, 57 sec 106.0 MB/s OK 0
2018-03-03, 03:38:01 20 hr, 55 min, 32 sec 106.2 MB/s OK 5
2018-03-01, 23:02:53 21 hr, 2 min, 52 sec 105.6 MB/s OK 5
2018-02-03, 02:48:41 20 hr, 43 min, 30 sec 107.2 MB/s OK 5
2018-02-01, 22:46:09 20 hr, 46 min, 8 sec 107.0 MB/s OK 5
2018-01-01, 23:16:40 21 hr, 16 min, 39 sec 104.5 MB/s OK 5In July I started tracking the sector of the errors.
Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151176
Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151184
Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151192
Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151200
Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151208Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151176
Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151184
Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151192
Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151200
Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151208Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151176
Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151184
Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151192
Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151200
Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151208Any ideas? Any help here would be appreciated.
-
FWIW...
I have purchased 7 of these EasyStore drives now over the last 8 months. The price has been between $180 and $130 when on sale depending on the model (NESN or NEBB). I have 5 RED drives and 2 "white" label drives. Everything on these drives is exactly the same. I even have 3 different model numbers. WD80EFZX, WD80EFAX, and WD80EMAZ. The only 2 differences I have noticed are the WD80EFZX drive actually shows the helium level stat while the other two models say unknown attribute. Even though it is attribute #22 on all the drives and shows the same number, etc. The other being the same drive also only has 128MB cache and the others have 256MB. All the drive info like firmware, etc is the same. There is no doubt on my mind that the white label drives are relabeled RED drives. These drives are totally worth picking up. You can preclear before shucking if you are worried about them. I have done that with two of them just because of ease.
-
 1
1
-
-
I did this exact migration myself and it was smooth. Backup the folder you have your Plex app in stalled in. I simply copied everything in what was for me //appdata/plex over to the array just in case. The copy will take a while since there are hundreds of thousands of small files that make up the meta data, but it's worth it for that piece of mind IMO.
After that is complete, I took a screen shot of the settings page of the Phaze plugin and disabled it. Then went to the docker settings for Plex and just matched all my path and port settings exactly. There are a couple of extra mappings required in the docker if im not mistaken but im at work right now and can't look to see what they are. As long as you point to the right place for the app folder and set your media mappings correctly, you should be fine. I started the docker and everything was just there. The only cleanup I had to do was after it was running for a while I had duplicate server entries in PlexPy.
-
I only had one PC to test it with and that is my main desktop. I do not have an extra slot in my unraid server and didn't really want to introduce it if I wasn't sure it was working. I am returning it to the seller and bought another one from another vendor on ebay. Hopefully the 2nd one is good.
Is there a set guide to do this process? I found several different sets of steps here and everyone seems to do it a little differently.
-
Hey guys,
So I ordered a Dell PERC H310 off of ebay and got it today. I am trying to flash it to IT mode but so far none of the commands have provided the results I expect.
I am following the instructions in the readme file provided through the 1st step in instructions here: http://lime-technology.com/forum/index.php?topic=12767.msg259006#msg259006
When I run 1.bat which should write the SAS address to a text file, i get nothing returned and the text file only has Exit Status:0x01 in it. When I try to display an adapter count it says 0 but if i list all there is 1 there.
If I boot into windows, the adapter is listed in device manager but the says there was a hardware I/O error. I suppose that may be normal?
Any help anyone can provide here would be great. I have never done this before. Is it DOA maybe?
Also, the LED on it is blinking slowly, if that means anything.
Thanks
-
8TB Drives
in Lounge
Sorry, US. I'm not against paying the current rate of $250 or so for the drive, just sucks when I paid $215 a couple months ago for the same drive. I was just curious if there were sources I didn't know about out there that may still have a better price. I have checked Amazon, newegg, and even some ebay.
-
8TB Drives
in Lounge
Not sure where this should go, but it didn't seem to fit in any of the other forums.
Anyone have a good source for 8TB drives? I really like that size and was moving to them exclusively, but the price has jumped $50 or so on any source I can find and Amazon is back ordered.
Thanks!
-
That kind of fixed it. I was able to approve the request and now some searches are failing with the same error for shows I know exist. Seems Movies work fine, haven't had any fail. Shows are hit or miss. I can search for a couple that will work fine and a few will fail. The log errors are all the same as listed above.
-
I got this installed and everything appears to be working. When I go to approve a TV request, it fails with an error. In the logs I see an error that appears to have a time stamp around when the request was made "TVMAZESearch Error -> Cannot read property 'medium' of null". Any ideas what is causing this?
-
I too am slightly inconvenienced by waiting for drives to spin up for recent media. But only slightly!
One option I can think of is to set the mover to run less frequently, perhaps weekly on an off-day that works best for your favorite shows airing schedules. That does compromise your data, since it would be sitting on your cache drive longer and not parity protected followed by taking up costly precious SSD space.
Right. I mentioned that in my last reply. I can change the default mover script to run less often, that would help. And with cache pools being protected, that would solve the problem with potential for data loss.
When you say you have to wait because of the delay you talking minutes or seconds? When I click a video using Kodi aka XBMC I normally wait what "feels like" 5 seconds on a spun down disc. To me the 3-5 seconds feels reasonable seeing it had to spin up disc.
You are also correct, the amount of time is very very small. A few seconds only. This is why in my original post I tried to make it clear that I wasn't really complaining, I am very happy with unRAID, Plex, and my overall experience with everything. I have no problem waiting those few seconds for a disk to spin up. I was just thinking of something cool to do with some of the new features that have been added to unRAID recently.
I only recently (past 6 months or so) switched from a 2TB 7200rpm drive for my cache disk to an SSD. The difference this made with my apps like Plex was absolutely incredible. The amount of time it takes to load the metadata is night and day, especially on the smaller libraries. Seeing that difference is what got me thinking about other small changes that could be done to speed up the experience just enough to notice. My Movies library still is pretty sluggish when scrolling down through stuff further down in it. I think its somewhere around ~2k movies now. I probably should break it up to make it faster. I still dont fully understand how btrfs cache pools deal with the data, so trying to figure that out fully before i decide if i want to do it. If it stripes data like a traditional raid5, maybe that would help a bit with this. But thats a different topic.
-
Search for "accelerator drive". See search tips in my sig.
Thank you! This is pretty much exactly what I am thinking.
I'm a little confused why you're having issues with delays in starting videos in Plex. The only time I have a delay is when my videos are on a spun-down disk. When the videos are on the cache, play starts immediately.
My videos tend to download between 2am to 5am, so I have my Mover scheduler set to move my videos to the array at 1am. This way, my evening's viewing tend to come off the cache drive, which as I said is instant.
Yeah, the same situation applied for me. However, most of the time I do not watch the shows the night they air. So for example GoT is on at 10PM EST. I get it downloaded around 11:30PM EST. It moves to a disk and is spun down when I go to watch it, I notice this delay. Obviously given the protection offered by btrfs cache pools now, an easy solution to this is simply to change my mover settings to every other day? Or maybe even a week depending on how big of a cache pool I had. That would solve this pretty easily.
-
I'm putting this in the lounge because i'm not sure where else to put it. Also, please don't take any of this as a complaint, none of this is is intended as such.
I, like many others here, primarily use my unRAID server for media. I run Plex with Sonarr and SABnzbd for my media management. I love the setup and the ability to add a show and never have to manage it again, assuming everything continues to run the way it is intended without any hiccups, which is usually does. I also, do not have cable tv, i cut the cord a long time ago and love it. That's the background.
One of the small things I notice when watching media on Plex is there is a noticeable delay when loading something that has recently downloaded and not yet moved to the array and is on the cache drive, vs something on the array and the disk has to spin up, etc. Now this is where my first paragraph comes into play. This amount of time is a few seconds probably and is not a big deal. But it is noticeable, as is the seek time if I want to skip around in the episode or movie. Obviously in the past getting stuff off of the cache drive quickly in order to get it protected was desirable. But now with the cache pool feature, this may have changed some. I have not yet implemented a cache pool myself and currently use a 850 EVO as my cache disk. From what I have read here, there are a few options with the BTRFS cache pool. Please correct me if i am wrong but, RAID1, RAID10, and RAID5?
My initial idea was to use a RAID5 setup for the cache pool. Then I could set my media folders to be ignored by the default mover script so they would stay on the cache drive. I could create a custom mover to check the watched status of the media in the plex database and move the file to the array if it has been watched, or leave it otherwise. I have not played with this idea yet, I don't even know if it would work or if it is a waste of time, just an idea. Also, this gets more complicated when you add additional users, and I share my Plex with a half dozen or so people.
The next idea was to do the same thing basically only have it based on when the media was added to the library. So maybe Added + x number of days. So maybe 30 days of Media stays on cache?
Again, I don't even know if this is possible? Worth it? Dumb idea? Just something I was thinking about.
-
While my method is by no means the best, it works for me quite well. 99.9% of what is on my unRAID box is media, so I can afford to lose it in the worst case scenario, but I'd rather not. And I can replace most of it. Anything that is personal data like pictures, documents, etc i keep backed up in google docs, or dropbox, etc. I generally fill my disks on the server to the point where they have 100GB or less available before I expand (10 data drives currently so this still lives quite a bit of free space across the array). About once a month or so, I dump the directory contents of each disk to a .txt file and save it to google docs. My logic is if I ever did have a scenario where I lost multiple disks or some form of severe data corruption were to occur, I would have a record of what I lost and be able to replace it. It would be a pain in the butt yes, and time consuming to re-download all the media, but at least I would be able to see what was there. It would be cool if there was a plug in or docker method for something like this actually, that would be awesome. I have never automated it myself, even though I have thought about it, probably wouldn't be too hard to do.
-
Should I skip the 2nd nocorrect check and maybe run extended smart tests on my other data drives to ensure they are healthy?






Question about parity errors
in General Support
Posted
Ok, I think I know how to proceed but I wanted the opinion of others before I do anything.
I do the auto parity check once a month on the first (without corrections). Since my last check February 1st I had a stick of memory go bad. I caught it quickly because of other issues I was having and replaced it.
Fast forward to March 1st and I have 12 errors. I assume these are thanks to my bad memory.
My thoughts are to run another check (again without corrections) verify the errors are the same as the first pass and if they are, let the check correct the errors.
Am I off here?
Thanks!!