




swells
Members
-
Joined
-
Last visited
-
Ok, I think I know how to proceed but I wanted the opinion of others before I do anything. I do the auto parity check once a month on the first (without corrections). Since my last check February 1st I had a stick of memory go bad. I caught it quickly because of other issues I was having and replaced it. Fast forward to March 1st and I have 12 errors. I assume these are thanks to my bad memory. My thoughts are to run another check (again without corrections) verify the errors are the same as the first pass and if they are, let the check correct the errors. Am I off here? Thanks!!
-
Yeah, I was just coming here to say I think I have tracked the issue to the "Auto-cancel stalled workers" option being on. I turned it off last night and have not had an issue since. I have had a few fail, most are .ts or .m2ts. Thanks for the help!
-
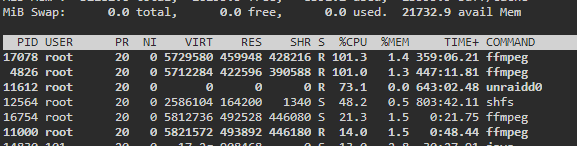
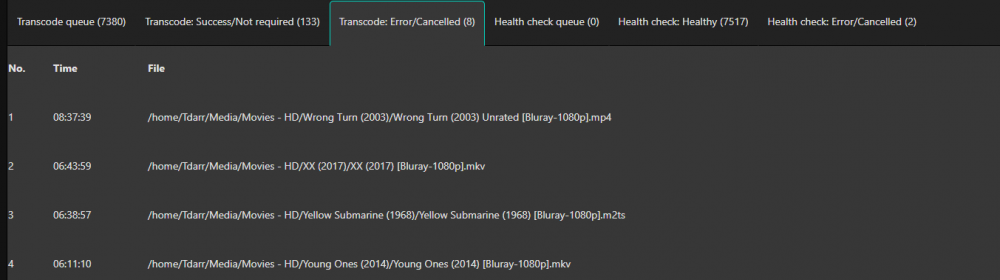
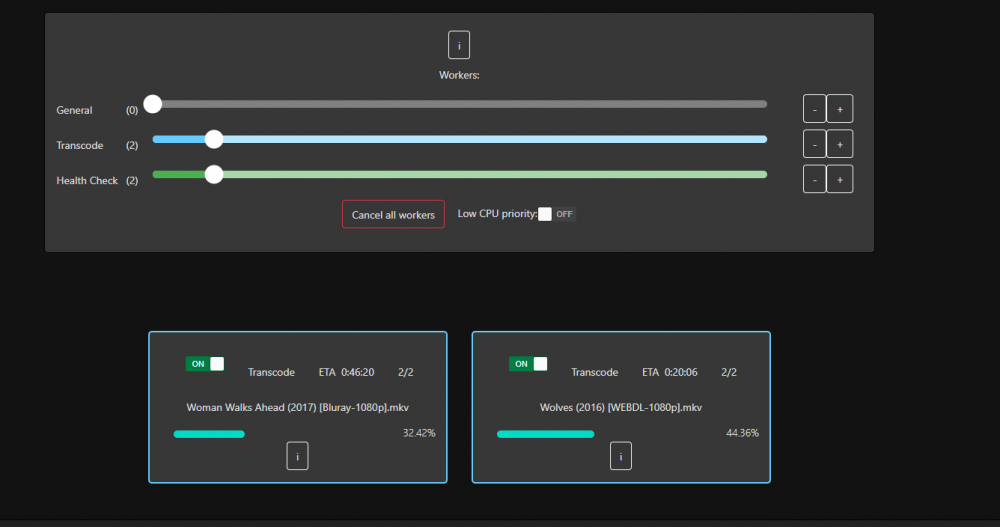
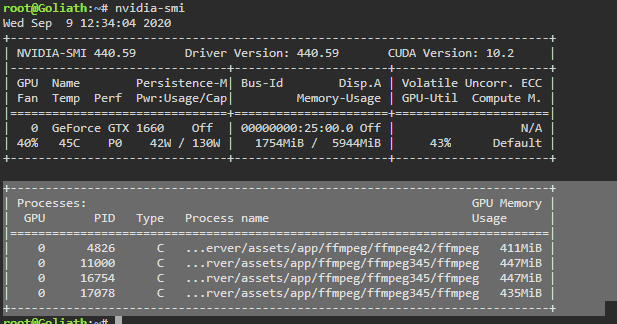
Ok it started happening again this today and I was able to catch it early. I have two threads enabled for transcode and two health check. There are currently 4 processes running, two of them are movies that are now in the Transcode: Error/Cancelled column. Both of them say "Item was cancelled by user." I'm attaching some screenshots from the time I noticed this. Here are the processes: 17078 100 1.3 5729580 459948 ? Rl 06:38 355:59 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/XX (2017)/XX (2017) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/XX (2017) [Bluray-1080p]-TdarrCacheFile-u9gUbCn-z.mkv 4826 100 1.2 5712284 422596 ? Rl 05:11 444:04 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg42/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Young Ones (2014)/Young Ones (2014) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/Young Ones (2014) [Bluray-1080p]-TdarrCacheFile-_olUQbBMe.mkv 16754 21.9 1.4 5812736 492792 ? Sl 12:33 1:13 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Wolves (2016)/Wolves (2016) [WEBDL-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -map -0:a:0 -c:s copy -map -0:s:0 -max_muxing_queue_size 4096 /home/Tdarr/cache/Wolves (2016) [WEBDL-1080p]-TdarrCacheFile-6mulRpdAg.mkv 11000 13.7 1.5 5821572 494684 ? Sl 12:29 1:18 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Woman Walks Ahead (2017)/Woman Walks Ahead (2017) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/Woman Walks Ahead (2017) [Bluray-1080p]-TdarrCacheFile-dN0kys-vG.mkv
-
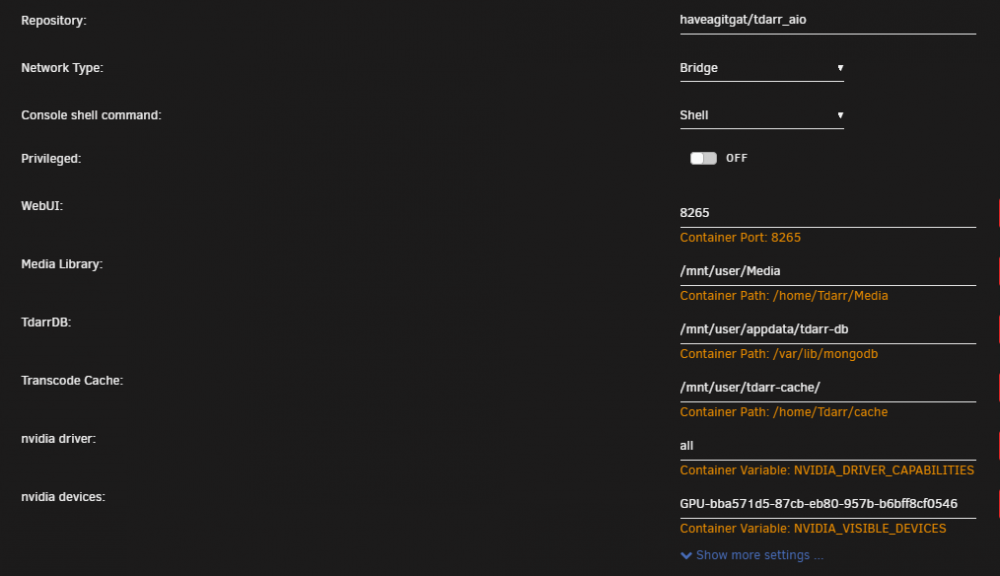
I'm using tdarr_aio. I am running two plugins, Migz-Order Streams and DOOM Tiered H265 MKV. Attached a screen grab of the docker config. I will wait and see if/when this happens again and send the info tab while its happening if possible. Otherwise, when I recover all they ever say is " Item was cancelled by user". I have both Auto-cancel stalled workers and Linux FFmpeg NVENC binary (3.4.5 for unRAID compatibility) set to ON. Last night I completely uninstalled/removed the tdarr docker and reinstalled everything starting fresh. So far it is running without issue, we'll see if it lasts.
-
Hey all. I posted about this on the subreddit for tdarr but figured I would post here as well. At this point I’m not running tdarr because of the problem I am having. Every few days or so I run into an issue where tdarr spawns a ton (20-30) ffmpeg processes and my server comes to a crawl. When this happens I have to shutdown my server hard as I can’t seem to get it back when it’s pegged at 100%. When I get tdarr back running there’s a bunch of new “cancelled by user” items in the cancelled column. Like those were the ones transcoding and they never finish. I have tdarr set to do two transcode threads and two health check. Here is a screen cap to the process list when one of these situations occurred. https://imgur.com/a/qeQ80Rq
-
Quick question... I just added this to my unRAID install. It is working perfectly except for one detail. I have some files that are more than 5 folders deep. Which numbers in the go script do i need to edit? Both of the 5's or just one of them? My current structure is below, I just need to up it to 6 i believe. Media>TV>Completed>Show>Season>Episodes The 'episodes' is the actual video files within the Season X folder, not another folder. I thought that would technically be 5 levels deep but the drives were spinning up when i got this deep. I added the line listed in the wiki to my go script so it looks like.... /boot/cache_dirs -d 5 -m 3 -M 5 -w Thanks guys!




