

1trkmind
-
Posts
21 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by 1trkmind
-
-
Thanks guys. Unraid is so picky compared to windows on disk health 😉
-
3 hours ago, johnnie.black said:
Extended SMART test failed = failed disk
SMART Extended Self-test Log Version: 1 (1 sectors) Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 10% 28170 5845199728The overall result of the test is a "Pass". (SMART overall-health self-assessment test result: PASSED)
Are you saying that if any individual test component fails, the entire disk is bad?
-
Hey all.
I upgraded my 3tb parity disk with a 10tb disk. Then used the old parity drive to replace a smaller, older disk5.
I'm now getting SMART errors on disk5 (the old parity drive).
I ran the extended test, but I'm not familiar with the errors enough to know if I should be concerned or not. Lots of "power-on lifetime" errors and it's a WD drive, I heard they get a lot of errors that other drives do not.
My biggest concern is being able to rebuild if any drive fails.
Tonight I'll probably scatter all the data off disk5 until I know what the disk needs.
Any help is appreciated.
extended-smart-test-disk5.txt doctorhands-diagnostics-20200427-1703.zip
-
2 hours ago, Squid said:
0a:00.0 SATA controller [0106]: Marvell Technology Group Ltd. 88SE9230 PCIe SATA 6Gb/s Controller [1b4b:9230] (rev 11)
Marvel based controllers are problematic at best. Don't use those 4 ports on the motherboard.
You were 100% correct. I moved the 2 disks to different ports and the upgrade worked seamlessly!
Thanks for the help and fast response!
-
The Problem:
I'm running Unraid 6.8.3 and haven't been able to successfully upgrade to any version.
After an upgrade reboot, Disk 2 and Disk 3 are "Missing".
I can easily FTP the bz files to restore Unraid 6.8.3 and the disks have no issues. All functionality is restored.
What I've Tried:
Unplugged all hardware from the server excluding 3 network cables.
Uninstalled every plugin.
Upgrading to several different stable versions of Unraid.
Attached:
Screenshot of the issue after reboot.
Diagnostics after upgrade and BEFORE reboot.
Diagnostics after upgrade and AFTER reboot.
Any help is appreciated.
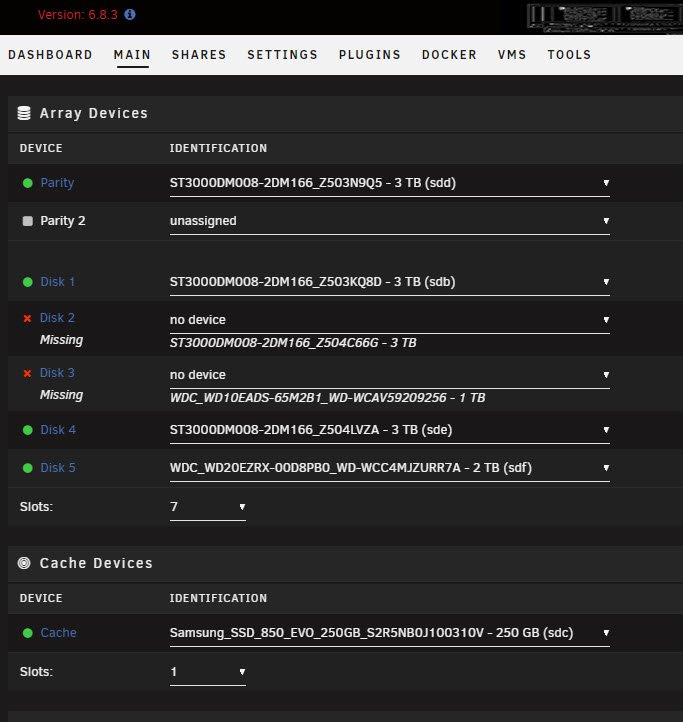
beforeReboot-diagnostics-20200409-1018.zip afterReboot-diagnostics-20200409-1051.zip
-
16 hours ago, jonathanm said:
de-berlin working well at the moment.
After swapping the ovpn file, is there additional steps to restarting the docker for the change to take effect?
-
36 minutes ago, TBoneStaek said:
What server are you trying to connect to? Canada has been down. Can you access your Deluge GUI? I couldn't because of this issue.
Try disabling STRICT-PORT_FORWARD, put "no" and then change VPN_ENABLED back to "yes". If that works, it's the port forwarding issue that I and others have been having.
I've tried several endpoints. Deluge won't load for me with vpn = yes and strict forward = no for any endpoints. No worries, I'll just turn off the vpn for now and give PIA some time to push a fix.
-
I woke up this morning and Sonarr, Radarr, Lidarr lost connectivity to their indexers. Yesterday I upgraded my modem to Arris SB8200 and did not touch any router settings. Currently, my docker containers route through delugeVPN using PIA for NZB only (which all worked for many months until today). I was able to remedy the connection issue by setting VPN_ENABLED = no in the deluge settings.
The only changes made to my setting or network is the new modem which uses docsis 3.1
Can't think of a reason why a new router would cause the VPN feature to stop working.
I am running an old version of Unraid 6.6.7. Can't seem to upgrade successfully with my build. But, again this has been my setup for a very long time without issue.
All dockers are up to date.
I have attached my deluge settings and the sonarr log when trying to test the connection to an indexer.
I'm not sure which logs would be most valuable.
Any help is appreciated.
Thanks!
**** Just Read All the Posts ****
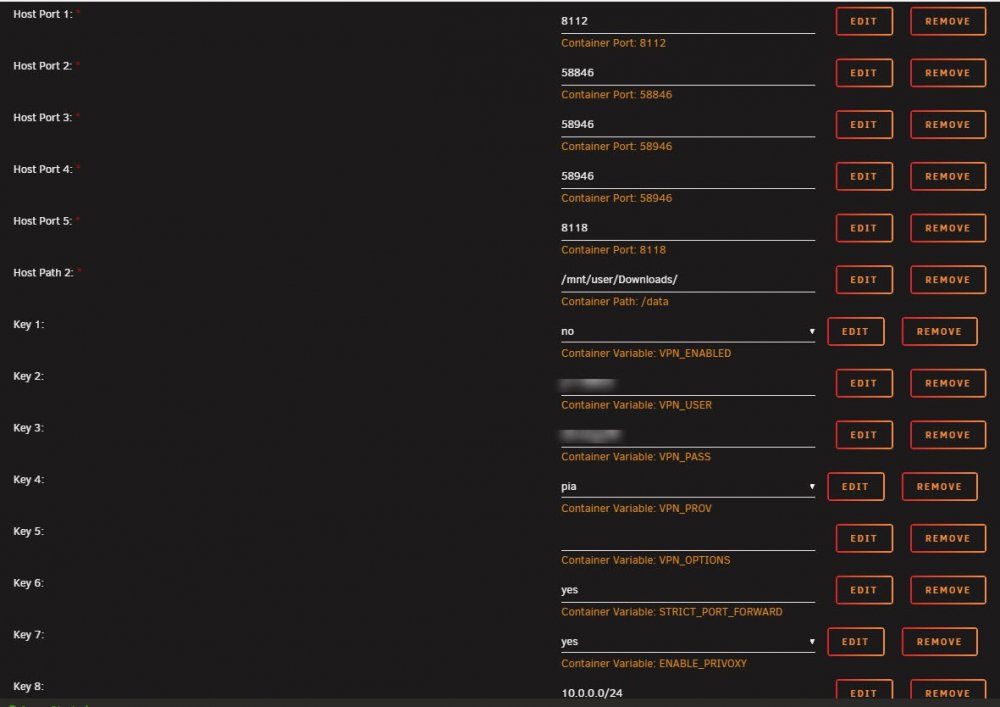
-
Hey guys. I'm running Unraid 6.4.0. I use eweka.nl and have DOGnzb, Nzb.su, and NZBgeek for indexers. I recently changed from binhex-sabnzbd to the binhex-sabnzbdvpn docker and use PIA as my VPN provider. Everything worked at the onset, but after a day all of my indexers for sonarr, lidarr and radarr were disconnected. at any time I'm able to click on them and run a connection test and they all would validate and connect. But, eventually they all lose the connection again. It seems like after so many requests to the indexers, they're making me validate again. I disabled the vpn and everything works perfectly.
It feels like the provider doesn't like getting requests from whatever IP the vpn is serving me. Maybe a security measure. The logs to sonarr, lidarr and radarr just state that the indexers are unavailable and sonarr gives "Failed to test proxy: http://services.sonarr.tv/v1ping". I didn't see the sabnzbdvpn logs while the error was happening and in my troubleshooting of turning off the vpn the logs have cycled through.
I didn't see anything about this searching the web and forums, but I have to imagine it's happened before.
Any help is appreciated.
Thanks.
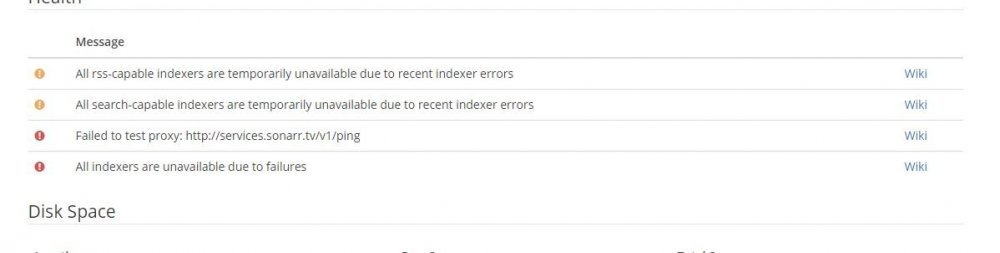
-
@SoAvenger Thanks for getting the fix and detailed explanation up so quickly! I had the same issue, same fix.
-
 1
1
-
-
Thanks in advance, I love all your work! Having a strange issue, seems like I lost my style sheets and all of the sites icons are large and can't be navigated. I have removed the docker with and without the image then reinstalled to no avail. Running Unraid 6.3.5. I attached a sample of the home page. There's some (error=430) for @news.eweka.nl besides that the only error in the log is:
2017-08-07 17:51:54,047::INFO::[_cplogging:219] [07/Aug/2017:17:51:54] ENGINE Bus STARTING
2017-08-07 17:51:54,051::INFO::[_cplogging:219] [07/Aug/2017:17:51:54] ENGINE Started monitor thread '_TimeoutMonitor'.
2017-08-07 17:51:54,288::INFO::[_cplogging:219] [07/Aug/2017:17:51:54] ENGINE Serving on https://0.0.0.0:8090
2017-08-07 17:51:54,296::ERROR::[_cplogging:219] [07/Aug/2017:17:51:54] ENGINE Error in HTTPServer.tick
Traceback (most recent call last):
File "/opt/sabnzbd/cherrypy/wsgiserver/__init__.py", line 2024, in start
self.tick()
File "/opt/sabnzbd/cherrypy/wsgiserver/__init__.py", line 2091, in tick
s, ssl_env = self.ssl_adapter.wrap(s)
File "/opt/sabnzbd/cherrypy/wsgiserver/ssl_builtin.py", line 67, in wrap
server_side=True)
File "/usr/lib/python2.7/ssl.py", line 363, in wrap_socket
_context=self)
File "/usr/lib/python2.7/ssl.py", line 611, in __init__
self.do_handshake()
File "/usr/lib/python2.7/ssl.py", line 840, in do_handshake
self._sslobj.do_handshake()
error: [Errno 0] Error
I've attached some images to show the errors I'm having.
Any advice is appreciated.
Thanks!
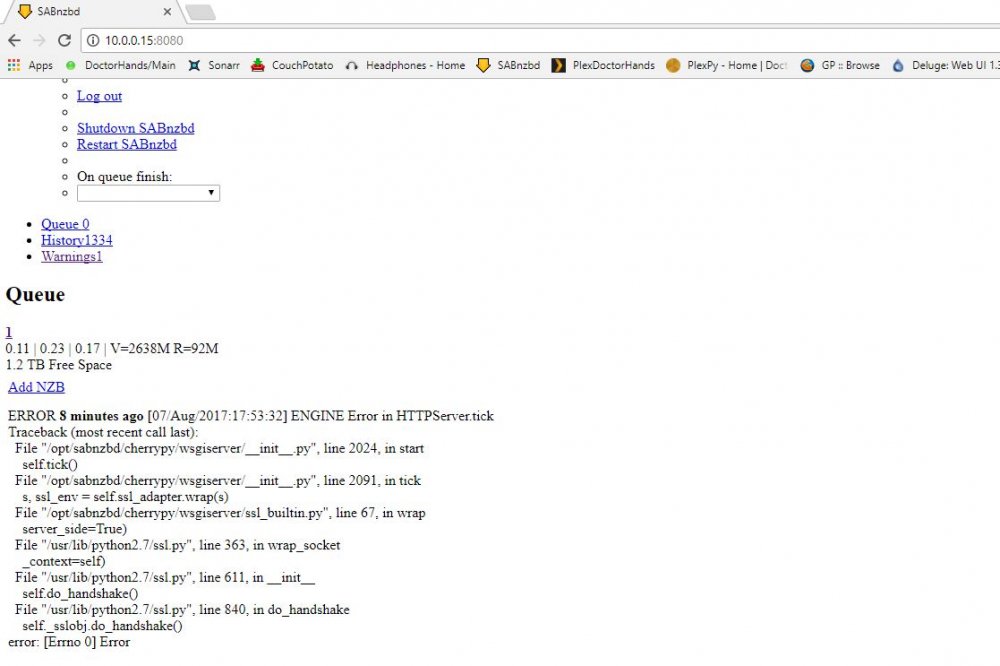
-
13 hours ago, aptalca said:
Did you try to connect to https://yourip:943/admin ? Or click on the webui link in the unraid gui?
I have tried both
-
9 hours ago, wgstarks said:
You have to be on a desktop machine also. Signatures aren't visible on mobile devices.
Run Command:
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="openvpn-as" --net="host" --privileged="true" -e TZ="America/New_York" -e HOST_OS="unRAID" -e "TCP_PORT_943"="943" -e "PGID"="100" -e "PUID"="99" -v "/mnt/user/appdata/openvpn-as":"/config":rw linuxserver/openvpn-as
391cfd36c41dc10bab165adf7b89d1112e53e87cb022564463d55459c05e4905The command finished successfully!
OpenVPN-as Log:
ErrorWarningSystemArrayLogin
[s6-init] making user provided files available at /var/run/s6/etc...exited 0.
[s6-init] ensuring user provided files have correct perms...exited 0.
[fix-attrs.d] applying ownership & permissions fixes...
[fix-attrs.d] done.
[cont-init.d] executing container initialization scripts...
[cont-init.d] 10-adduser: executing...
-------------------------------------
_ _ _
| |___| (_) ___
| / __| | |/ _ \
| \__ \ | | (_) |
|_|___/ |_|\___/
|_|
Brought to you by linuxserver.io
We gratefully accept donations at:
https://www.linuxserver.io/donations/
-------------------------------------
GID/UID
-------------------------------------
User uid: 99
User gid: 100
-------------------------------------
[cont-init.d] 10-adduser: exited 0.
[cont-init.d] 20-time: executing...
Current default time zone: 'America/New_York'
Local time is now: Fri Mar 31 06:19:27 EDT 2017.
Universal Time is now: Fri Mar 31 10:19:27 UTC 2017.
[cont-init.d] 20-time: exited 0.
[cont-init.d] 30-config: executing...
[cont-init.d] 30-config: exited 0.
[cont-init.d] 40-openvpn-init: executing...
[cont-init.d] 40-openvpn-init: exited 0.
[cont-init.d] 50-interface: executing...
MOD Default {} {}
MOD Default {} {}
MOD Default {} {}
MOD Default {} {}
[cont-init.d] 50-interface: exited 0.
[cont-init.d] done.
[services.d] starting services
[services.d] done.I hope this helps, thanks again.
-
12 minutes ago, CHBMB said:
See my signature.
huh?
-
17 hours ago, CHBMB said:
Post your docker run command.
Sorry, I'm new to unraid and dockers, I'm not sure what that mean.
I'm not running anything from the terminal, just from the docker section of unraid.
Is there a log I can pull the command from?
Edit:
Here is the docker install log:
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="openvpn-as" --net="host" --privileged="true" -e TZ="America/New_York" -e HOST_OS="unRAID" -e "TCP_PORT_943"="943" -e "PGID"="100" -e "PUID"="99" -v "/mnt/user/appdata/openvpn-as":"/config":rw linuxserver/openvpn-as
xxxxx36c41dxxxxxxx89d1112e53e8xxxxx63d5545xxxxxxxThe command finished successfully!
-
I just installed the docker with host network type and privileged enabled on unraid 6.3.2.
When I try the webui I get: This site can't be reached "ERR_CONNECTION_REFUSED"
What I've tried:
1. ssh into unraid machine created a password for admin (completed successfully)
2. trying chrome and firefox browsers. Also tried launching from the local machine (all same error)
3. forwarded port 943 to the local machine
4. turning off the firewall in my router
Any advice is appreciated.
Thanks.
-
Will do. I ran the test again, it now constantly search for a second superblock which it never finds.
I'm going to format the disk and start over.
-
Thanks. I'm not sure how to get the complete diagnostics. I'll figure it out.
I did these things for disk1:
when I run the Check Disk Filesytem I get the message "superblock read faild, offset 0, size 524288, ag 0, rval -1" fatal error input/output error.
I tried to run xfs_repair -v /dev/md1 in the terminal and got a similar ""superblock read faild, offset 0, size 524288" error.
Is it an issue mounting the drive without having to format it?
-
I'll preface with this with: I'm very new to Unraid and this is the first computer I've every built.
ASRock EP2C602-4L/D16
(2) Xeon E5-2665
Memory *NEW* (4) Crucial Balistx Sport 8g DDR3 [ 32gb total, all being read ]
Parity Drive *NEW* 3tb drive
Disk1 *NEW* 3tb drive [ This is where I stored all of my medial data ]
Disk2 *OLD* 2tb drive [ nothing important on it ]
Disk3 *OLD* 2tb drive [ nothing important on it ]
Disk4 *OLD* 1tb drive [ nothing important on it ]
Cache *NEW* 250Gb Cache
Unraid 6.3.0 Plus - on an adata 16gb flash drive
Installed a bunch of tools and dockers and everything was rocking.
Disk2 failed. I bought another 3Tb drive and replaced the disk. Ran preclear, assigned it to Disk2. I also attached a 3tb drive that had the backup data for disk1. I precleared it, mounted and formatted it then assigned it as disk5. Started the array. The rebuild for Disk2 was taking a very long time. after 12 hours was around 20% complete, speeds were as slow a 1.1kb and estimating 186 days to complete.
I wasn't worried about losing the data on Disk2, so I used the New Config in Tools and did whatever it took Disk2 in as part of the array without having to rebuild. Unfortunately, when I did this using the Unassigned Devices plugin, I must have had a setting wrong, I could not SMB into the drive and had no permissions to access it. I think I neglected to toggle a feature in Unnasigned Devices and the drive was private. I stopped the array, and set Disk2 properly and restart the array. Instead of showing up and Disk2 there was some long string a characters. So I stopped the array and tried again. This is where I really shit the bed! By accident I took down Disk1. Out of fury, after this my memory gets a little hazy. It read that Disk1 (the drive with most all of my media data) and Disk2 were unmountable and needed to be formatted. I believe I "think" is toggled "automount" put them to selected the proper drive to disk1 and disk2 and restarted in Maintenance Mode. Currently, Disk2 looks good and It's attempting to rebuild the data. Estimated to take 72 days at this point. I really don't want to lose the data on disk1. However, I could build it again manually in less than 72 days.
It looks like my old drives disk3 and disk5 are having read errors. I'm will to take them out or even lose the data on them all together if that's whats slowing down the rebuild. The start a new configuration. At this point, all I care about is not losing the data on disk1. Everything else is still backed up on my windows machine.
My other computers are all Windows. I'm considering creating an Ubuntu flash drive, stopping the rebuild, booting from Ubuntu, moving the data to another disk and restarting.
Any help is appreciated, Thanks!







[SOLVED] SMART Disk Errors After Array Size Inrecase
in General Support
Posted
I guess it's time to shuck another 10tb WD Easystore.