





Starlord
Members
-
Joined
-
Last visited
-
So I was able to get this working sending and receiving mail (static ip, ptr record set by my isp, all ports forwarded and working) but I'm having issues getting this working with my nginx reverse proxy.. keep getting a 502 error Here's my proxy conf server { listen 443 ssl; listen [::]:443 ssl; server_name mail.*; include /config/nginx/ssl.conf; client_max_body_size 0; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /login; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_mail mail; proxy_pass http://$upstream_mail:4433; } } and here's the container setup

-
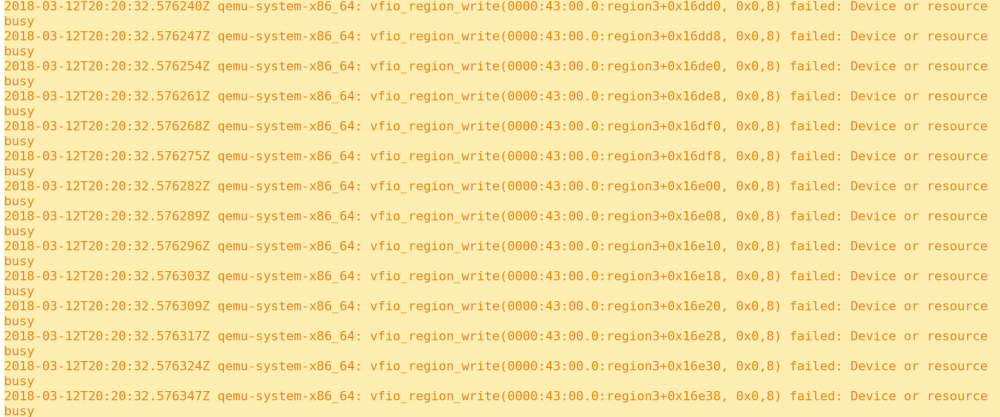
KVM also spits these errors out
-
Is there a reason that you are using the quadro drivers and not the standard geforce ones?
-
Even with everything unplugged I can't get it to post.
-
Stuck with error code 43 passing through my 1080ti with self dumped vbios following the instructions in the first video. Disabled hyper-v with no luck. Also tried modding drivers to no avail Also tried editing the XML to include the kvm hidden state and vendor ID override.
-
I can 100% confirm that this card does not support AMD's x399 chipset due to lack of thunderbolt support. No intel systems to test it on. I just returned it and picked up the PEXUSB3S44V to test and so far haven't even been able to get unraid to boot when devices are plugged into it. Very interested in this thread.


