kno
Members
-
Joined
Everything posted by kno
-
No, it was only on this drive. However many of my drives have high CRC-Error_Count, because of previous problems with older backplanes/drivecages. After I removed those and wired all drives directly, I have had no issues until now. There was no errors on the other drives during this parity check either. I am thinking I should try to switch the wires to this one drive and run a new check (I have a few spare wires on the controller).
-
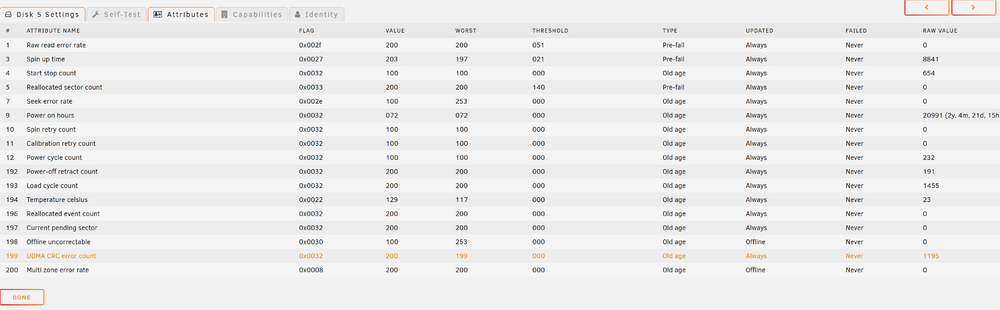
Thank you for the interpretation of the data. A follow-up question then. Shouldn't the UDMA_CRC_Error_Count "raw value" match closer to the numbers of error reported "3968"? I am somewhat familiar with the UDMA_CRC_Error_Count because of failing backplane in drive cages on another occation. The mismach between the raw values and the number of errors was one of the reasons for asking for support from others. Is there anything new for me to learn here?
-
Thank you. I have attached the diagnostics file. tower-diagnostics-20250131-2353.zip
-
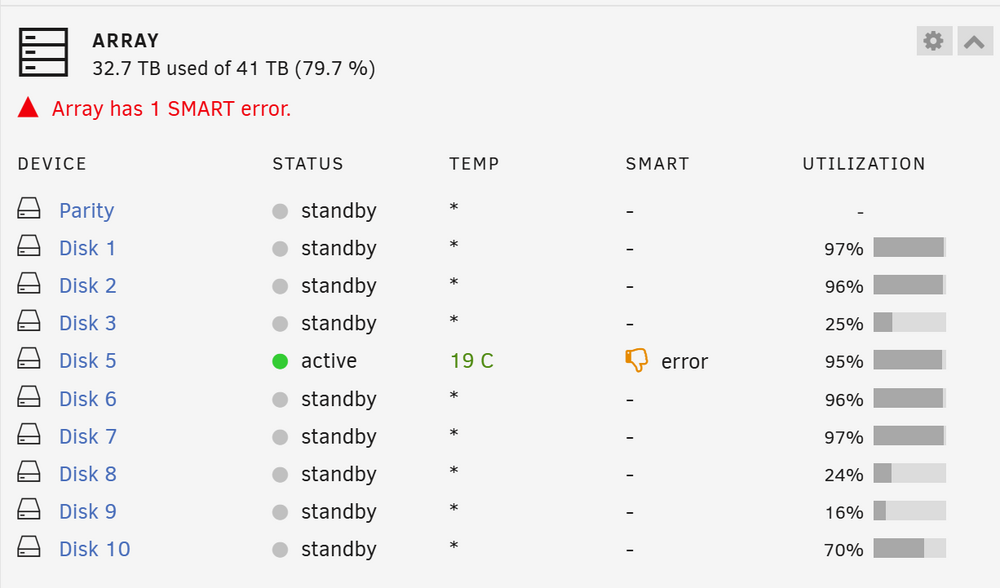
I had an unclean shutdown of my Unraid system because of a power outage. I am sure there was no activity on the server at the time and all HDD's should have been spun down due to no activity for the last days. Once I restarted the Unraid server I ran a parity check just to verify that everything was okay and that the parity was valid. Parity check reported as okay, however one drive (drive 5 in my system) had 3968 errors on it. I am having trouble understanding these errors. How do I identify the problem? I have attached a few screenshots and the SMART report, but I don't really know what I am looking for. Any suggestions? smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.1.106-Unraid] (local build) Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Western Digital Red (CMR) Device Model: WDC WD60EFRX-68L0BN1 Serial Number: WD-WX11D278Z67K LU WWN Device Id: 5 0014ee 2b953eb5d Firmware Version: 82.00A82 User Capacity: 6,001,175,126,016 bytes [6.00 TB] Sector Sizes: 512 bytes logical, 4096 bytes physical Rotation Rate: 5700 rpm Device is: In smartctl database 7.3/5610 ATA Version is: ACS-2, ACS-3 T13/2161-D revision 3b SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s) Local Time is: Fri Jan 31 23:20:32 2025 CET SMART support is: Available - device has SMART capability. SMART support is: Enabled AAM feature is: Unavailable APM feature is: Unavailable Rd look-ahead is: Enabled Write cache is: Enabled DSN feature is: Unavailable ATA Security is: Disabled, NOT FROZEN [SEC1] Wt Cache Reorder: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x00) Offline data collection activity was never started. Auto Offline Data Collection: Disabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: ( 6824) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 2) minutes. Extended self-test routine recommended polling time: ( 722) minutes. Conveyance self-test routine recommended polling time: ( 5) minutes. SCT capabilities: (0x303d) SCT Status supported. SCT Error Recovery Control supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE 1 Raw_Read_Error_Rate POSR-K 200 200 051 - 0 3 Spin_Up_Time POS--K 198 197 021 - 9058 4 Start_Stop_Count -O--CK 100 100 000 - 653 5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0 7 Seek_Error_Rate -OSR-K 100 253 000 - 0 9 Power_On_Hours -O--CK 072 072 000 - 20991 10 Spin_Retry_Count -O--CK 100 100 000 - 0 11 Calibration_Retry_Count -O--CK 100 100 000 - 0 12 Power_Cycle_Count -O--CK 100 100 000 - 232 192 Power-Off_Retract_Count -O--CK 200 200 000 - 191 193 Load_Cycle_Count -O--CK 200 200 000 - 1452 194 Temperature_Celsius -O---K 133 117 000 - 19 196 Reallocated_Event_Count -O--CK 200 200 000 - 0 197 Current_Pending_Sector -O--CK 200 200 000 - 0 198 Offline_Uncorrectable ----CK 100 253 000 - 0 199 UDMA_CRC_Error_Count -O--CK 200 199 000 - 1195 200 Multi_Zone_Error_Rate ---R-- 200 200 000 - 0 ||||||_ K auto-keep |||||__ C event count ||||___ R error rate |||____ S speed/performance ||_____ O updated online |______ P prefailure warning General Purpose Log Directory Version 1 SMART Log Directory Version 1 [multi-sector log support] Address Access R/W Size Description 0x00 GPL,SL R/O 1 Log Directory 0x01 SL R/O 1 Summary SMART error log 0x02 SL R/O 5 Comprehensive SMART error log 0x03 GPL R/O 6 Ext. Comprehensive SMART error log 0x04 GPL,SL R/O 8 Device Statistics log 0x06 SL R/O 1 SMART self-test log 0x07 GPL R/O 1 Extended self-test log 0x09 SL R/W 1 Selective self-test log 0x0c GPL R/O 2048 Pending Defects log 0x10 GPL R/O 1 NCQ Command Error log 0x11 GPL R/O 1 SATA Phy Event Counters log 0x21 GPL R/O 1 Write stream error log 0x22 GPL R/O 1 Read stream error log 0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log 0x80-0x9f GPL,SL R/W 16 Host vendor specific log 0xa0-0xa7 GPL,SL VS 16 Device vendor specific log 0xa8-0xb6 GPL,SL VS 1 Device vendor specific log 0xb7 GPL,SL VS 54 Device vendor specific log 0xbd GPL,SL VS 1 Device vendor specific log 0xc0 GPL,SL VS 1 Device vendor specific log 0xc1 GPL VS 93 Device vendor specific log 0xe0 GPL,SL R/W 1 SCT Command/Status 0xe1 GPL,SL R/W 1 SCT Data Transfer SMART Extended Comprehensive Error Log Version: 1 (6 sectors) Device Error Count: 9 CR = Command Register FEATR = Features Register COUNT = Count (was: Sector Count) Register LBA_48 = Upper bytes of LBA High/Mid/Low Registers ] ATA-8 LH = LBA High (was: Cylinder High) Register ] LBA LM = LBA Mid (was: Cylinder Low) Register ] Register LL = LBA Low (was: Sector Number) Register ] DV = Device (was: Device/Head) Register DC = Device Control Register ER = Error register ST = Status register Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 9 [8] occurred at disk power-on lifetime: 551 hours (22 days + 23 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 40 -- 51 03 f0 00 00 00 00 77 b8 e0 00 Error: UNC 1008 sectors at LBA = 0x000077b8 = 30648 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- 25 00 00 03 f0 00 00 00 00 77 b8 e0 08 00:03:15.436 READ DMA EXT 25 00 00 03 f8 00 00 00 00 73 c0 e0 08 00:03:15.424 READ DMA EXT 25 00 00 01 68 00 00 00 00 72 58 e0 08 00:03:14.011 READ DMA EXT 25 00 00 03 f8 00 00 00 00 6e 60 e0 08 00:03:14.002 READ DMA EXT 25 00 00 03 f8 00 00 00 00 6a 68 e0 08 00:03:13.990 READ DMA EXT Error 8 [7] occurred at disk power-on lifetime: 551 hours (22 days + 23 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 40 -- 51 03 f8 00 00 00 00 c6 80 e0 00 Error: UNC 1016 sectors at LBA = 0x0000c680 = 50816 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- 25 00 00 03 f8 00 00 00 00 c6 80 e0 08 00:07:34.759 READ DMA EXT 27 00 00 00 00 00 00 00 00 00 00 e0 08 00:07:34.759 READ NATIVE MAX ADDRESS EXT [OBS-ACS-3] ec 00 00 00 00 00 00 00 00 00 00 a0 0a 00:07:34.756 IDENTIFY DEVICE ef 00 03 00 46 00 00 00 00 00 00 a0 0a 00:07:34.756 SET FEATURES [Set transfer mode] 27 00 00 00 00 00 00 00 00 00 00 e0 08 00:07:34.756 READ NATIVE MAX ADDRESS EXT [OBS-ACS-3] Error 7 [6] occurred at disk power-on lifetime: 551 hours (22 days + 23 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 40 -- 51 00 08 00 00 00 00 9a 78 e0 00 Error: UNC 8 sectors at LBA = 0x00009a78 = 39544 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- c8 00 00 00 08 00 00 00 00 9a 78 e0 08 00:07:27.759 READ DMA 35 00 00 03 60 00 00 00 00 c3 20 e0 08 00:07:25.929 WRITE DMA EXT 27 00 00 00 00 00 00 00 00 00 00 e0 08 00:07:25.929 READ NATIVE MAX ADDRESS EXT [OBS-ACS-3] ec 00 00 00 00 00 00 00 00 00 00 a0 0a 00:07:25.927 IDENTIFY DEVICE ef 00 03 00 46 00 00 00 00 00 00 a0 0a 00:07:25.927 SET FEATURES [Set transfer mode] Error 6 [5] occurred at disk power-on lifetime: 551 hours (22 days + 23 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 10 -- 51 03 60 00 00 00 00 c3 20 e0 00 Error: IDNF 864 sectors at LBA = 0x0000c320 = 49952 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- 35 00 00 03 60 00 00 00 00 c3 20 e0 08 00:07:18.929 WRITE DMA EXT 35 00 00 03 f8 00 00 00 00 bf 28 e0 08 00:07:18.924 WRITE DMA EXT 35 00 00 03 f8 00 00 00 00 bb 30 e0 08 00:07:18.919 WRITE DMA EXT 35 00 00 03 f8 00 00 00 00 b7 38 e0 08 00:07:18.914 WRITE DMA EXT 35 00 00 03 f8 00 00 00 00 b3 40 e0 08 00:07:18.909 WRITE DMA EXT Error 5 [4] occurred at disk power-on lifetime: 551 hours (22 days + 23 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 40 -- 51 03 f8 00 00 00 00 9a 80 e0 00 Error: UNC 1016 sectors at LBA = 0x00009a80 = 39552 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- 25 00 00 03 f8 00 00 00 00 9a 80 e0 08 00:07:03.448 READ DMA EXT ca 00 00 00 e8 00 00 00 00 99 90 e0 08 00:07:02.646 WRITE DMA 35 00 00 03 f8 00 00 00 00 95 98 e0 08 00:06:59.437 WRITE DMA EXT 35 00 00 03 f8 00 00 00 00 91 a0 e0 08 00:06:56.457 WRITE DMA EXT 35 00 00 03 f8 00 00 00 00 8d a8 e0 08 00:06:56.452 WRITE DMA EXT Error 4 [3] occurred at disk power-on lifetime: 550 hours (22 days + 22 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 40 -- 51 00 08 00 00 00 08 00 40 e0 00 Error: UNC 8 sectors at LBA = 0x00080040 = 524352 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- c8 00 00 00 08 00 00 00 08 00 40 e0 08 00:01:16.739 READ DMA c8 00 00 00 08 00 00 00 04 00 40 e0 08 00:01:16.679 READ DMA 27 00 00 00 00 00 00 00 00 00 00 40 08 00:01:14.328 READ NATIVE MAX ADDRESS EXT [OBS-ACS-3] ec 00 00 00 01 00 00 00 00 00 00 40 0a 00:01:13.949 IDENTIFY DEVICE ca 00 00 00 08 00 00 00 00 00 c0 e0 08 00:01:12.471 WRITE DMA Error 3 [2] occurred at disk power-on lifetime: 519 hours (21 days + 15 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 40 -- 51 00 08 00 00 5f a0 00 48 e0 00 Error: UNC 8 sectors at LBA = 0x5fa00048 = 1604321352 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- 25 00 00 00 08 00 00 5f a0 00 48 e0 08 3d+01:29:48.532 READ DMA EXT c8 00 00 00 08 00 00 02 52 c4 28 e2 08 3d+01:29:44.884 READ DMA 25 00 00 00 08 00 00 5f c8 2e b0 e0 08 3d+01:29:27.990 READ DMA EXT e5 00 00 00 00 00 00 00 00 00 00 00 08 3d+01:03:53.581 CHECK POWER MODE ec 00 00 00 01 00 00 00 00 00 00 00 0a 3d+01:03:53.579 IDENTIFY DEVICE Error 2 [1] occurred at disk power-on lifetime: 343 hours (14 days + 7 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 40 -- 51 04 00 00 00 54 a2 99 70 e0 00 Error: UNC 1024 sectors at LBA = 0x54a29970 = 1419942256 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- 25 00 00 04 00 00 00 54 a2 99 70 e0 08 08:00:00.831 READ DMA EXT 25 00 00 02 00 00 00 54 a2 97 70 e0 08 08:00:00.804 READ DMA EXT 25 00 00 04 00 00 00 54 a2 93 70 e0 08 08:00:00.800 READ DMA EXT 25 00 00 02 00 00 00 54 a2 91 70 e0 08 08:00:00.788 READ DMA EXT 25 00 00 04 00 00 00 54 a2 8d 70 e0 08 08:00:00.785 READ DMA EXT SMART Extended Self-test Log Version: 1 (1 sectors) Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 550 - # 2 Short offline Completed without error 00% 528 - # 3 Extended offline Completed without error 00% 326 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay. SCT Status Version: 3 SCT Version (vendor specific): 258 (0x0102) Device State: Active (0) Current Temperature: 19 Celsius Power Cycle Min/Max Temperature: 18/30 Celsius Lifetime Min/Max Temperature: 8/35 Celsius Under/Over Temperature Limit Count: 0/0 Vendor specific: 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 SCT Temperature History Version: 2 Temperature Sampling Period: 1 minute Temperature Logging Interval: 1 minute Min/Max recommended Temperature: 0/60 Celsius Min/Max Temperature Limit: -41/85 Celsius Temperature History Size (Index): 478 (184) Index Estimated Time Temperature Celsius 185 2025-01-31 15:23 24 ***** 186 2025-01-31 15:24 23 **** ... ..( 3 skipped). .. **** 190 2025-01-31 15:28 23 **** 191 2025-01-31 15:29 22 *** ... ..( 4 skipped). .. *** 196 2025-01-31 15:34 22 *** 197 2025-01-31 15:35 21 ** ... ..( 8 skipped). .. ** 206 2025-01-31 15:44 21 ** 207 2025-01-31 15:45 20 * ... ..( 19 skipped). .. * 227 2025-01-31 16:05 20 * 228 2025-01-31 16:06 19 - ... ..(146 skipped). .. - 375 2025-01-31 18:33 19 - 376 2025-01-31 18:34 ? - 377 2025-01-31 18:35 19 - 378 2025-01-31 18:36 19 - 379 2025-01-31 18:37 28 ********* ... ..( 47 skipped). .. ********* 427 2025-01-31 19:25 28 ********* 428 2025-01-31 19:26 27 ******** ... ..( 6 skipped). .. ******** 435 2025-01-31 19:33 27 ******** 436 2025-01-31 19:34 26 ******* ... ..( 15 skipped). .. ******* 452 2025-01-31 19:50 26 ******* 453 2025-01-31 19:51 25 ****** ... ..(206 skipped). .. ****** 182 2025-01-31 23:18 25 ****** 183 2025-01-31 23:19 24 ***** 184 2025-01-31 23:20 24 ***** SCT Error Recovery Control: Read: 70 (7.0 seconds) Write: 70 (7.0 seconds) Device Statistics (GP Log 0x04) Page Offset Size Value Flags Description 0x01 ===== = = === == General Statistics (rev 2) == 0x01 0x008 4 232 --- Lifetime Power-On Resets 0x01 0x010 4 20991 --- Power-on Hours 0x01 0x018 6 31799591168 --- Logical Sectors Written 0x01 0x020 6 37157572 --- Number of Write Commands 0x01 0x028 6 468092086042 --- Logical Sectors Read 0x01 0x030 6 607668422 --- Number of Read Commands 0x03 ===== = = === == Rotating Media Statistics (rev 1) == 0x03 0x008 4 3047 --- Spindle Motor Power-on Hours 0x03 0x010 4 1107 --- Head Flying Hours 0x03 0x018 4 1644 --- Head Load Events 0x03 0x020 4 0 --- Number of Reallocated Logical Sectors 0x03 0x028 4 0 --- Read Recovery Attempts 0x03 0x030 4 0 --- Number of Mechanical Start Failures 0x04 ===== = = === == General Errors Statistics (rev 1) == 0x04 0x008 4 9 --- Number of Reported Uncorrectable Errors 0x04 0x010 4 589839 --- Resets Between Cmd Acceptance and Completion 0x05 ===== = = === == Temperature Statistics (rev 1) == 0x05 0x008 1 19 --- Current Temperature 0x05 0x010 1 27 --- Average Short Term Temperature 0x05 0x018 1 19 --- Average Long Term Temperature 0x05 0x020 1 35 --- Highest Temperature 0x05 0x028 1 10 --- Lowest Temperature 0x05 0x030 1 33 --- Highest Average Short Term Temperature 0x05 0x038 1 10 --- Lowest Average Short Term Temperature 0x05 0x040 1 26 --- Highest Average Long Term Temperature 0x05 0x048 1 12 --- Lowest Average Long Term Temperature 0x05 0x050 4 0 --- Time in Over-Temperature 0x05 0x058 1 60 --- Specified Maximum Operating Temperature 0x05 0x060 4 0 --- Time in Under-Temperature 0x05 0x068 1 0 --- Specified Minimum Operating Temperature 0x06 ===== = = === == Transport Statistics (rev 1) == 0x06 0x008 4 261131 --- Number of Hardware Resets 0x06 0x010 4 48 --- Number of ASR Events 0x06 0x018 4 0 --- Number of Interface CRC Errors |||_ C monitored condition met ||__ D supports DSN |___ N normalized value Pending Defects log (GP Log 0x0c) No Defects Logged SATA Phy Event Counters (GP Log 0x11) ID Size Value Description 0x0001 2 673 Command failed due to ICRC error 0x0002 2 678 R_ERR response for data FIS 0x0003 2 678 R_ERR response for device-to-host data FIS 0x0004 2 0 R_ERR response for host-to-device data FIS 0x0005 2 0 R_ERR response for non-data FIS 0x0006 2 0 R_ERR response for device-to-host non-data FIS 0x0007 2 0 R_ERR response for host-to-device non-data FIS 0x0008 2 0 Device-to-host non-data FIS retries 0x0009 2 6 Transition from drive PhyRdy to drive PhyNRdy 0x000a 2 24 Device-to-host register FISes sent due to a COMRESET 0x000b 2 0 CRC errors within host-to-device FIS 0x000d 2 0 Non-CRC errors within host-to-device FIS 0x000f 2 0 R_ERR response for host-to-device data FIS, CRC 0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC 0x8000 4 88196 Vendor specific