

-
Posts
38 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bamy
-
-
Is it possible to assign a hostname to this Docker container via Unraid? Saw this question asked on the Github but solution was to set it via the Compose file. https://github.com/linuxserver/docker-smokeping/issues/96
EDIT: Solved - had to enable 'Advanced View', then add the following in Extra Parameters:
--hostname="DESIRED_HOSTNAME"
-
10 hours ago, ich777 said:
What OS are you running on that Server? Keep in mind that you need to run something recent like Debian 11 or on of the newer Ubuntu releases.
1 Core and 2GB of memory are way too less resources for Valheim and I think that it crashes because of too less RAM.
Thanks for the info. I am on Debian 10 and it also makes sense re: lack of resources... Will try and find another VPS to use...
Edit: migrated over the binarylane VPS [AU], debian 11 2core 4gb memory and all working 😃 Thank you
-
 1
1
-
-
I'm getting the following error when running the Valheim SteamCMD server:
/opt/scripts/start-server.sh: line 255: 65 Trace/breakpoint trap (core dumped) ${SERVER_DIR}/valheim_server.x86_64 -name "${SRV_NAME}" -port ${GAME_PORT} -world "${WORLD_NAME}" -password "${SRV_PWD}" -public ${PUBLIC} ${GAME_PARAMS} > /dev/null
Trying to run it on an OVH VPS (1 core 2GB memory). Is there somewhere I can trace the log and see what is causing this issue?
-
I can't seem to get this working with my TorGuard generated OVPN file. It seems to run fine up until the connection point with OpenVPN. It loops with the following:
2021-04-29 19:21:23,743 DEBG 'start-script' stdout output: 2021-04-29 19:21:23 OpenVPN 2.5.1 [git:makepkg/f186691b32e68362+] x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Feb 24 2021 2021-04-29 19:21:23 library versions: OpenSSL 1.1.1j 16 Feb 2021, LZO 2.10 2021-04-29 19:21:28,743 DEBG 'start-script' stdout output: 2021-04-29 19:21:28 NOTE: the current --script-security setting may allow this configuration to call user-defined scripts 2021-04-29 19:21:28,743 DEBG 'start-script' stdout output: 2021-04-29 19:21:28 TCP/UDP: Preserving recently used remote address: [AF_INET]193.XXX.XXX.XXX:1912 2021-04-29 19:21:28,744 DEBG 'start-script' stdout output: 2021-04-29 19:21:28 UDP link local: (not bound) 2021-04-29 19:21:28 UDP link remote: [AF_INET]193.XXX.XXX.XXX:1912 2021-04-29 19:22:28,441 DEBG 'start-script' stdout output: 2021-04-29 19:22:28 [UNDEF] Inactivity timeout (--ping-restart), restarting 2021-04-29 19:22:28,442 DEBG 'start-script' stdout output: 2021-04-29 19:22:28 SIGHUP[soft,ping-restart] received, process restarting 2021-04-29 19:22:28,442 DEBG 'start-script' stdout output: 2021-04-29 19:22:28 DEPRECATED OPTION: ncp-disable. Disabling cipher negotiation is a deprecated debug feature that will be removed in OpenVPN 2.6 2021-04-29 19:22:28 WARNING: file 'credentials.conf' is group or others accessible
Any ideas? I've tested the same config using OpenVPN GUI on my PC and it connects fine.
EDIT; It ended up connecting after sometime. I'll continue to monitor the connection.
-
Is anyone able to get Grafana's Image Renderer plugin working with this Docker? After installing it through the console & restarting, it doesn't work :[
Grafana v7.0.5 (efbcbb838b)
https://grafana.com/grafana/plugins/grafana-image-renderer/installation
t=2020-07-08T11:22:52+0800 lvl=eror msg="Stopped RenderingService" logger=server reason="Failed to start renderer plugin: Unrecognized remote plugin message: \n\nThis usually means that the plugin is either invalid or simply\nneeds to be recompiled to support the latest protocol." t=2020-07-08T11:22:52+0800 lvl=warn msg="plugin failed to exit gracefully" logger=plugins.backend pluginId=grafana-image-renderer t=2020-07-08T11:22:52+0800 lvl=info msg="Stopped Stream Manager" t=2020-07-08T11:22:52+0800 lvl=info msg="HTTP Server Listen" logger=http.server address=[::]:3000 protocol=http subUrl= socket= t=2020-07-08T11:22:52+0800 lvl=eror msg="A service failed" logger=server err="Failed to start renderer plugin: Unrecognized remote plugin message: \n\nThis usually means that the plugin is either invalid or simply\nneeds to be recompiled to support the latest protocol." t=2020-07-08T11:22:52+0800 lvl=eror msg="Server shutdown" logger=server reason="Failed to start renderer plugin: Unrecognized remote plugin message: \n\nTh
EDIT: I got it working. Had to create a new Docker container following advice from https://grafana.com/docs/grafana/latest/administration/image_rendering/#remote-rendering-service, then adding extra enviroment variables (GF_RENDERING_SERVER_URL: http://UNRAID_IP:8081/render,GF_RENDERING_CALLBACK_URL: http://UNRAID_IP:3000/,GF_LOG_FILTERS: rendering:debug) to the Grafana Docker.
-
 1
1
-
-
the community.
snapshots would be cool
-
7 minutes ago, CHBMB said:
Why don't you submit it as a PR here.
Thanks, I'll do that.
8 hours ago, Tucubanito07 said:if you get Nextcloud working within your Lan can you let us know please. I am able to connect to Nextcloud through Wan but inside the network i can.
I'm not configuring Nextcloud so the setup is probably different. Have you had a look at Spaceinvader One's tutorial on YouTube? https://www.youtube.com/watch?v=I0lhZc25Sro
5 minutes ago, Tucubanito07 said:In what file is did you change this?
It's covered in the YouTube tutorial. Inside the AppData folder of the letsencrypt docker (/appdata/letsencrypt/nginx/proxy-confs)
-
I managed to get it working. I had to remove the trailing '/' from
proxy_pass https://$upstream_znc:6501/;
Thanks for the help!!
-
3 hours ago, CHBMB said:
Also is ZNC over https or http?
Over https
I changed
proxy_pass http://$upstream_znc:6501/;
to
proxy_pass https://$upstream_znc:6501/;
and now i'm able to see the ZNC login (without css, though).
Once I log in, I get "403 Access denied
POST requests need to send a secret token to prevent cross-site request forgery attacks."
34 minutes ago, aptalca said:Is znc on the same user defined bridge network as letsencrypt? Is the container named "znc"? Is it running? Can you reach it via http://unraidip:6501 ?
Yeah that's all good from me.
-
1 hour ago, CHBMB said:
Then it's working?
No unfortunately it's not working still, even with that extra parameter described in the znc wiki. I still get 502 bad gateway

-
Could somebody create a NGINX template for Linuxserver.io - ZNC? I've tried but ended up with 502 Bad Gateway
server { listen 443 ssl; listen [::]:443 ssl; server_name znc.*; include /config/nginx/ssl.conf; client_max_body_size 0; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /login; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_znc znc; proxy_pass http://$upstream_znc:6501/; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } }I added
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;per https://wiki.znc.in/Reverse_Proxy , without it I still get 502.
Thanks!
-
15 minutes ago, bastl said:
Did you tried to change the disk type to sata? I had some issues with some debian based distros using virtio or scsi as bus type.
That did the trick, thanks so much!
I also had to change the network model type to e1000-82545em to get the network working
Hopefully this helps someone out in the future 🙂
-
Hi, I'm trying to get Debian 7 to work on Unraid. Currently I am stuck on trying to detect a disk.
Here is the XML
<emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/domains/name/vdisk1.img'/> <backingStore/> <target dev='hdc' bus='virtio'/> <boot order='1'/> <alias name='virtio-disk2'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </disk> <disk type='file' device='cdrom'> <driver name='qemu' type='raw'/> <source file='/mnt/user/isos/debian-7.11.0-amd64-netinst.iso'/> <backingStore/> <target dev='hda' bus='sata'/> <readonly/> <boot order='2'/> <alias name='sata0-0-0'/> <address type='drive' controller='0' bus='0' target='0' unit='0'/> </disk>
In the VM (I've tried virtio_blk, virtio_scsci options that are available)
lspci in VM:
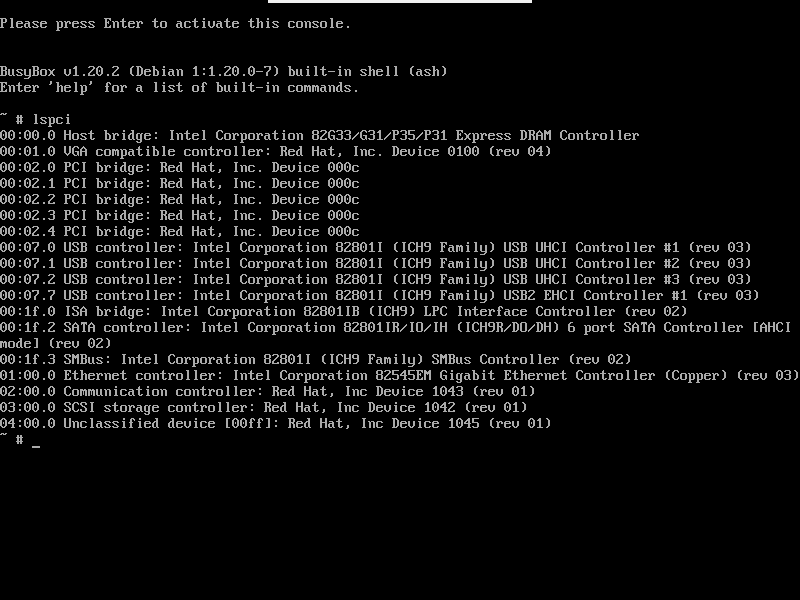
Any help would be appreciated, thanks !
-
13 hours ago, lickmygiggle said:
Try rebooting the server and doing a memtest.
Thanks for letting me know! If the issue arises again I will make sure to do this. Glad you found your problem!
-
7 hours ago, johnnie.black said:
That's because it dropped offline, looks like a cable problem, if you already replaced cables swap the cables/backplane drive with another disk and see if the problems follows the disk.
I've swapped cables around with drives that have no issues, and the problems remained on the same drive. I've just finished a parity sync with 0 errors, and the array status of Faulty is gone. I'll probably go and buy a new hard drive today, though.
-
Hello, I have been facing issues with a single harddrive of mine lately, where the UDMA CRC count keeps rising, it is currently up to 4225. I have looked up other users threads regarding the issue, and it all seems to be a physical problem with the data transfer via the cables. I have done what others have said (replace SATA, SATA power cables), though the issue is still happening.
Now, Unraid has put the harddrive in error state. Is this a problem with the harddrive itself? No other harddrives have the error, so I don't believe its the SAS controller.
I've run diagnostics post-error state, and post-reboot (after adjusting cables again). Unfortunately there are no SMART results for the faulty disk after getting placed in error state.
I would appreciate any assistance on this, thank you so much.
Faulty drive in question: ST4000VN008-2DR166_WDH31FXE
SAS: Fujitsu 9211-8i D2607
-
How do I edit the .ini file?
-
It's working for me on the newest update (tag: 156).
-
I tested with Linuxserver.io's resilio-sync and the timezone is set correctly..
Sorry for that mix up

-
-
I've set my date and time under Unraid's settings, yet Docker containers do not change.
Example, with Linuxserver.io's Resilio Sync:

Docker run command:
docker run -d --name='Sync' --net='bridge' -e TZ="Australia/Melbourne" -e HOST_OS="unRAID" -p '8888:8888/tcp' -p '5555:5555/tcp' -p '3838:3838/udp' -v '/path/to/volume/':'/path':'rw' -v '/mnt/user/appdata/Sync':'/config':'rw' 'limetech/sync' The command finished successfully!
-
On 12/11/2017 at 3:29 AM, nuhll said:
Are there any news to get this working on unraid?
It works for me using Community Applications plugin, and port forwarding on my router.
-
20 minutes ago, bonienl said:
Routers don't decide on their own to make changes like this, something was changed in your environment.
")
To reach your unRAID server you can change the network settings of your PC and give it a static IP address in the same range as the server. Once all is settled change it back to dynamic.
Thanks, I've managed to change my LAN back to the 192.168.0.X address space. Hopefully no more issues show up.
-
As the title suggests, I've had a 192.168.0.X address space for as long as I can remember. And now, suddenly, my router (Netgear D7000) has decided to all of a sudden switch to a 10.0.0.X address space.
The problem with that is, I've statically configured my Unraid server on a 192.168.0.X address space, and I can not access it anymore.
What can I do?




[Support] Linuxserver.io - SmokePing
in Docker Containers
Posted
The graphs use the hostname in the title. For example "Last 3 hours from HOSTNAME to Domain". Looks better to have a named hostname than Docker's random one.