




elecgnosis
Members
-
Joined
-
Last visited
Everything posted by elecgnosis
-
Thanks again, and I just might. Should I run the correcting parity check in maintenance mode? Does it matter at this point?
-
Okay, done omni-diagnostics-20250528-1024.zip
-
I started in maintenance mode, do you mean for me to start the array normally?
-
Okay, thanks for your help. omni-diagnostics-20250528-0731.zip
-
omni-diagnostics-20250527-1643.zip
-
Tried to replace 12TB drive 15 with precleared 20TB drive. Data-rebuild began okay. Hours later, drive 11 starts throwing read errors and eventually gets auto-removed from the array, contents emulated. I paused the data-rebuild. I went to the now-unassigned drive 11 (disk sdaa under unassigned devices) and ran its extended Smart report. Took over a day, but cleared with no error. I pulled diagnostics at this time. (attached omni-diagnostics-20250526-1437) I read that in cases like this, it (might) be power and connectors. I stopped the array. I opened the case and checked drive SAS and power connectors. I hot-swapped an unassigned hot spare with the original 12TB drive that was going to be replaced. In the array config in Main, I replaced the precleared 20TB drive with the original 12TB in slot 15. I took a screenshot to confirm drive assignments. In Tools, I set a new config, preserving all assignments. I confirmed drive positions with the screenshot. I marked parity as valid. I started the array in maintenance mode. I pulled another set of diagnostics. (attached omni-diagnostics-20250526-1521) What should I do next to make sure that drive 11 is good? Should I run a parity-sync without writing corrections? omni-diagnostics-20250526-1437.zip omni-diagnostics-20250526-1521.zip
-
I started the array with a new config and almost immediately got errors on a different drive than I was having trouble with before. I'm going to go through the same Smart/Scrub checks, but I'm not expecting any surprises. Previously, I was running off of a voltage-regulating UPS. I didn't keep it during the move, so I wonder if that's the secret sauce here. I'm using an 850W power supply that has been rock-solid otherwise. I have a new UPS coming, but not for a couple weeks. If I still have trouble on the other side of that, I'll look into replacing the power supply. Marking this as solved for now.
-
Thanks. Do you have any guidance for the UI not responding? I can force a shutdown if I have to, I'm just trying to avoid it.
-
Forgot the files, here they are. omni-diagnostics-20231110-1910.zip
-
After moving recently, I started a new parity check to see whether my disks were still okay. Later, I checked in on it and it seemed to have ran for about six hours, then quit with read errors on disk 1 and connectivity problems with five other drives. There were also UDMA errors on a hot spare that didn't even have any data on it, besides a preclear record. I shut down the server without downloading diagnostics (sorry). I checked how secure data and power cables were, moved some drives around in the server's slots, then powered back on. Next I unassigned the drive with read errors and mounted it in unassigned devices. I ran a BTRFS scrub. It returned an exit code of 0, meaning no errors. Then I ran an extended SMART scan on it and all of the other drives that had connectivity problems. Hopefully those show up in the diagnostics I've included here. Today, I tried reassigning my hot spare to the array in the position that the read error disk had. I accepted that the replacement drive would be rebuilt over and started the array. The operation didn't run for very long before the replacement drive came up with read errors, putting it in an unmountable state. I tried to stop the array, but none of the server buttons in Main are responding. I tried stopping the read-check as well, but nothing is responding there. I can click around the interface to do other things, just not this. I was able to pull both diagnostics and the system log. I also noticed that the system log had an error for /var/log being 97% full. I don't know if that's why the UI is acting like it is. The last time I was dealing with something like this, I remember finding something on the forum saying that stopping loop2 could get it to work again, but I haven't tried that yet. The BTRFS scrub leads me to believe that the original drive with the read error is okay. Should I just do a new config? I'll take any other steps you folks think I should try, otherwise.
-
I ended up doing a new configuration, sacrificing parity. I then spent the last week doing BTRFS scrubs on all of the original array drives, even the first one that had reported errors. All finished without errors. I'm rebuilding parity now.
-
I found these steps to try, and after mounting the drive, it appears that the data is still there. However, there's 9TB of data to back up. I don't have 9TB of free space available on any individual drive in the array, though I guess I could still back it up if I distribute the directories across multiple drives. Or I could swap the drive and let parity rebuild the data for me. Unless any of you think there's another route to fixed here that doesn't involve waiting ten days to write 18TB of data, that's the option I'm going to go with. I will hold on to the troubled drive in case something happens during the parity rebuild.
-
I was away from home for a week and when I got back, I noticed I had an error in Unraid. Something was wrong with a two-year-old drive. I shut down the server, checked the cables, and also moved the drive to another slot. The next startup, it appeared that the drive that I swapped its slot with also had a problem, so I shut down again and shuffled more drives around. This last startup, the one that I posted diagnostics from, still showed the first problem drive as "Unmountable: Unsupported or no file system" but at least it was the only one that seemed to be bad. I'm not sure how to proceed. I could just replace it with a hot spare, but I've seen some posts here where people in similar situations were able to repair or restore the file system and even add the drive back to the array. Diagnostics posted, please advise. my-diagnostics-20230715-1652.zip
-
That got it. Cables secured, moved drive 11 to another physical position, started back up. Data-rebuild running now. Good enough to call it solved for now, thank you.
-
I've cancelled the data-rebuild in the UI, but it doesn't seem to do anything. Should I just use the shutdown button? Latest diagnostics attached. omni-diagnostics-20230511-1102.zip
-
Thank you, I'll get to it. If I don't run into any other trouble, I'll mark as [SOLVED].
-
Here it is: omni-diagnostics-20230511-0714.zip
-
I had an old, smaller drive I wanted to replace with a newer, larger drive. I precleared the new drive, shut down the entire server, removed the drive I wanted to replace, and set the new drive in its place. I also pulled one other drive out to check its serial number and re-seated it. Next I powered up the server, set the new drive to replace the old in the array, and started the rebuild. I checked the server this morning and it appears that another older drive (not the one I re-seated) has a rack of read errors. Checking some notes I had, it seems that mysterious read errors have hit this drive before, but amounted to nothing as re-seating it resolved those issues at that time. My problem now is, I want to re-seat or even re-position that drive in the server, but I don't know how to do that without ruining the data rebuild currently in process. Do I need to stop the rebuild, shut down the server, re-seat/reposition/check cables or do whatever physical maintenance this seems to call for, then resume the rebuild, presuming that the "problem" drive is just having physical issues?
-
It looks like the database is locked. The log shows that there's an update to be done, but liquibase can't get the changelog lock it needs to do the update. If there were a way to reach in and remove the lock for "c9f6f438f31c (172.17.0.4)" that might help, but I have no idea how to get at the database in use. 2019-03-05 20:17:09.522 WARN --- ationConfigEmbeddedWebApplicationContext : Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'playerSettingsController': Unsatisfied dependency expressed through field 'playerService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'liquibase' defined in class path resource [applicationContext-db.xml]: Invocation of init method failed; nested exception is liquibase.exception.LockException: Could not acquire change log lock. Currently locked by c9f6f438f31c (172.17.0.4) since 3/1/19 10:01 PM 2019-03-05 20:17:09.549 ERROR --- o.s.boot.SpringApplication : Application startup failed
-
I can't find that. I haven't upgraded to 6.6.7 yet, so maybe it's available in that version? Here's a screenshot of the Update Container page, if that will help:
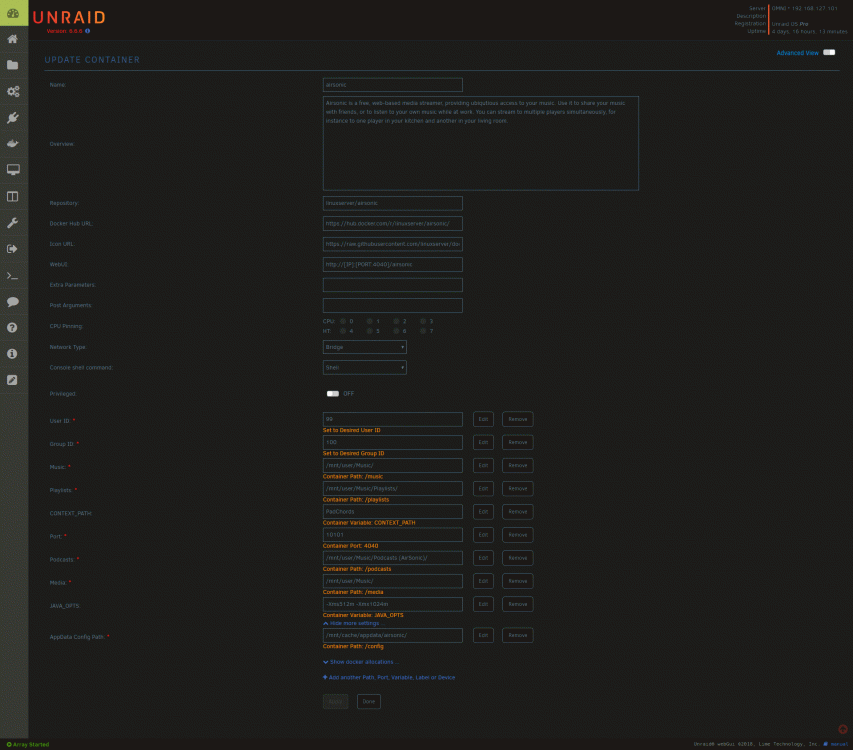
-
Here's my [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 10-adduser: executing... ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. _ _ /\ (_) (_) / \ _ _ __ ___ ___ _ __ _ ___ / /\ \ | | '__|/ __|/ _ \| '_ \| |/ __| / ____ \| | | \__ \ (_) | | | | | (__ /_/ \_\_|_| |___/\___/|_| |_|_|\___| 10.2.1-RELEASE 2019-03-05 20:11:39.627 INFO --- org.airsonic.player.Application : Starting Application v10.2.1-RELEASE on 25cc7c68fca1 with PID 210 (/app/airsonic/airsonic.war started by abc in /app/airsonic) 2019-03-05 20:11:39.634 INFO --- org.airsonic.player.Application : The following profiles are active: legacy 2019-03-05 20:11:41.942 INFO --- o.a.p.service.SettingsService : Java: 1.8.0_191, OS: Linux 2019-03-05 20:11:42.327 INFO --- org.airsonic.player.Application : Detected Tomcat web server 2019-03-05 20:12:07.425 INFO --- liquibase : Successfully acquired change log lock 2019-03-05 20:12:07.425 INFO --- liquibase : Successfully acquired change log lock 2019-03-05 20:12:09.359 INFO --- liquibase : Reading from DATABASECHANGELOG 2019-03-05 20:12:09.479 INFO --- liquibase : classpath:liquibase/db-changelog.xml: classpath:liquibase/10.2/setup-hsqldb-checkpoint-defrag.xml::setup-hsqldb-checkpoint-defrag::fxthomas: Rolling Back Changeset:classpath:liquibase/10.2/setup-hsqldb-checkpoint-defrag.xml::setup-hsqldb-checkpoint-defrag::fxthomas 2019-03-05 20:12:09.481 INFO --- liquibase : classpath:liquibase/db-changelog.xml: classpath:liquibase/6.4/add-album-mb-release-id.xml::add-album-mb-release-id::fxthomas: Rolling Back Changeset:classpath:liquibase/6.4/add-album-mb-release-id.xml::add-album-mb-release-id::fxthomas 2019-03-05 20:12:09.483 INFO --- liquibase : classpath:liquibase/db-changelog.xml: classpath:liquibase/6.4/add-media-file-mb-release-id.xml::add-media-file-mb-release-id::fxthomas: Rolling Back Changeset:classpath:liquibase/6.4/add-media-file-mb-release-id.xml::add-media-file-mb-release-id::fxthomas 2019-03-05 20:12:09.489 INFO --- liquibase : Successfully released change log lock 2019-03-05 20:12:09.491 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:12:09.359 INFO --- liquibase : Reading from DATABASECHANGELOG 2019-03-05 20:12:09.479 INFO --- liquibase : classpath:liquibase/db-changelog.xml: classpath:liquibase/10.2/setup-hsqldb-checkpoint-defrag.xml::setup-hsqldb-checkpoint-defrag::fxthomas: Rolling Back Changeset:classpath:liquibase/10.2/setup-hsqldb-checkpoint-defrag.xml::setup-hsqldb-checkpoint-defrag::fxthomas 2019-03-05 20:12:09.481 INFO --- liquibase : classpath:liquibase/db-changelog.xml: classpath:liquibase/6.4/add-album-mb-release-id.xml::add-album-mb-release-id::fxthomas: Rolling Back Changeset:classpath:liquibase/6.4/add-album-mb-release-id.xml::add-album-mb-release-id::fxthomas 2019-03-05 20:12:09.483 INFO --- liquibase : classpath:liquibase/db-changelog.xml: classpath:liquibase/6.4/add-media-file-mb-release-id.xml::add-media-file-mb-release-id::fxthomas: Rolling Back Changeset:classpath:liquibase/6.4/add-media-file-mb-release-id.xml::add-media-file-mb-release-id::fxthomas 2019-03-05 20:12:09.489 INFO --- liquibase : Successfully released change log lock 2019-03-05 20:12:09.491 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:12:19.492 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:12:29.493 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:12:39.494 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:12:49.495 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:12:59.496 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:09.497 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:09.497 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:19.497 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:29.498 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:39.499 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:49.500 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:59.501 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:13:59.501 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:14:09.502 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:14:19.503 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:14:29.503 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:14:39.504 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:14:49.505 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:14:59.506 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:14:59.506 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:15:09.507 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:15:19.507 INFO --- liquibase : Waiting for changelog lock.... 2019-03-05 20:17:09.517 ERROR --- o.a.p.spring.SpringLiquibase : =============================================== 2019-03-05 20:17:09.517 ERROR --- o.a.p.spring.SpringLiquibase : An exception occurred during database migration 2019-03-05 20:17:09.517 ERROR --- o.a.p.spring.SpringLiquibase : A rollback file has been generated at /config/rollback.sql 2019-03-05 20:17:09.517 ERROR --- o.a.p.spring.SpringLiquibase : Execute it within your database to rollback any changes 2019-03-05 20:17:09.521 ERROR --- o.a.p.spring.SpringLiquibase : The exception is as follows liquibase.exception.LockException: Could not acquire change log lock. Currently locked by c9f6f438f31c (172.17.0.4) since 3/1/19 10:01 PM at liquibase.lockservice.StandardLockService.waitForLock(StandardLockService.java:190) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.Liquibase.update(Liquibase.java:196) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.Liquibase.update(Liquibase.java:192) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.integration.spring.SpringLiquibase.performUpdate(SpringLiquibase.java:434) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.integration.spring.SpringLiquibase.afterPropertiesSet(SpringLiquibase.java:391) ~[liquibase-core-3.5.1.jar!/:na] at org.airsonic.player.spring.SpringLiquibase.afterPropertiesSet(SpringLiquibase.java:26) ~[classes!/:10.2.1-RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeInitMethods(AbstractAutowireCapableBeanFactory.java:1689) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1627) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:553) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:481) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:312) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:308) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:297) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:202) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:208) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1136) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1064) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:583) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:87) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues(AutowiredAnnotationBeanPostProcessor.java:364) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1269) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:551) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:481) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:312) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:308) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:761) [spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:867) [spring-context-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:543) [spring-context-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.boot.context.embedded.EmbeddedWebApplicationContext.refresh(EmbeddedWebApplicationContext.java:124) [spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:693) [spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:360) [spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.SpringApplication.run(SpringApplication.java:303) [spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.builder.SpringApplicationBuilder.run(SpringApplicationBuilder.java:134) [spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.airsonic.player.Application.main(Application.java:229) [classes!/:10.2.1-RELEASE] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_191] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_191] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_191] at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_191] at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:48) [airsonic.war:10.2.1-RELEASE] at org.springframework.boot.loader.Launcher.launch(Launcher.java:87) [airsonic.war:10.2.1-RELEASE] at org.springframework.boot.loader.Launcher.launch(Launcher.java:50) [airsonic.war:10.2.1-RELEASE] at org.springframework.boot.loader.WarLauncher.main(WarLauncher.java:59) [airsonic.war:10.2.1-RELEASE] 2019-03-05 20:17:09.522 ERROR --- o.a.p.spring.SpringLiquibase : =============================================== 2019-03-05 20:17:09.522 WARN --- ationConfigEmbeddedWebApplicationContext : Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'playerSettingsController': Unsatisfied dependency expressed through field 'playerService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'liquibase' defined in class path resource [applicationContext-db.xml]: Invocation of init method failed; nested exception is liquibase.exception.LockException: Could not acquire change log lock. Currently locked by c9f6f438f31c (172.17.0.4) since 3/1/19 10:01 PM 2019-03-05 20:17:09.549 ERROR --- o.s.boot.SpringApplication : Application startup failed org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'playerSettingsController': Unsatisfied dependency expressed through field 'playerService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'liquibase' defined in class path resource [applicationContext-db.xml]: Invocation of init method failed; nested exception is liquibase.exception.LockException: Could not acquire change log lock. Currently locked by c9f6f438f31c (172.17.0.4) since 3/1/19 10:01 PM at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:586) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:87) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues(AutowiredAnnotationBeanPostProcessor.java:364) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1269) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:551) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:481) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:312) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:308) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:761) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:867) ~[spring-context-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:543) ~[spring-context-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.boot.context.embedded.EmbeddedWebApplicationContext.refresh(EmbeddedWebApplicationContext.java:124) ~[spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:693) ~[spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:360) ~[spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.SpringApplication.run(SpringApplication.java:303) ~[spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.springframework.boot.builder.SpringApplicationBuilder.run(SpringApplicationBuilder.java:134) [spring-boot-1.5.18.RELEASE.jar!/:1.5.18.RELEASE] at org.airsonic.player.Application.main(Application.java:229) [classes!/:10.2.1-RELEASE] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_191] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_191] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_191] at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_191] at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:48) [airsonic.war:10.2.1-RELEASE] at org.springframework.boot.loader.Launcher.launch(Launcher.java:87) [airsonic.war:10.2.1-RELEASE] at org.springframework.boot.loader.Launcher.launch(Launcher.java:50) [airsonic.war:10.2.1-RELEASE] at org.springframework.boot.loader.WarLauncher.main(WarLauncher.java:59) [airsonic.war:10.2.1-RELEASE] Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'liquibase' defined in class path resource [applicationContext-db.xml]: Invocation of init method failed; nested exception is liquibase.exception.LockException: Could not acquire change log lock. Currently locked by c9f6f438f31c (172.17.0.4) since 3/1/19 10:01 PM at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1631) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:553) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:481) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:312) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:308) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:297) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:202) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:208) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1136) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1064) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:583) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] ... 26 common frames omitted Caused by: liquibase.exception.LockException: Could not acquire change log lock. Currently locked by c9f6f438f31c (172.17.0.4) since 3/1/19 10:01 PM at liquibase.lockservice.StandardLockService.waitForLock(StandardLockService.java:190) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.Liquibase.update(Liquibase.java:196) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.Liquibase.update(Liquibase.java:192) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.integration.spring.SpringLiquibase.performUpdate(SpringLiquibase.java:434) ~[liquibase-core-3.5.1.jar!/:na] at liquibase.integration.spring.SpringLiquibase.afterPropertiesSet(SpringLiquibase.java:391) ~[liquibase-core-3.5.1.jar!/:na] at org.airsonic.player.spring.SpringLiquibase.afterPropertiesSet(SpringLiquibase.java:26) ~[classes!/:10.2.1-RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeInitMethods(AbstractAutowireCapableBeanFactory.java:1689) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1627) ~[spring-beans-4.3.21.RELEASE.jar!/:4.3.21.RELEASE] ... 38 common frames omitted This continues for some time. It will ultimately throw an error, restart the server, and get stuck in the same loop. What can I do?
