

berizzle
-
Posts
32 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by berizzle
-
-
I am sorry I do not understand the question.
-
Precleared a brand new drive. Added lots of data to the machine and the disk is now disabled.
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 70% 211 20836536 # 2 Extended offline Completed: read failure 40% 207 20836536 # 3 Short offline Completed without error 00% 201 -
See SMART log
What do I do next?
-
Great thanks.
-
1 minute ago, johnnie.black said:
Reiserfs disks seem to be the #1 reason for this issue, convert one of your disks to XFS, limit all writes to that disk for a few days/weeks by changing your shares(s) included disks and see if crashing stops, if yes convert remaining disks.
PS: IMO you should convert even if this isn't the source of the problem, there have been multiple issues with reiser lately and they have terrible performance in certain situations.
I have 23 drives, 21 are Reiserfs 42TB and 2 XFS 6TB.
9TB free over all the drives.
Is there any process that makes sense to convert these disks?
-
On 3/22/2017 at 3:15 AM, johnnie.black said:
Any reiserfs disks?Yes of course. Been running this machines for years now. Maybe 5.
Just happened again and after a day of it not "coming back" I need to kill the machine.
-
Has anyone found a fix for machines in this state?
One of my unRAID machines is having the same issue
-
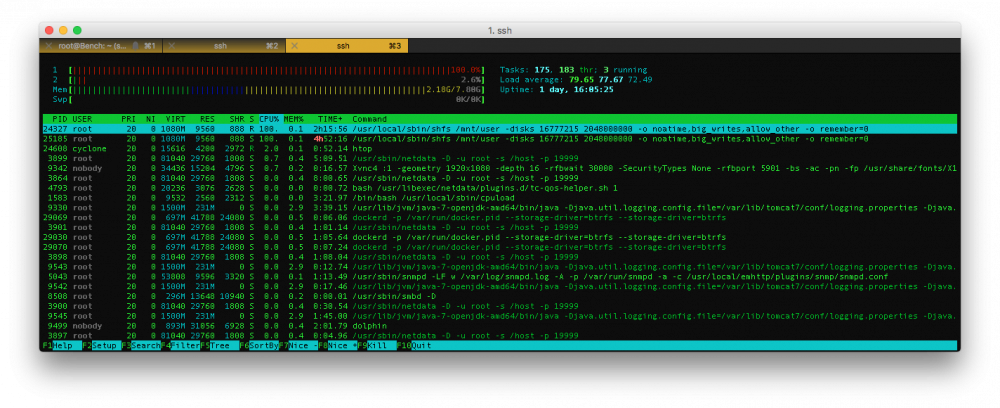
See image.
What are the two top processes and why are they running at 100%?
How can I get the machine back to normal running order safely?
Is it safe to kill those top two PIDs?
-
Just now, RobJ said:
This is Linux, those are completely allowable. It's only a problem when you interface to Windows stations, where it's not allowable.
You are right. I was just thinking for users that may have this same issue unRAID can warn you have the same things created but in different case.
53 minutes ago, Squid said:None of these problems however should cause the system to stop responding.... But it does confuse the hell out of SMB so who knows.
HTTP and AFP were non responsive. I think I saw out of memory messages in the video too.
Anyways i think this should solve the issues. Thanks all. Maybe this should be a plugin installed by default?
-
So it looks like these may be the problems. To bad the interface doesn't disallow or alert the user when trying to create a share with the same spelling but different case. I am not sure how some of those happened.
I'll work on these and see what happens.

-
If you want to move it sure go ahead.
This only started recently in the last couple of weeks. Before then I have not seen this. This machine as been running unRAID for 5+ years now.
It would be nice to know how to properly stop the array from local console as before I reboot it again.
-
Description: About 24 hours or so after this unRAID machine being turned on it is inaccessible via anything but SSH. To me it appears SMBD has gone haywire.
How to reproduce: Reboot the machine. After about 24 or so hours the machine will become inaccessible again except via SSH.
See video (recorded using iPhone Slo-mo mode 240 FPS)
https://storage.googleapis.com/shitfarm/Movie-2017-03-18-14-22.mp4
-
Understood but it was very odd that there is no warning that the cache drive will be formatted. The drive appeared to be RAW even though it wasn't.
What is the benefit of this BTRFS for unRAID?
-
A rebooted did not change the issue.
Selecting the cache drive and selecting none and reselecting the drive changed the cache FS to auto. Started the array and all is well.
Very odd behavior.
-
Updated from 6.0.0 to 6.0.1. I did not start the array after the reboot. Changed array slots from 24 to 22 and cache from 1 to 2. Doing this only to see options for additional cache slots. Now I see the cache drive FS is btrfs and not reiserfs. I start the array and you know the rest, I have an option to format the cache drive.

How do I undo what happened? Or at least mount the drive to recover the data?
I am surprised this happened.
-
Thank you for being so kind, htcnewbie.
Kaveh see http://lime-technology.com/forum/index.php?topic=33341.885
For every app that you have installed create the last 6 lines.
Add this to your go script.
What is the app name? See the url that you would normally go to.
Example: http://10.5.4.5:58000/Settings/flexget "flexget" is the "app name', then.
### Fix plugins cp -r /usr/local/emhttp/plugins/webGui/phaze.page /usr/local/emhttp/plugins/dynamix echo "" >> /usr/local/emhttp/plugins/plexmediaserver/plexmediaserver.page echo "---" >> /usr/local/emhttp/plugins/plexmediaserver/plexmediaserver.page echo "" >> /usr/local/emhttp/plugins/plexmediaserver/plexmediaserver.page cat /usr/local/emhttp/plugins/plexmediaserver/plexmediaserver.php >> /usr/local/emhttp/plugins/plexmediaserver/plexmediaserver.page rm -f /usr/local/emhttp/plugins/plexmediaserver/plexmediaserver.php sed -i 's!\r!!g' /usr/local/emhttp/plugins/plexmediaserver/plexmediaserver.page echo "" >> /usr/local/emhttp/plugins/couchpotato/couchpotato.page echo "---" >> /usr/local/emhttp/plugins/couchpotato/couchpotato.page echo "" >> /usr/local/emhttp/plugins/couchpotato/couchpotato.page cat /usr/local/emhttp/plugins/couchpotato/couchpotato.php >> /usr/local/emhttp/plugins/couchpotato/couchpotato.page rm -f /usr/local/emhttp/plugins/couchpotato/couchpotato.php sed -i 's!\r!!g' /usr/local/emhttp/plugins/couchpotato/couchpotato.page echo "" >> /usr/local/emhttp/plugins/transmission/transmission.page echo "---" >> /usr/local/emhttp/plugins/transmission/transmission.page echo "" >> /usr/local/emhttp/plugins/transmission/transmission.page cat /usr/local/emhttp/plugins/transmission/transmission.php >> /usr/local/emhttp/plugins/transmission/transmission.page rm -f /usr/local/emhttp/plugins/transmission/transmission.php sed -i 's!\r!!g' /usr/local/emhttp/plugins/transmission/transmission.page
So, after looking at the new unraid beta 12, it seems if I update my plugins, all users under beta 12 will get broken plugins. Also, since they are making changes on each beta release, it's getting hard to update them all constantly with the changes. I will likely wait for the first release candidate before updating all 17 plugins for full compatibility. In the mean time, you can do the following to get any plugin working on beta 12 for now, You can set this in your GO script to automate it, but you need to add this for each plugin of mine you have that doesn't work on beta 12: (replace APPNAME with the name of the app plugin in lowercase)cp -r /usr/local/emhttp/plugins/webGui/phaze.page /usr/local/emhttp/plugins/dynamixecho "" >> /usr/local/emhttp/plugins/(APPNAME)/(APPNAME).page echo "---" >> /usr/local/emhttp/plugins/(APPNAME)/(APPNAME).page echo "" >> /usr/local/emhttp/plugins/(APPNAME)/(APPNAME).page cat /usr/local/emhttp/plugins/(APPNAME)/(APPNAME).php >> /usr/local/emhttp/plugins/(APPNAME)/(APPNAME).pagerm -f /usr/local/emhttp/plugins/(APPNAME)/(APPNAME).phpsed -i 's!\r!!g' /usr/local/emhttp/plugins/(APPNAME)/(APPNAME).page
What this does is moves the page file out of the webGUI folder which no longer exists and into the dynamix folder which is now standard from unraid beta 12 and up.It also copies the PHP page into the PAGE file since they no longer allow separate files.Then it removes the PHP file since having it there will cause weirdness on the plugin page.Then lastly, it clears out the ^M carrage file that windows left, which breaks the plugin from showing.I'll have my version 2.0.0 plugins compatible with the RC / Final when it's closer to release but updating these plugins right now will make earlier beta users plugins inoperable.
-
No. The old disk5 had issues. I replaced it with the current one. You can see the info from the past posts in this thread.
I will just format it and resync.
-
So then if I have this below that means I need to format disk5, resync, then parity check with correction off?

-
I followed the simple steps from http://lime-technology.com/wiki/index.php/UnRAID_Manual_5#Replace_a_failed_disk.
After powering on the machine I allowed it to sync and now running the parity check with correct any parity errors turned off. I still see disk5 as unformated as the parity sync is running.
Should I scrap the sync and then format the drive and run rebuild, then parity check without correction again? I did preclear the drive.
-
Frank1940 and bkastner you have both contributed a lot of very good information and to the point. I really appreciate your help.
I spent the rest of my Sunday researching the issue. I wonder if the semi seated SATA cable to the controller caused this. There is a train that rolls by about 100 feet away. Maybe the vibrations caused this? I have no issues doing what was suggested, I am just curious as to how disk5 had issues besides the high power on hours.
After looking at the syslog during bootup I took a more in depth look at disk5. I mounted the drive with mount -t reiserfs /dev/sdp1 /tmp/x. I cd'd to the dir and could view the folders. I was going to attempt to run Joe L's unraid_partition_disk but have now decided against it for the time being as I will just replace the drive with a precleared drive.
Do either of you folks have any recommendations / opinions on what I can do to this machine to extend the life of the hard drives current and new ones? Settings, configurations, scripts, spin down, etc
-
OK, good info regarding the bathtub curve.
Some drives have been on that long, huh? Wow
What is DSBL on disk5?
I have 2 3TB drive still in the package. I would preclear them, then what? What are the next steps to get the data from disk5?
Also, how do I properly swap a drive and have the data put back on?
Lastly, how do I determine the drives to replace from looking at the SMART Report?
I pulled the case off the rack. A few of SATA cables may have been not connected securely. Snugged them all up and powered on.
I now have this:
This is array off.

This is array on. This does not look good.

-
Your syslog shows both sdr and sdq having issues....and at first glance appear to be physical. Try the link above for details, but
in summary, SATA cable may be bad/loose. Also could be a power supply problem, so check that all connections are solid.
Perhaps those two drives share a common controller, are in the same drive cage, or share a SAS cable?
I have a 24 bay case. I'll need to open it up to get info. I no longer have it.
As far as I remember there are 3 cards for all 24 bays.
Is there anything I can do to test the hardware?
This is what I have today.
unRAID Version: 5.0
What should be my next step?
It also looks like you have an issue with disk4 as well as disk5. You should probably also list your hardware--- particularly what you are using for your SATA expansion cards. You also had two disks that failed to return smart data. (I suspect that these disks were disk4 and disk5 since they were not indicating that they were powered up--- no disk temperatures in the table.)
It also appears the you have a lot of disks with very high 'power on' hours. While the actual hours are only an indication that you could be reaching the end-of-life area of the bathtub failure curve, it does raise the risk for multiple disk failures substantially! I hope you have another backup of your critical data.
Why do they have high power on hours? How do I fix that? Is this bad?
-
-
I think it has to do with http://lime-technology.com/wiki/index.php/UnRAID_Manual#User_shares_2 I am not sure.
But I can't wrap my head around that.
Yes, shares are on. I am not sure how you would see data with shares being off.
What more info can I give you?
It may have something to do with the settings here, I believe: http://tower/Settings/ShareSettingsMenu
Included disk(s): All
Excluded disk(s): None
That is the current settings there.
-
What settings do I need to make so when I create a folder in a disk that is doesn't copy automatically to others disks?
I have disk1, disk2, disk3 etc. If I create "foldera" in disk1 I see it in disk2 and disk3 but it may be empty or it may have files.
I would like to keep every drive separate from each for the future.
How do I go about cleaning up what has been done? I have 15 drives.
I am using 5.0-rc11 currently but I don't believe my issue is with this version.




[6.3.3] Hard drive issues - disabled
in General Support
Posted
Yes I have rebooted multiple times. Could this possible be a hardware/cable issue?