




geofbennett
Members
-
Joined
-
Last visited
Everything posted by geofbennett
-
Just as a follow up and to close this out in case anybody has the same or similar problem in the future... I replaced the parity drive, restarted, and rebuilt parity over 30 days ago. Every weekly parity check since has turned up with zero errors. I also reset the data drive that had reported errors and it has not reported any problems since (though I have a feeling it will before long) The attached diagnostics no longer show any of the ata links as slow to respond. Thanks again to everybody for their help. the-dark-tower-diagnostics-20220922-1035.zip
-
Thanks again. After resetting everything back the way it was before (including original cables) I see that the ATA6 is showing the "slow to respond" message as well as some other messages that are not being mentioned for any of the other ports. Ok, new drive should be here Friday. Once it is installed should I check the diagnostics before or after rebuilding parity? Or Both? the-dark-tower-diagnostics-20220817-1704.zip
-
Swapped Disk 3 and Parity. I used the new cables, but couldn't switch the cables at the motherboard, had to switch the cables at the drives because one of the plugs has a 90deg bend and the other port on the board is obstructed. For my own edification, which log and which details are we looking at for the ATA errors? (if you can explain without too much effort that is, I'm so grateful for the help, I want to learn more but I don't want to put you guys out any more than I have to) the-dark-tower-diagnostics-20220817-1409.zip
-
Replaced both with the last 2 cables I had Disk 3 is in an ICY DOCK FatCage MB155SP-B Parity is connected directly to the motherboard Would it help to swap Disk 3 from it's current slot in the cage into a different slot to see if the ATA errors follow it or remain on that slot?
-
I'm glad I asked. Diagnostics attached the-dark-tower-diagnostics-20220817-1108.zip
-
Thanks. Just so I'm understanding correctly, 1. Replace Cables 2. Restart and run Parity Check (with corrections?) 3. Post Diagnostics
-
which is why I'm kinda cool with only 1 drive having errors, but I have 2 drives with errors (one of them the Parity drive) which makes me nervous. I understand my data is not on the parity drive but it is not the only drive showing errors.
-
It was my understanding that the Parity drive is what enables you to rebuild a Data drive if it should fail, but if you only have a single parity drive and multiple drives fail at the same time then you will lose data. Is that not true?
-
Sorry about that... Yes, Disk 3 is the one that reported errors last month. Any ideas about the error report for the parity drive? Or should I just not worry about it? That's what's kind of concerning to me. I'm cool with waiting a bit to see if more errors appear if it is only one disk, but being there are 2 and one of them is Parity I'm getting a little nervous.
-
/Settings/DiskSettings - Default spin down delay is already set to "Never". Is there another way to disable spindown? I've set the parity check scheduler "Write corrections to parity disk:" to "No", but the check mark next to "Write corrections to parity" on Main does not go away. I suspect that check mark only applies if I tell it to check parity outside the schedule, correct? Diagnostics attached the-dark-tower-diagnostics-20220816-1520.zip
-
About a month ago my server warned 4 times over 3 hours of “[5] reallocated sector ct” and once of “[187] reported uncorrect”. At the same time it was running it’s parity check, at the end of which it also reported parity errors. (I have it run a parity check w/ corrections weekly, and this was the first time it EVER reported parity errors) Understanding that the Data drive is probably on the way out the door, I acknowledged the errors and restarted the server to clear the warning and see how long it would take for it to report more errors That disk has not reported any more errors since then. However, the parity check has reported errors each week since. Then yesterday, before the parity check was finished, it sent me the following : “Event: Unraid array errors Subject: Warning [THE-DARK-TOWER] - array has errors Description: Array has 1 disk with read errors Importance: warning Parity disk - ST4000VN008-2DR166_ZDHAF8R2 (sdg) (errors 134) “ Running extended SMART tests on all Data disks (including the one the reported errors) returns “Completed without error”. However, the SMART test on the Parity drive ends with “Interrupted (host reset)” All disks are 4TB Seagate Ironwolf NAS. The drive that gave the initial errors was put into service in May 2018 (currently shows 37245 power on hours). The Parity drive was only installed last November (currently shows 6715 hours, and is thankfully still under warranty). (Also note that the Parity drive has a green thumbs up and says “Healthy” on the dashboard) Am I looking at replacing both drives? Any opinions on whether it was errors on the Data drive or problems with the Parity drive that has been causing the parity errors? Any suggestions on further tests of the Parity drive to aid in a warranty claim? Thanks for your help
-
For the record, replacing the bz files as described got my system back online. Thanks
-
I am having this same problem. I'd like to know exactly which suggestion solved the problem? Was it overwriting the bz files? Also, how did you do the power cycle? Clicking on the "reboot" button in the webGui does nothing for me, so I wonder is there another way or do I just pull the plug. Thanks
-
Tried to download diagnostics and got this message
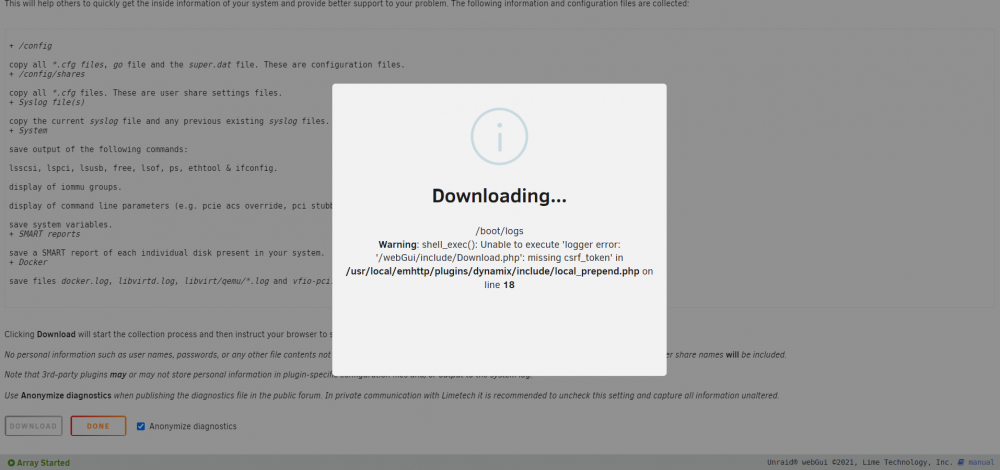
-
just tried again, and was able to get to the dashboard and home screens
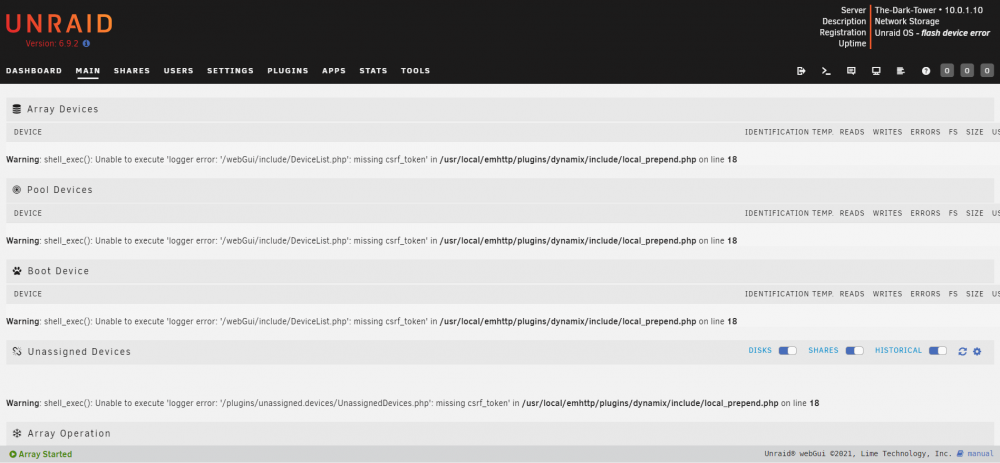
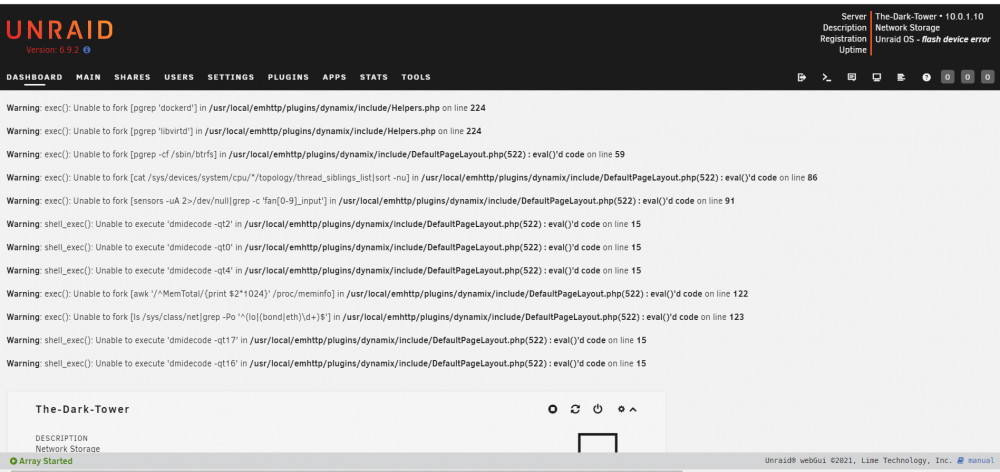
-
Sorry, I didn't think to take a screen shot before I shut down the web browser. Sorry, Like I said, I don't know scripting language. Every new thing I try I learn a little more, but removing the backslash was not mentioned on that page. I'll remember that if I should try this again, but I have a feeling that once I've fixed this, I will just delete old stuff manually from now on.
-
Let me begin by saying I know practically nothing about script language. I’ve been pretty lucky in figuring out how to make my UNRAID do what I want, but this problem is blowing my mind. I have the User scripts plugin installed on my server running one script every night that deletes any video files that are over 30 days old from my security camera share. It has worked great for a long time. Now I’ve been trying to add a line to the script to do the same thing for files in my PLEX DVR recorder share. This is the line I was working on: find /mnt/user/Media\ NAS/DVR\ Library/Judge\ Judy\ (1996)/* -type d -ctime +30 -exec rm -rf {} \; I have figured out that the line is failing because of the parentheses in the folder name and I was trying to figure out how to fix it… I found a post that suggested putting quotes around the path so I tried that find ‘/mnt/user/Media\ NAS/DVR\ Library/Judge\ Judy\ (1996) /’ * -type d -ctime +30 -exec rm -rf {} \; After running the script the webpage display changed putting a series of 3-4 warnings at the top and I could no longer edit the script. When I went to the Dashboard or Home the web-pages were displaying warnings and everything seemed out of order. I tried clicking on “Reboot” but nothing happened. I closed the web-browser and tried to log back in, but after entering my user and password I get a webpage with only two lines on it: Warning: exec(): Unable to fork [logger -t webGUI 'Successful login user root from 10.0.1.28'] in /usr/local/emhttp/login.php on line 97 Warning: Cannot modify header information - headers already sent by (output started at /usr/local/emhttp/login.php:97) in /usr/local/emhttp/login.php on line 98 Fortunately, it seems like the server is otherwise working ok. I can access the shares, and the dockers I use like Krusader, Plex, and Deluge are still working and accessible. It seems to be just the WebGUI that has been affected. Any help would be very usefull



