




NGMK
Members
-
Joined
-
Last visited
-
Thank for this, would I have to start from scratch on this if I already have all my metadata and database setup in a previous instance?
-
consider this one solved, the array is back online alone with the cache pool. I transferred the appdata recovered from the failed pool, I hope plex is able to recover. Thanks JorgeB for your assistance.
-
So I created a new share in a another cache pool I have with only one sata ssd and copied the appdata directory to it and judging by it size i believe all files are there. Should I just give up on the nvme pool (main) reformat and recreated the pool?
-
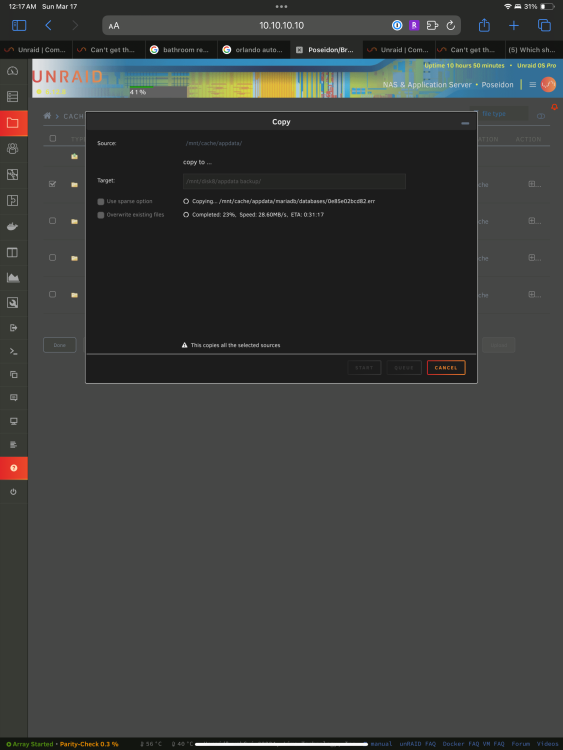
Yes I already tried zpool import -o readonly=on cache and was able to start the array with the cache on read only status, the cache pool is available on the gui file explorer, I tried coping the appdata folder to one of the array disks and all was going well until it just stayed on a single file transferring it forever
-
Yes I already did type [write] after, and I did this whole process more than once but the Array wont after, and I always end up having to reboot the server. the only data valuable inside the cache pool was my appdata and I have a 2 weeks old backup in the main array, however Im very concern on how this cache pool became so corrupted, this is the very first time me using ZFS and red on another post that zfs1 with 3 drives in a cache pool was only recommended in a experimental setting and not in a mission critical server. What else can we try here. I will prefer to save the pool if possible. New Diagnostics attached. poseidon-diagnostics-20240316-1430.zip
-
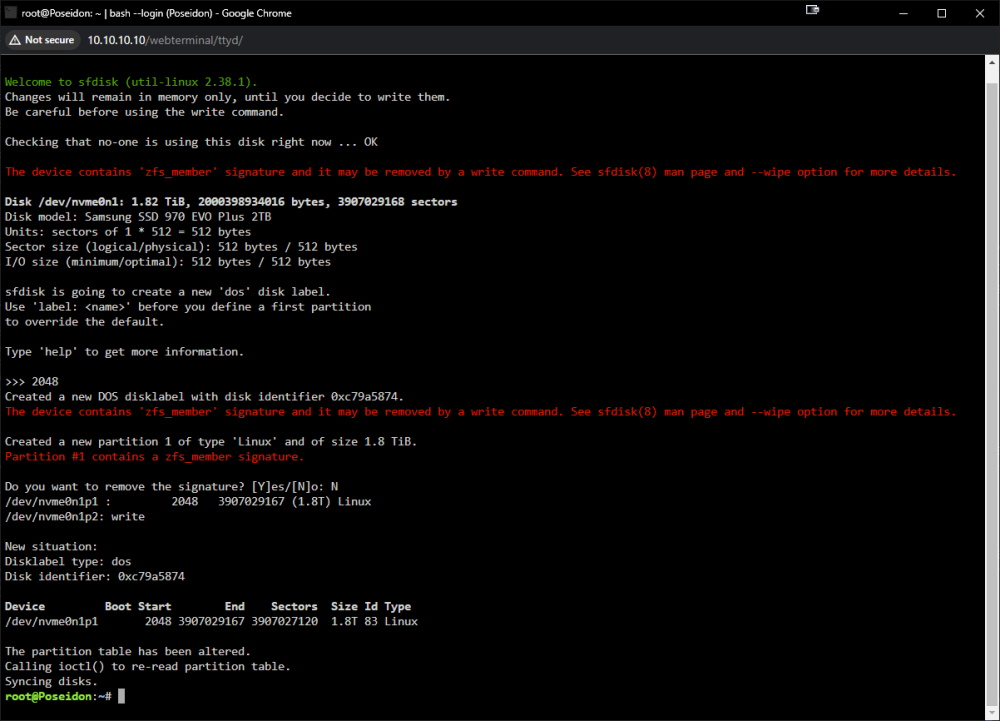
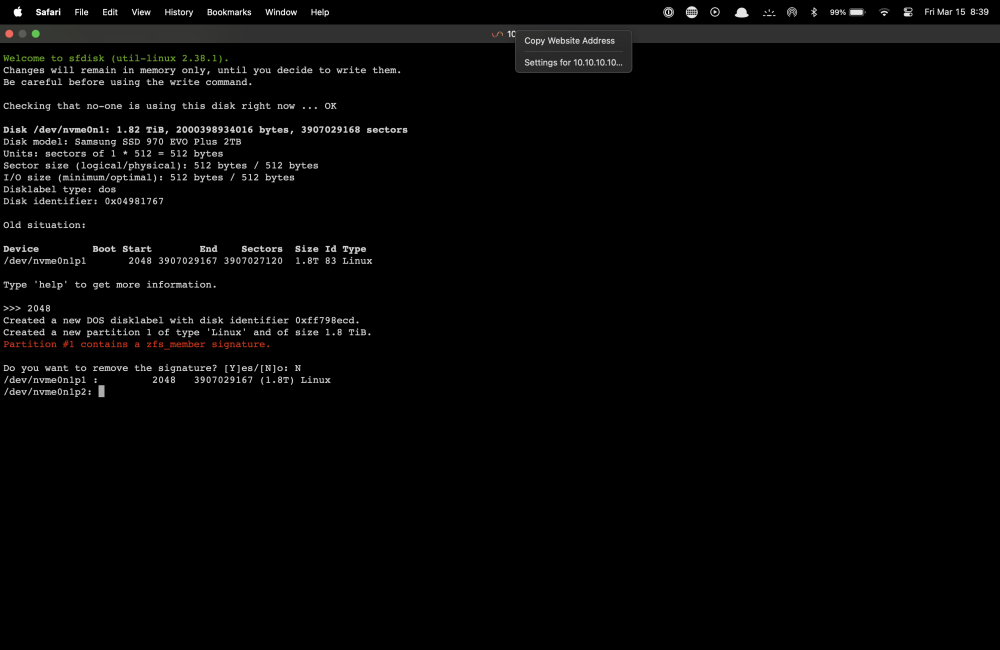
when you run the command [ sfdisk /dev/nvme0n1 ] then type [2048] then [N] to not remove the signature I get the following, asking for the other devices in the pool. I type write close the command line and try starting the array but it wont start. below if the screen shot and the new diagnostics P.S. I really appreciated you taking the time to help. poseidon-diagnostics-20240315-2031.zip
-
Array now starts after removing every nvme cache drives from the pool, starting the array without any drive in the pool, stoping the array, adding all three drives back to the cache pool in the same order. I left the FS as auto, now Unraid wants me to format the drives as right this moment the drives are not mountable. Whats next. poseidon-diagnostics-20240314-2127.zippool: cache id: 2664919203947636995 state: DEGRADED status: One or more devices contains corrupted data. action: The pool can be imported despite missing or damaged devices. The fault tolerance of the pool may be compromised if imported. see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J config: cache DEGRADED raidz1-0 DEGRADED nvme0n1 UNAVAIL invalid label nvme1n1p1 ONLINE nvme2n1p1 ONLINE before opening this post I found another post where someone was having an issues starting the array and was recommended by someone else to remove the cache pool drives. I attempted to do this but although I unassigned all three NVME drives from the pool in the UI when I started the array I realized that only the first drive was actually unassigned. This may be the cause of these results.This is a new log file after rebooting the server, I do not know how to disable rootshare related errors unless I get the log from syslog, and am not sure if those are okay to be openly shared. poseidon-diagnostics-20240314-0852.ziprecently I move my server to a bigger case everything was working fine, then couple of days later I upgraded my cache pool from 2 (1TB) sata ssd btrs to 3 (2TB) NVME using ZFS. after moving the appdata and recreating the docker image file, everything seem to be fine. after couple of days the server stopped responding and needed to be restarted, couple of days later even thou all other dockers were working, Plex was failing to start. After some trouble shooting I realized the docker image was corrupted and had to deleted and recreated it. The very next day the server crash again but this time after rebooting the server the array will get stuck starting but will never start. I rebooted the server several times with no luckI even tried safe mode. Suspecting the cache pool having something to do with this issues I decided to remove one the drive, I was able to start the array in safe mode, after that I stopped the array and re added the removed drive back to the cache pool and now unraid is recognizing the drive as a new drive and stating that all data will be erase from the drive if I start the array. All my appdata is in the cache, I do not have any VM. Any help will be appreciated. poseidon-diagnostics-20240313-2112.zipperform memory test over night "PASSED" replaced two 250GB cache ssd in raid 0 (500GB Total) for 2 1TB SSD in raid 1 for a total of TB Cache. Server has been Stable for over 2 weeks now. One of the SSD replace is now being used as an UNASSINGNED Device with CCR Error count of 23. I believe the SSD or cable/connector was the issues, maybe it was getting filled and there was a loose connection. ThanksI will bring the server offline and start with a memory test, and then follow your advice. Thanks for your reply.Been using Unraid for about 6 years now, for the most parts the server will be up for years a time only needing reboot, after updates or power outages/failures. but for the past 12-18 months Unraid has been hanging and becomes unresponsive thru the webgui and does not respond to ping requests. I was able to mirror the syslog to the boot usb drive. please point me out in the right direction. Also when the system hangs/crash I have a hard time getting the system back online. Sometime I have to reboot several time in order for the server to come back online. syslog (1) PS the date and time in question is; Dec 25 09:00:03 Poseidon crond[1153]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null Dec 25 12:06:54 Poseidon kernel: microcode: microcode updated early to revision 0x28, date = 2019-11-12 Server went offline at around 9am and I was able to reboot it at 12PM when I realized pi-hole was not working.




