

EarthYak
-
Posts
27 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by EarthYak
-
-
I have made that change, I will see what happens. Thanks
-
Unraid around 1-3 times a week at apparently random times is stopping and becoming unresponsive, the syslog shows this before it stops until I pull the power and restart. I restarted it the next day. Does anyone have any ideas, help would be gratefully appreciated.
Excerpt from the syslog, full log for the day attached:
Nov 2 20:16:13 Hydra kernel: rcu: INFO: rcu_sched self-detected stall on CPU
Nov 2 20:16:13 Hydra kernel: rcu: #01110-....: (59998 ticks this GP) idle=6ea/1/0x4000000000000002 softirq=203068959/203068959 fqs=14300
Nov 2 20:16:13 Hydra kernel: rcu: #011 (t=60001 jiffies g=284290801 q=1671571)
Nov 2 20:16:13 Hydra kernel: NMI backtrace for cpu 10
Nov 2 20:16:13 Hydra kernel: CPU: 10 PID: 435 Comm: smbd Tainted: G W O 4.19.107-Unraid #1
Nov 2 20:16:13 Hydra kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./X470D4U, BIOS P3.30 11/04/2019
Nov 2 20:16:13 Hydra kernel: Call Trace:
Nov 2 20:16:13 Hydra kernel: <IRQ>
Nov 2 20:16:13 Hydra kernel: dump_stack+0x67/0x83
Nov 2 20:16:13 Hydra kernel: nmi_cpu_backtrace+0x71/0x83
Nov 2 20:16:13 Hydra kernel: ? lapic_can_unplug_cpu+0x97/0x97
Nov 2 20:16:13 Hydra kernel: nmi_trigger_cpumask_backtrace+0x57/0xd4
Nov 2 20:16:13 Hydra kernel: rcu_dump_cpu_stacks+0x8b/0xb4
Nov 2 20:16:13 Hydra kernel: rcu_check_callbacks+0x296/0x5a0
Nov 2 20:16:13 Hydra kernel: update_process_times+0x24/0x47
Nov 2 20:16:13 Hydra kernel: tick_sched_timer+0x36/0x64
Nov 2 20:16:13 Hydra kernel: __hrtimer_run_queues+0xb7/0x10b
Nov 2 20:16:13 Hydra kernel: ? tick_sched_handle.isra.0+0x2f/0x2f
Nov 2 20:16:13 Hydra kernel: hrtimer_interrupt+0xf4/0x20e
Nov 2 20:16:13 Hydra kernel: smp_apic_timer_interrupt+0x7b/0x93
Nov 2 20:16:13 Hydra kernel: apic_timer_interrupt+0xf/0x20
Nov 2 20:16:13 Hydra kernel: </IRQ>Nov 2 21:58:13 Hydra kernel: rcu: INFO: rcu_sched self-detected stall on CPU
Nov 2 21:58:13 Hydra kernel: rcu: #01110-....: (6180101 ticks this GP) idle=6ea/1/0x4000000000000002 softirq=203068959/203068959 fqs=1502221
Nov 2 21:58:13 Hydra kernel: rcu: #011 (t=6180104 jiffies g=284290801 q=40981941)
Nov 2 21:58:13 Hydra kernel: NMI backtrace for cpu 10
Nov 2 21:58:13 Hydra kernel: CPU: 10 PID: 435 Comm: smbd Tainted: G W O 4.19.107-Unraid #1
Nov 2 21:58:13 Hydra kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./X470D4U, BIOS P3.30 11/04/2019
Nov 2 21:58:13 Hydra kernel: Call Trace:
Nov 2 21:58:13 Hydra kernel: <IRQ>
Nov 2 21:58:13 Hydra kernel: dump_stack+0x67/0x83
Nov 2 21:58:13 Hydra kernel: nmi_cpu_backtrace+0x71/0x83
Nov 2 21:58:13 Hydra kernel: ? lapic_can_unplug_cpu+0x97/0x97
Nov 2 21:58:13 Hydra kernel: nmi_trigger_cpumask_backtrace+0x57/0xd4
Nov 2 21:58:13 Hydra kernel: rcu_dump_cpu_stacks+0x8b/0xb4
Nov 2 21:58:13 Hydra kernel: rcu_check_callbacks+0x296/0x5a0
Nov 2 21:58:13 Hydra kernel: update_process_times+0x24/0x47
Nov 2 21:58:13 Hydra kernel: tick_sched_timer+0x36/0x64
Nov 2 21:58:13 Hydra kernel: __hrtimer_run_queues+0xb7/0x10b
Nov 2 21:58:13 Hydra kernel: ? tick_sched_handle.isra.0+0x2f/0x2f
Nov 2 21:58:13 Hydra kernel: hrtimer_interrupt+0xf4/0x20e
Nov 2 21:58:13 Hydra kernel: smp_apic_timer_interrupt+0x7b/0x93
Nov 2 21:58:13 Hydra kernel: apic_timer_interrupt+0xf/0x20
Nov 2 21:58:13 Hydra kernel: </IRQ>
Nov 2 21:58:13 Hydra kernel: RIP: 0010:radix_tree_descend+0x16/0x57
Nov 2 21:58:13 Hydra kernel: Code: 48 8b 42 08 4c 89 4a 08 48 89 57 18 48 89 47 20 4c 89 08 c3 0f b6 0f 48 89 d0 48 d3 e8 83 e0 3f 89 c2 48 8d 54 d7 28 48 8b 12 <48> 89 d1 83 e1 03 48 ff c9 75 32 48 8d 4f 28 48 39 ca 72 29 4c 8d
Nov 2 21:58:13 Hydra kernel: RSP: 0018:ffffc9000c657c70 EFLAGS: 00000202 ORIG_RAX: ffffffffffffff13
Nov 2 21:58:13 Hydra kernel: RAX: 000000000000001f RBX: 000000000001f518 RCX: 000000000000000c
Nov 2 21:58:13 Hydra kernel: RDX: ffff888106090001 RSI: ffffc9000c657c78 RDI: ffff888102ff8db0
Nov 2 21:58:13 Hydra kernel: RBP: ffff888151151078 R08: ffff888151151078 R09: ffffc9000c657ca8
Nov 2 21:58:13 Hydra kernel: R10: 0000000000000000 R11: ffff888151151070 R12: 00000000006200ca
Nov 2 21:58:13 Hydra kernel: R13: ffff888151151068 R14: 0000000000001000 R15: 000000000001f518
Nov 2 21:58:13 Hydra kernel: __radix_tree_lookup+0x69/0xa2
Nov 2 21:58:13 Hydra kernel: radix_tree_lookup_slot+0x1e/0x41
Nov 2 21:58:13 Hydra kernel: find_get_entry+0x14/0x8f
Nov 2 21:58:13 Hydra kernel: pagecache_get_page+0x20/0x1bd
Nov 2 21:58:13 Hydra kernel: grab_cache_page_write_begin+0x1a/0x31
Nov 2 21:58:13 Hydra kernel: fuse_perform_write+0x178/0x43a
Nov 2 21:58:13 Hydra kernel: ? file_remove_privs+0x55/0xb9
Nov 2 21:58:13 Hydra kernel: fuse_file_write_iter+0x1b6/0x22f
Nov 2 21:58:13 Hydra kernel: __vfs_write+0xfc/0x13a
Nov 2 21:58:13 Hydra kernel: vfs_write+0xc7/0x166
Nov 2 21:58:13 Hydra kernel: ksys_pwrite64+0x5d/0x79
Nov 2 21:58:13 Hydra kernel: do_syscall_64+0x57/0xf2
Nov 2 21:58:13 Hydra kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
Nov 2 21:58:13 Hydra kernel: RIP: 0033:0x14d2885a3ed7
Nov 2 21:58:13 Hydra kernel: Code: 08 89 3c 24 48 89 4c 24 18 e8 05 f3 ff ff 4c 8b 54 24 18 48 8b 54 24 10 41 89 c0 48 8b 74 24 08 8b 3c 24 b8 12 00 00 00 0f 05 <48> 3d 00 f0 ff ff 77 2d 44 89 c7 48 89 04 24 e8 35 f3 ff ff 48 8b
Nov 2 21:58:13 Hydra kernel: RSP: 002b:000014d2867e8bf0 EFLAGS: 00000293 ORIG_RAX: 0000000000000012
Nov 2 21:58:13 Hydra kernel: RAX: ffffffffffffffda RBX: 000055f7b41e7890 RCX: 000014d2885a3ed7
Nov 2 21:58:13 Hydra kernel: RDX: 0000000000100000 RSI: 000055f7b4631850 RDI: 000000000000001f
Nov 2 21:58:13 Hydra kernel: RBP: 000055f7b3e7fff0 R08: 0000000000000000 R09: 00000000ffffffff
Nov 2 21:58:13 Hydra kernel: R10: 000000001f500000 R11: 0000000000000293 R12: 000014d2867e8c70
Nov 2 21:58:13 Hydra kernel: R13: 000055f7b3e80028 R14: 000055f7b3efaf50 R15: 000014d289f850a0
Nov 2 21:58:42 Hydra kernel: rcu: INFO: rcu_bh self-detected stall on CPU
Nov 2 21:58:42 Hydra kernel: rcu: #01110-....: (6222689 ticks this GP) idle=6ea/1/0x4000000000000002 softirq=203061910/203068959 fqs=1457949
Nov 2 21:58:42 Hydra kernel: rcu: #011 (t=6000105 jiffies g=19189 q=8)
Nov 2 21:58:42 Hydra kernel: NMI backtrace for cpu 10
Nov 2 21:58:42 Hydra kernel: CPU: 10 PID: 435 Comm: smbd Tainted: G W O 4.19.107-Unraid #1
Nov 2 21:58:42 Hydra kernel: Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./X470D4U, BIOS P3.30 11/04/2019
Nov 2 21:58:42 Hydra kernel: Call Trace:
Nov 2 21:58:42 Hydra kernel: <IRQ>
Nov 2 21:58:42 Hydra kernel: dump_stack+0x67/0x83
Nov 2 21:58:42 Hydra kernel: nmi_cpu_backtrace+0x71/0x83
Nov 2 21:58:42 Hydra kernel: ? lapic_can_unplug_cpu+0x97/0x97
Nov 2 21:58:42 Hydra kernel: nmi_trigger_cpumask_backtrace+0x57/0xd4
Nov 2 21:58:42 Hydra kernel: rcu_dump_cpu_stacks+0x8b/0xb4
Nov 2 21:58:42 Hydra kernel: rcu_check_callbacks+0x296/0x5a0
Nov 2 21:58:42 Hydra kernel: update_process_times+0x24/0x47
Nov 2 21:58:42 Hydra kernel: tick_sched_timer+0x36/0x64
Nov 2 21:58:42 Hydra kernel: __hrtimer_run_queues+0xb7/0x10b
Nov 2 21:58:42 Hydra kernel: ? tick_sched_handle.isra.0+0x2f/0x2f
Nov 2 21:58:42 Hydra kernel: hrtimer_interrupt+0xf4/0x20e
Nov 2 21:58:42 Hydra kernel: smp_apic_timer_interrupt+0x7b/0x93
Nov 2 21:58:42 Hydra kernel: apic_timer_interrupt+0xf/0x20
Nov 2 21:58:42 Hydra kernel: </IRQ>
Nov 2 21:58:42 Hydra kernel: RIP: 0010:radix_tree_descend+0x13/0x57
Nov 2 21:58:42 Hydra kernel: Code: 4c 89 c2 48 8b 42 08 4c 89 4a 08 48 89 57 18 48 89 47 20 4c 89 08 c3 0f b6 0f 48 89 d0 48 d3 e8 83 e0 3f 89 c2 48 8d 54 d7 28 <48> 8b 12 48 89 d1 83 e1 03 48 ff c9 75 32 48 8d 4f 28 48 39 ca 72
Nov 2 21:58:42 Hydra kernel: RSP: 0018:ffffc9000c657c70 EFLAGS: 00000206 ORIG_RAX: ffffffffffffff13
Nov 2 21:58:42 Hydra kernel: RAX: 0000000000000014 RBX: 000000000001f518 RCX: 0000000000000006
Nov 2 21:58:42 Hydra kernel: RDX: ffff8881060900c8 RSI: ffffc9000c657c78 RDI: ffff888106090000
Nov 2 21:58:42 Hydra kernel: RBP: ffff888151151078 R08: ffff888102ff8ed0 R09: ffffc9000c657ca8
Nov 2 21:58:42 Hydra kernel: R10: 0000000000000000 R11: ffff888151151070 R12: 00000000006200ca
Nov 2 21:58:42 Hydra kernel: R13: ffff888151151068 R14: 0000000000001000 R15: 000000000001f518
Nov 2 21:58:42 Hydra kernel: __radix_tree_lookup+0x69/0xa2
Nov 2 21:58:42 Hydra kernel: radix_tree_lookup_slot+0x1e/0x41
Nov 2 21:58:42 Hydra kernel: find_get_entry+0x14/0x8f
Nov 2 21:58:42 Hydra kernel: pagecache_get_page+0x20/0x1bd
Nov 2 21:58:42 Hydra kernel: grab_cache_page_write_begin+0x1a/0x31
Nov 2 21:58:42 Hydra kernel: fuse_perform_write+0x178/0x43a
Nov 2 21:58:42 Hydra kernel: ? file_remove_privs+0x55/0xb9
Nov 2 21:58:42 Hydra kernel: fuse_file_write_iter+0x1b6/0x22f
Nov 2 21:58:42 Hydra kernel: __vfs_write+0xfc/0x13a
Nov 2 21:58:42 Hydra kernel: vfs_write+0xc7/0x166
Nov 2 21:58:42 Hydra kernel: ksys_pwrite64+0x5d/0x79
Nov 2 21:58:42 Hydra kernel: do_syscall_64+0x57/0xf2
Nov 2 21:58:42 Hydra kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
Nov 2 21:58:42 Hydra kernel: RIP: 0033:0x14d2885a3ed7
Nov 2 21:58:42 Hydra kernel: Code: 08 89 3c 24 48 89 4c 24 18 e8 05 f3 ff ff 4c 8b 54 24 18 48 8b 54 24 10 41 89 c0 48 8b 74 24 08 8b 3c 24 b8 12 00 00 00 0f 05 <48> 3d 00 f0 ff ff 77 2d 44 89 c7 48 89 04 24 e8 35 f3 ff ff 48 8b
Nov 2 21:58:42 Hydra kernel: RSP: 002b:000014d2867e8bf0 EFLAGS: 00000293 ORIG_RAX: 0000000000000012
Nov 2 21:58:42 Hydra kernel: RAX: ffffffffffffffda RBX: 000055f7b41e7890 RCX: 000014d2885a3ed7
Nov 2 21:58:42 Hydra kernel: RDX: 0000000000100000 RSI: 000055f7b4631850 RDI: 000000000000001f
Nov 2 21:58:42 Hydra kernel: RBP: 000055f7b3e7fff0 R08: 0000000000000000 R09: 00000000ffffffff
Nov 2 21:58:42 Hydra kernel: R10: 000000001f500000 R11: 0000000000000293 R12: 000014d2867e8c70
Nov 2 21:58:42 Hydra kernel: R13: 000055f7b3e80028 R14: 000055f7b3efaf50 R15: 000014d289f850a0 -
My build with the x470du is complete now, it has been running perfectly for 2 days. Aside from the points noted above, I have no complaints. The 3700x has been more than sufficient for my needs and booting from a USB 3.0 port has caused no problems so far. I am back running unraid 3.7.2 without issue.
The only thing that is not working at the moment is that Dynamix System Temperature is not detecting any sensors. That said it didn't work on my old Tyan dual socket board and it is not a major issue.
The IPMI is great so far, I would like the ability to adjust more settings through it but all the functions you need are there and the ability to flash the BIOS will be very useful I suspect.
I have not attempted to run any VMs yet, it will probably be a week or two before I have the time to. My dockers were the priority.
-
Quick update on progress.
I am replacing the CPU and Motherboard after my Motherboard failed on my previous server.
I quickly attempted to boot the server tonight my old installation would not boot, it generated kernel errors on starting Unraid. I booted it up successfully with another flash drive on 6.8.0 rc4 though. I know the kernel has been updated in the 6.8.0 update.
I will attempt to transition my flash drive to the new installation tomorrow or Sunday, then I can start testing it properly.
-
2 hours ago, Hoopster said:
What would really be nice is an X570D4U in an ATX form factor with at least one more PCIe slot, and a few more USB ports.
That would be an improvement. I would have liked another couple of USBs, after the flash drive and a keyboard you have to rely on the case having ports. I would have liked another PCIe slot too, I only plan on using 1 or 2 HBAs and maybe upgrading to 10Gbe later but that would fill the board. I am only using one HBA at the moment though so it is a future issue and I could solve it with a bigger HBA, although a new motherboard would probably be cheaper.
The IPMI is what ended up selling me on it over a full ATX x470 or x570. My new server location is a chore to get to and occasionally I am away when I need to work on it.
The X399D8A is a good alternative though if you want to use a 2nd Gen Threadripper instead. It didn't make sense for me though.
-
I have just had one delivered today to use with a 3700x. It was fine to build with, I would rather have a full ATX board though. I will update you once I have successfully booted the system.
-
 1
1
-
-
As best I can tell my flash drive just died so there may be some delay until I can get it back up and running.
-
On 9/24/2019 at 7:30 AM, johnnie.black said:
Cache files system is corrupt, best bet it's to reformat, if it keeps getting corrupt you might have an underlying hardware problem, also note that because of this bug cache pool is not redundant.
I reformatted my cache pool and started again but 2 weeks later I have corrupt BTRFS leaves again. I have moved my cache drives from the SAS backplane to the SATA connectors on the motherboard, I have replaced the SSDs over the last year, the cables and the HBA (although this is now only used for the HDDs) is there anything more I can check on the system? I need the system to be stable.
-
Today fix common problems has found that I am unable to write to my cache pool as well as my docker image. My docker image is on the cache pool so I assume that it is a problem with the cache rather than docker.
My syslog has filled up after a restart inside around an hour with errors like this:
Sep 23 19:49:41 Hydra kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 238, rd 0, flush 1, corrupt 0, gen 0
I can't see any issues in the SMART status of the two cache drives and I recently recreated the cache after formatting the SSDs. Around a week ago I moved my SSDs off my SAS backplane and directly connected them to the motherboard, changing cables in the process.
Any help would be gratefully received.
-
On 9/3/2019 at 4:16 PM, johnnie.black said:
Best way forward is to backup cache data, re-format and restore.
Those connection issues with SSDs are usually cable related, Samsung SSDs especially can be very picky with connection quality, also keep in mind that trim won't work when connected to that LSI, so if possible use the Intel SATA ports instead for both.
This has worked, I have run the system for 4 days now without an error. I just need to find somewhere in the case to secure them now!
Thanks for the help.
-
1 minute ago, johnnie.black said:
Best way forward is to backup cache data, re-format and restore.
Those connection issues with SSDs are usually cable related, Samsung SSDs especially can be very picky with connection quality, also keep in mind that trim won't work when connected to that LSI, so if possible use the Intel SATA ports instead for both.
Thank you, I will give that a go over the weekend.
-
3 minutes ago, johnnie.black said:
Those are checksum errors on the cache pool, one of the devices is dropping, see her for better pool monitoring:
https://forums.unraid.net/topic/46802-faq-for-unraid-v6/?do=findComment&comment=700582
Thanks for this info and a helpful FAQ post, I have taken on board this and set up an alert.
This leaves me with two questions, what do I do with the 4 unrecoverable errors and is there a possible cause for this I should be running down?
-
I am intermittently seeing issues like this in the syslog but so far not whilst I have been actively using the system.
Sep 3 12:16:20 Hydra kernel: print_req_error: I/O error, dev sdf, sector 196540536
Sep 3 12:16:22 Hydra kernel: BTRFS info (device sdf1): read error corrected: ino 968554 off 3047620608 (dev /dev/sdf1 sector 196540472)
Sep 3 12:16:22 Hydra kernel: BTRFS info (device sdf1): read error corrected: ino 515522 off 22855680 (dev /dev/sdf1 sector 637687392)
Sep 3 12:16:22 Hydra kernel: BTRFS info (device sdf1): read error corrected: ino 515522 off 58761216 (dev /dev/sdf1 sector 396601400) -
Starting today, I have noticed delays when transferring large files to my unraid server. I looked through the Syslog but found nothing highlighted at the times of the file transfers. When I copy files to the cache over the network, most recently at 2155 02/09/2019 in the logs, I can see high IOWait %s but nothing in the syslog.
I have balanced and scrubbed the cache today, before 2155.
I have experienced similar issues before and have now replaced (in the last year) the HBA, cables and SSDs and had 6+ months without an issue. Does anyone have any ideas?
Thanks in advance.
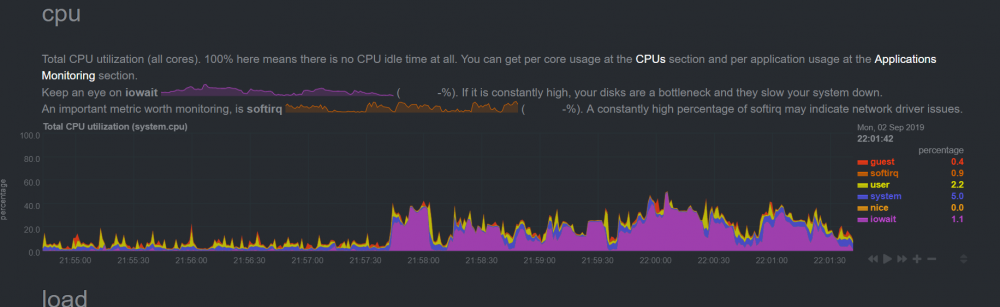
-
Well I was on the beta docker and I made the mistake of not checking this before updating. I am having the same issues now.
-
2 hours ago, CorneliousJD said:
I tried that but it still won't show up in the controller at all, it doesn't give me any sort of error either?
There have been a few changes to the various versions of the Docker in the last few days and I have flitted between the different branches as well so my experience may not be of much use but I had the same issue. I ended up deleting the docker, reinstalling it and then my cameras were manageable again, I did have to readopt them but it saved me getting my ladders out.
I tried factory resetting one of them first but it didn't solve my issue, it also happened with a camera I had just taken out of the box. The delete and reinstall worked fine though. Any time I did not delete the whole docker and it's disk the issue just continued.
-
1 hour ago, CorneliousJD said:
Let it run long enough again this time and it starts locking up the server pretty much until I end this container, but I gathered some logs
2019-02-18 08:38:49.997164 [warn] PUID not defined (via -e PUID), defaulting to '99' 2019-02-18 08:38:50.179288 [warn] PGID not defined (via -e PGID), defaulting to '100' 2019-02-18 08:38:50.341849 [info] Permissions already set for volume mappings Starting unifi-video... (unifi-video) checking for system.properties and truststore files... done. /run.sh: line 107: 7858 Aborted mongo --quiet localhost:7441 --eval "{ ping: 1}" > /dev/null 2>&1 /run.sh: line 107: 8125 Aborted mongo --quiet localhost:7441 --eval "{ ping: 1}" > /dev/null 2>&1 /run.sh: line 107: 8802 Aborted mongo --quiet localhost:7441 --eval "{ ping: 1}" > /dev/null 2>&1 /run.sh: line 107: 8884 Aborted mongo --quiet localhost:7441 --eval "{ ping: 1}" > /dev/null 2>&1 /run.sh: fork: retry: Resource temporarily unavailable /run.sh: fork: retry: Resource temporarily unavailableThen when I closed the container it ended with this.
/run.sh: line 107: 26679 Aborted mongo --quiet localhost:7441 --eval "{ ping: 1}" > /dev/null 2>&1 Waiting for mongodb to come online......................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................EDIT: For now I changed my repo to pducharme/unifi-video-controller:3.9.11 and it's at least up and online now.
Although all my previous recordings appear to be gone

Have you tried restoring your recordings? In system configuration. You should only be having issues with the database that locates them, the recordings are in another share.
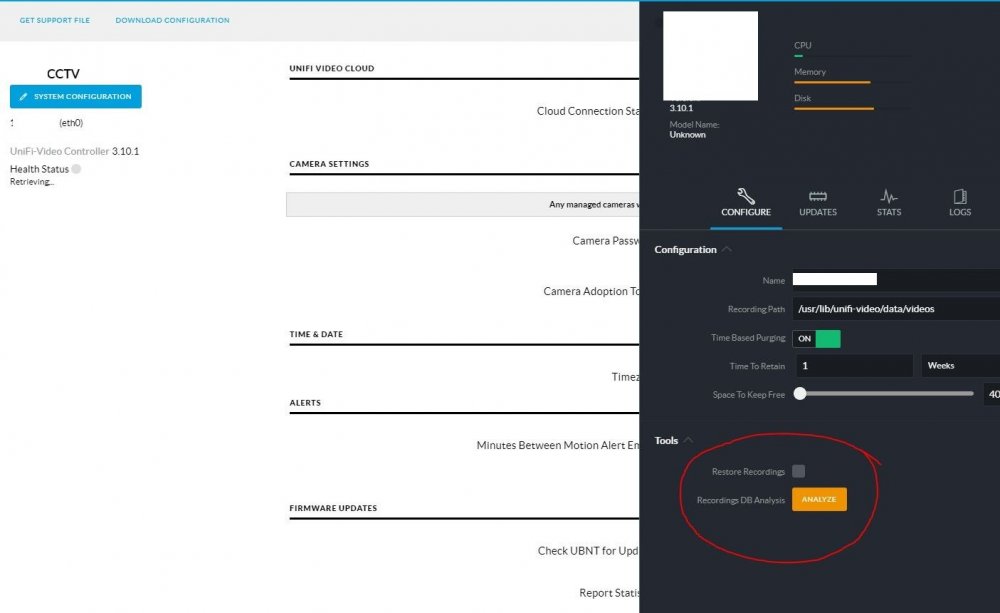
-
Thank you for the help. I have deleted them now.
-
I have just been trying to troubleshoot a DNS issue in one of my containers and went back to my containers list after 5 minutes, I now have 3 new containers listed:
tender_hawking
trusting_keller
unruffled_sammet
I have not started them or updated them. Not much is showing up after a quick check on google either. Does anyone have any ideas?
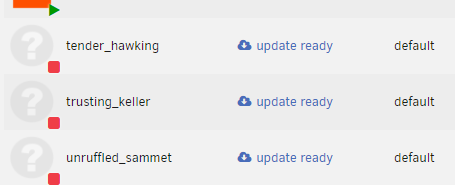
-
I have replaced the cable to that backplane and the SSD and that appears to have resolved the issue entirely. Thanks for the help.
-
Also I ran the scrub and no errors were found.
-
On 11/26/2018 at 11:56 PM, johnnie.black said:
Yes, lots of issues with a cache device, and they have been happening for some time, since on this boot you already had millions of read/write errors:
Nov 23 16:31:39 Hydra kernel: BTRFS info (device sdf1): bdev /dev/sdg1 errs: wr 7631833, rd 7087230, flush 306, corrupt 0, gen 0With SSDs these are most times cable/connection issues, so start by changing the cables on the Kingston SSD, you should then run a scrub and make sure there are no uncorrectable errors.
Thanks for the help, I have changed the cable to the back plane the Kingston SSD sits on and moved the other SSD to that back plane.
I have tested twice with a 30Gb file, both times the transfer failed and both times multiple of this error appeared:
Nov 28 16:48:35 Hydra kernel: sd 7:0:1:0: attempting task abort! scmd(00000000da5f4e73)
Nov 28 16:48:35 Hydra kernel: sd 7:0:1:0: tag#26 CDB: opcode=0x0 00 00 00 00 00 00
Nov 28 16:48:35 Hydra kernel: scsi target7:0:1: handle(0x0009), sas_address(0x4433221102000000), phy(2)
Nov 28 16:48:35 Hydra kernel: scsi target7:0:1: enclosure logical id(0x500605b00450fb30), slot(1)
Nov 28 16:48:35 Hydra kernel: sd 7:0:1:0: task abort: SUCCESS scmd(00000000da5f4e73)
Nov 28 16:48:35 Hydra kernel: sd 7:0:1:0: Power-on or device reset occurred
Nov 28 16:48:36 Hydra kernel: sd 7:0:1:0: Power-on or device reset occurredBut none of the original errors. I am pretty sure that "sd 7:0:1:0:" refers to the Kingston's location as below.
*-disk:1
description: ATA Disk
product: KINGSTON SA400S3
physical id: 0.1.0
bus info: scsi@7:0.1.0
logical name: /dev/sdc
version: 71E0
serial: 50026B777A014273
size: 223GiB (240GB)
capacity: 223GiB (240GB)
capabilities: 15000rpm partitioned partitioned:dos
configuration: ansiversion=6 logicalsectorsize=512 sectorsize=512Does this make it more likely that I am now looking at a fault with the SSD aswell as/instead of the cable?
-
I am using Teracopy to copy/move files to and from a windows 10 machine and the server still responds to pings whilst "frozen".
-
I am running Unraid 6.6.3, when I transfer files, large or small the transfer will sometimes freeze, it is impossible to get through a >10Gb file without this happening. When this happens the GUI is unreachable as are all dockers from any device. My Unraid server is on an 802.3ad ethernet connection (2 physical links), having checked on the switch the server is attached to, only one link is ever saturated and during the freeze the links go down to only background levels of traffic. I have tested this during a freeze and traffic balanced down either link is affected. The freeze can last for 2-5 minutes, then everything resumes as normal. This was an issue before I aggregated the links as well.
Any help would be appreciated.




Unraid becoming unresponsive CPU Stall
in General Support
Posted
I have given it a month to assess the change, I have set Power Supply Idle Control to typical and my RAM is at 2400 with 4 sticks so I think from the tables that is fine. I have still had at least one crash each week since then. Can anyone point me where to go next?