




hades
Members
-
Joined
-
Last visited
-
Hopefully this is a small item to add. I run quite a few VMs across 4-5 UnRAID servers, some have ~15VMs running on them. It would be nice to quickly see how much RAM is allocated, and whether I can start up another VM. Right now I need to go to the Dashboard, scroll down, figure out how much is 30% of 128GB, and whether my new VM fits into that. Just a simple number "RAM: 78/128GB" or something either at the top beside "HD % free" indicator, or at the status-bar on the bottom of the website would be awesome. Thank you!
-
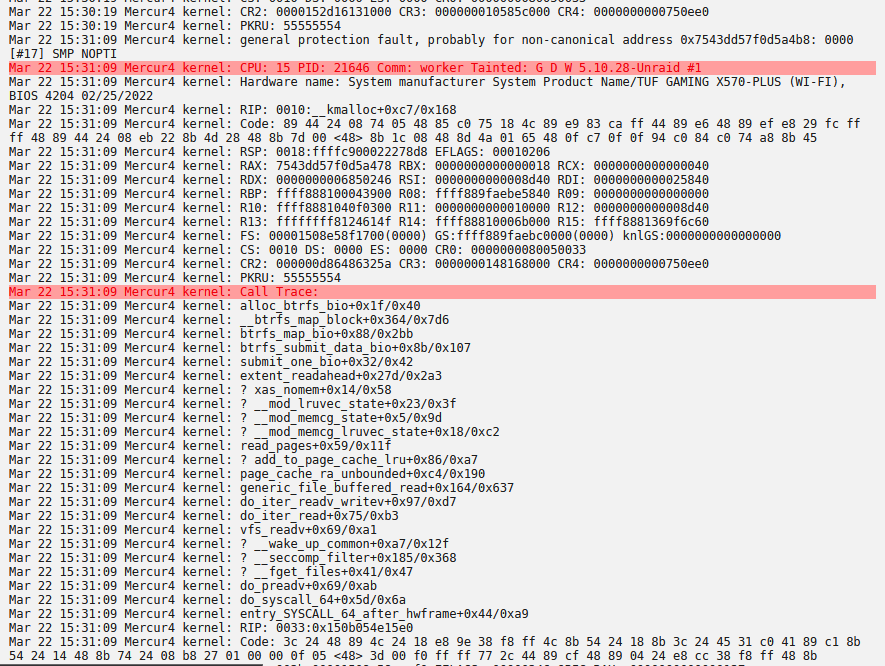
Also, the logs are now full of these types of errors. This is server4: Is this related? EDIT 20 minutes later: Awesome... The entire server died. Had to do a hard-reboot. This is the longest, most frustrating, and most expensive, experience with UnRAID/Linux/whatever...
-
Good catch on Server4. Thank you. I went through all 4 servers, set the RAM speed to 2666 (disabled the XMProfiles), and made sure that the Power Limit something is set to "Typical". I then ran scrub, which identified a few files as corrupted. Those files have been deleted. Just focusing on Server4 for now. I ran scrub a few times yesterday and no errors. It ran fine for 1.5 days, and is now showing the same types of errors again. The tutorial says to run RAM at 2666, check. Power Limit something = Typical, check. VMs which so far seem to have been unaffected are now showing up as corrupted. Is this a Ryzen thing ONLY? If so, I am good to go and buy an Intel-based MB & CPU as replacement. It's going to come out cheaper than the productivity I and the team are losing out on due to issues like this... Thank you. Server4-diagnostics-20220322-1517.zip
-
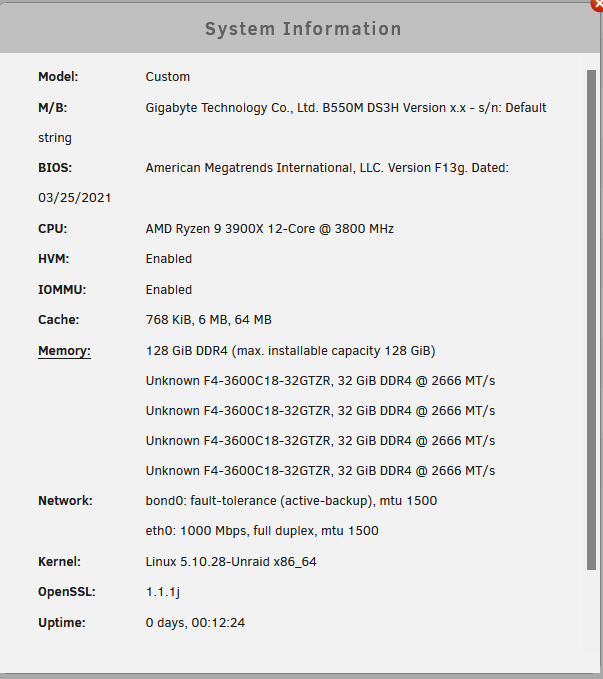
Thank you for the quick response. I already did this (from the FAQ): "find "Power Supply Idle Control" (or similar) and set it to "typical current idle" (or similar)." I just checked the server I'm concentrating on fixing, it's running at 2666Mhz, which is what the RAM is designed for. Should I slow the RAM down? I'm already getting these errors 12 minutes after bootup. Once these errors occur, would they go away if the underlying problem (let's say RAM out-of-spec) is fixed? Or would the pool need to be formatted for the errors to go away? Thank you!
-
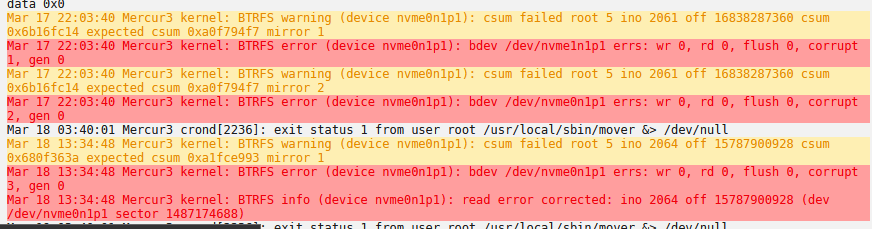
Hello Everyone! I'm struggling with some data corruption happening on multiple servers (glorified desktops). In total I have 8 UnRAID installations. 2 older ones which have been running fine for years, with multiple disks and VMs, no problems. This post is not about these two. More recently however, I've bought 6 almost-identical Ryzen-based servers (it's a business environment). All of them are: - Ryzen CPU, 12 or 16 core - 128GIG RAM - 3x 6TB drives for storage (xfs) in the array, one parity - 2x 2TB NVMe drives, Samsung 970EVO Plus (in a cache-pool as BTRFS) - weak GPU used for computer booting only All of them contain data on the arrays, and run ~10 VMs (mainly Windows) on which people do remote work. Recently on 4 of these Ryzen machines I've been plagued by BTRFS errors, usually this: Sometimes this results in the filesystem going into read-only mode, effectively taking down the dockers and VMs, forcing me to reboot, after which everything works for a day or so and then this repeats. Two of my Ryzen servers are installed in one location, they're running perfectly. In another location, I had 1 server running for 6 months without issues, then bought Server #2 due to capacity issues, which ran fine for a few months. Then Server #1 started having issues, and I urgently needed things to work, so I bought Server #3 to move the data/VMs onto it. Pretty quickly Server #3 started experiencing the same thing. Because I was planning on buying Server #4 anyway, I did, just installed it a few days ago, and it's already experiencing this problem. The motherboards and RAM are not completely identical. All NVMe-s were Samsung 970EVO Plus 2TB, and because this error is on the NVMe, I bought different NVMe-s for Server #4, it is using WD 2TB NVMe-s, but it's experiencing the same problem. Given the variation in hardware, and the chances of a component failing (which is somewhat rare) I highly doubt this is a hardware problem. But I'm now at a loss as to what is happening. It's eating up my hours and days, trying to stabilize things, make sure employees are able to do their jobs. Everyone works remotely, they need this to work on the data and execute long-running jobs. I'm in the process of clearing out one of the servers, so I can remove it from the network and do some tests on it without any data/VMs. Logs for all 4 servers are attached. Any help would be appreciated! Thank you. Server4-diagnostics-20220319-1738.zip Server3-diagnostics-20220319-1738.zip Server2-diagnostics-20220319-1738.zip Server1-diagnostics-20220319-1738.zip
-
Thank you Alex. I tried that command: root@winserver:/boot/config/plugins# cache_dirs -w -U 5000 sed: error while loading shared libraries: libc.so.6: failed to map segment from shared object: Cannot allocate memory sed: error while loading shared libraries: libc.so.6: failed to map segment from shared object: Cannot allocate memory sed: error while loading shared libraries: libc.so.6: failed to map segment from shared object: Cannot allocate memory sed: error while loading shared libraries: libc.so.6: failed to map segment from shared object: Cannot allocate memory ./cache_dirs: xmalloc: make_cmd.c:100: cannot allocate 365 bytes (98304 bytes allocated) It's a 64bit unRAID running on a machine with 16gigs RAM. I tried different -U values with the same result. What denominations are the values in? Bytes? Kilobytes? Thank you.
-
Hello, I installed this script into my server. It seems to work well, the folders are displayed without disk spin-up. However, when I checked this morning, I'm getting a bunch of errors displayed onto the console: ./cache_dirs: line 500: 28393 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 ./cache_dirs: line 500: 28620 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 ./cache_dirs: line 500: 28840 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 ./cache_dirs: line 500: 29049 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 ./cache_dirs: line 500: 29271 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 ./cache_dirs: line 500: 29482 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 ./cache_dirs: line 500: 29700 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 ./cache_dirs: line 500: 29923 Segmentation fault $command "$i"/"$share_dir" $args $depth > /dev/null 2>&1 Any thoughts? Thank you!


