




k2x8
Members
-
Joined
-
Last visited
-
Seems it was recently updated! Thanks devs!
-
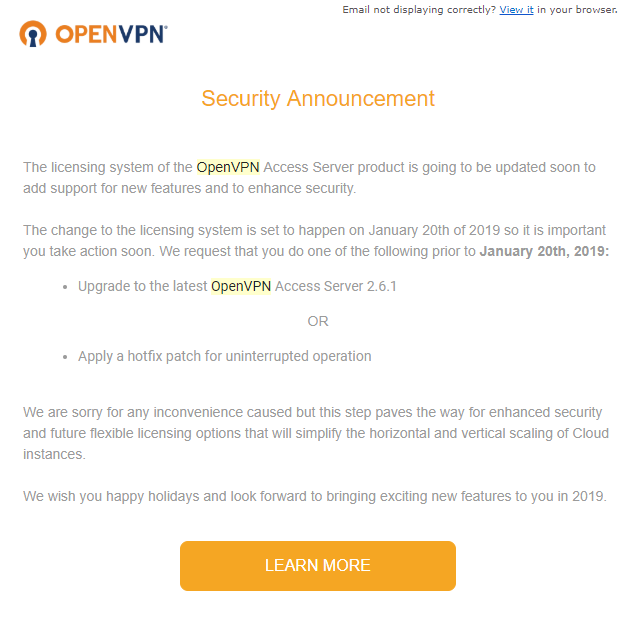
Not sure if anyone else pays for a licence but OpenVPN is changing their licencing structure and an update to 2.6.1 is required to support it when the change happens on January 20th 2019. Currently the latest version this app supports is 2.5.2, are there plans for an update before the 20th to at least 2.6.1 version? Screenshot attached with the email from OpenVPN support. The link goes here: https://openvpn.net/security-advisory/action-needed-important-update-for-openvpn-access-server/?utm_source=sg&utm_medium=Email&utm_campaign=serverUpdate
-
I am extremely thankful for your information on this in previous posts, thanks for putting it out there! True... It's something I'm now curious to experiment with and see the impact first hand.
-
I recently had a corruption on one of my cache drives and spent ~12 hours recovering my system, mostly due to sifting through many old forum posts, BRTFS wikis, etc, and thought that it may be appreciated if I post the experience here for others that run into similar issues. In the end I didn't solve anything in an elegant way, just brute forced my way to getting my cache running again, read on for the epic adventure... Symptoms: Array would only start as a "read only file system" and no VMs or Docker services would start A reboot would cause a "Starting Array..." freeze, where the system and Web UI are responsive however no commands will execute (presumably this is because they are waiting for the array to finish starting). As part of this freeze, the main disks would come up and would be mounted, however the cache disks would show "Mounting..." as their status, this seemed indefinite (left for hours with no change) so I started my journey find a solution. Confirming The Issue: First I checked the system logs and noticed that there was a repeated report of the following. BTRFS critical (device sdf1): corrupt leaf: root=5 block=521301164032 slot=89, unexpected item end, have 11534 expect 11566 My cache is made up of 6 Samsung 850 Evo SSDs, one of which was sdf1. Bummer. Fixing Things: My first port of call was of course the UnRaid forums! There were a few posts on issues with BTRFS and the un-reliability of the file system, however nobody seemed to have had a cache drive corruption before with a clear resolution (at least that I could find). I was able to find a few posts (linked below) that gave good information on BTRFS recovery, since the cache is effectively just another pool of drives I was able to piece together a plan of attack. 1. Attempt data recovery and backup The first step when messing with file systems is generally to try and get a backup, or to already have one! In my case I do nightly backups so am not too worried about data loss, however some files had definitely changed within the last day (since the last run of the mover) and I would like to keep those changes if at all possible. I first rebooted my server into safe mode, this prevents the array from trying to mount when booted and kicks me out of the "Starting Array..." freeze loop. From there I can SSH into the server and attempt to mount the effected pool to a folder and copy the data off to a safe place (the main array). This is suggested in a fantastic post that @johnnie.black made (linked below) walking through BTRFS recovery. (I make two new directories to mount to as I wanted to avoid the default UnRaid locations just incase of issues) mkdir -p /media/cache mkdir -p /media/array mount -o recovery,ro /dev/sdf1 /media/cache The final command returned an error! mount: wrong fs type, bad option, bad superblock on /dev/sdf1, missing codepage or helper program, or other error. In checking dmesg the following was printed out: [ 3204.972308] BTRFS error (device sdf1): failed to read chunk tree: -2 No dice, the file system is screwed too much to launch the pool (since when you attempt to mount one BTRFS drive, it attempts to mount the whole pool) even in recovery and read-only mode. The final suggestion is to use "degraded" mode, this will kick the pool into action but you won't be able to interact with any affected files. mount -o degraded,recovery,ro /dev/sdf1 /media/cache Woohoo! Mount is successful, next steps are to mount up the main array and copy of the files using Midnight Commander. Note that when mounting any of the disks in my main array, the whole thing is mounted up, /dev/sdb1 is part of the main array (not cache). mount /dev/sdb1 /media/array mkdir -p /media/array/cache_backup mc umount /media/cache During the copying process, there were several files that reported as being incomplete or inaccessible, these I assume are contained on the failed disk. I was surprised however at how many were recoverable/copyable, I only ran into three or four that encountered issues! I was monitoring dmesg in another terminal window and each time a file issue was encountered the same issue I first saw in the UnRaid system log popped up again and again. [ 4225.676432] BTRFS critical (device sdf1): corrupt leaf: root=5 block=1704352235520 slot=89, unexpected item end, have 11534 expect 11566 I unmount the cache at the end to perform the following attempted repair. 2. Attempt drive repair I was hoping that I would be able to run some of the BTRFS recovery tools and everything would be fine and dandy, that wasn't the case but here's what I tried regardless. First off I wanted to see if I could fix the error that was reported in dmesg about the chunk tree failing to be read. I found the wiki page for btrfs rescue which has a feature called "chunk-recover" which can be executed as follows. btrfs rescue chunk-recover -v /dev/sdf1 This unfortunately completed and told me that there were over 400 unrecoverable chunks, which was almost half the chunks on the drive! I tried the next suggestion from the different sources that I have found which was a drive restore. btrfs restore -v /dev/sdf1 /media/cache This failed to do anything, it would immediately report that the disk was missing and then loop an insane number of times "trying another mirror" for each file it was trying to recover. I gave up after trying a number of files with the same result. Lastly I tried the check recover command, this is not a read-only command, it will change data on the disk if it can to try and recover the disk so beware! I did have a little confusion understanding what to do here as the source post I found the command on mentioned using "cache1" instead of /dev/sdX and that doesn't exist... btrfs check --repair /dev/sdf1 This resulted in the same thing over and over again in my terminal, I waited hours to no avail. It seems to just be trying to repair the same thing over and over again and failing to do so. corrupt extent record: key [500476772352,168,4096] incorrect offsets 11566 11534 There was a bunch of lovely output in dmesg after this. [17786.874635] BTRFS info (device sdf1): allowing degraded mounts [17786.874638] BTRFS warning (device sdf1): 'recovery' is deprecated, use 'usebackuproot' instead [17786.874638] BTRFS info (device sdf1): trying to use backup root at mount time [17786.874639] BTRFS info (device sdf1): disk space caching is enabled [17786.874639] BTRFS info (device sdf1): has skinny extents [17786.876308] BTRFS warning (device sdf1): devid 1 uuid 1d3d7b36-a05a-44b3-8a5a-eef55524e113 is missing [17786.879609] BTRFS info (device sdf1): bdev /dev/sdk1 errs: wr 3, rd 0, flush 1, corrupt 0, gen 0 [17786.879611] BTRFS info (device sdf1): bdev /dev/sdd1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 [17786.879613] BTRFS info (device sdf1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 [17786.986056] BTRFS info (device sdf1): enabling ssd optimizations [17787.085607] BTRFS warning (device sdf1): block group 1704116355072 has wrong amount of free space [17787.085608] BTRFS warning (device sdf1): failed to load free space cache for block group 1704116355072, rebuilding it now [17787.997905] BTRFS critical (device sdf1): corrupt leaf: root=5 block=1704352235520 slot=89, unexpected item end, have 11534 expect 11566 [17788.023561] BTRFS critical (device sdf1): corrupt leaf: root=5 block=1704352235520 slot=89, unexpected item end, have 11534 expect 11566 [17788.023566] BTRFS: error (device sdf1) in btrfs_drop_snapshot:9250: errno=-5 IO failure [17788.023568] BTRFS: error (device sdf1) in merge_reloc_roots:2466: errno=-5 IO failure [17788.023571] BUG: unable to handle kernel NULL pointer dereference at 0000000000000000 Not really knowing what to do with this information I decided to just move on, I hope someone else can give me more insight into what actually happened and maybe some other things to try for future folks in my position! I then found an article in the UnRaid Wiki that described attempting to recover different types of drives. It suggests doing a BTRFS Scrub, however I was not able to get this to work. Scrub requires that the drives are mounted at the time you run the command and as the only way I could mound my drives was in read only mode none of the attempted repairs could actually be done! The following is what I did to find this out, the "ro" in the mount means read-only, without this however my terminal would hang and count not mount the disks, nothing was printed in dmesg either which is worrying! If I opened a new terminal I could still do stuff, but trying to interact with the disks or mount would not work. mount -o degraded,recovery,ro /dev/sdf1 /media/cache btrfs scrub -B /media/cache The only way I was able to do anything after attempting to mount the disks without "ro" was to reboot the system... 3. Admit defeat and reformat the cache drives The final step in the UnRaid wiki page on attempting to recover is to reformat the disk as ReiserFS, boot the array, format the disk, then format it again as BTRFS. Funny thing is that there are no guides on how to do this since it's a pretty obscure part of the wiki that I am guessing not many people make their way to, so I found the man page for "mkreiserfs" and went ahead. mkreiserfs /dev/sdf1 This was successful and I ended up doing this for all the disks that were in my cache just to ensure no corruption snuck through. Once complete I was able to start my array with all cache drives assigned to the cache, and format the unmountable drives to a new BTRFS partition. The cache was now back online! 5. Restore backed-up files This last but crucial step had no documentation or examples anywhere that I could find but is very simple in essence. The cache was now online at "/mnt/cache" and my backup files were located in "/mnt/disk2/cache_backup", another trip to Midnight Commander and the cache was copying over (ongoing as I post this). Final thoughts: BTRFS is a nightmare to recover data from, documentation is spotty, and the tools aren't foolproof Caching is such a core feature of UnRaid that so many people use, it should be easier to work with My VMs and Docker images were almost lost, they are set to "Prefer" the cache drive as a storage location by default, to my horror I found out during this escapade that they were NOT moved to the main array as is done with other files by the mover each night, and that files created on the main array due to lack of space on the cache will be explicitly moved onto the cache. Personally I will be changing this setting to "yes" (which means the mover will put them into the array each night), I think this should be the default since the cache seems so dangerous. I don't actually know what was going on, that lack of knowledge and uncertainty has left me suspicious of using the cache and i'll be putting extra effort into ensuring the smooth operation of the server from now on. Source Material: BTRFS Wiki - BTRFS Rescue UnRaid Forum - Unmountable Cache Drive - lost dockers - 6.5.3 UnRaid Forum - Cannot start array following Cache Balance Failure UnRaid Forum - johnnie.black's post on FAQ for unRAID v6 UnRaid Wiki - Check Disk Filesystems Linux Man Pages - mkreiserfs

