

PsyVision
-
Posts
93 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by PsyVision
-
-
Yo, thanks for this - I gave it a try this evening and I get the following in my logs:
2022-02-02 21:43:15,256 INFO supervisord started with pid 1 2022-02-02 21:43:16,258 INFO spawned: 'x11' with pid 15 2022-02-02 21:43:16,260 INFO spawned: 'easy-novnc' with pid 16 2022-02-02 21:43:16,261 INFO spawned: 'prusaslicer' with pid 17 2022-02-02 21:43:16,263 INFO spawned: 'openbox' with pid 18 2022-02-02 21:43:17,796 INFO success: x11 entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-02-02 21:43:17,796 INFO success: easy-novnc entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-02-02 21:43:17,796 INFO success: prusaslicer entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-02-02 21:43:17,796 INFO success: openbox entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-02-02 21:43:18,990 INFO exited: prusaslicer (terminated by SIGSEGV; not expected) 2022-02-02 21:43:19,992 INFO spawned: 'prusaslicer' with pid 29 2022-02-02 21:43:20,025 INFO exited: prusaslicer (terminated by SIGSEGV; not expected) 2022-02-02 21:43:21,401 INFO spawned: 'prusaslicer' with pid 41 2022-02-02 21:43:21,432 INFO exited: prusaslicer (terminated by SIGFPE; not expected) 2022-02-02 21:43:23,436 INFO spawned: 'prusaslicer' with pid 46 2022-02-02 21:43:23,466 INFO exited: prusaslicer (terminated by SIGSEGV; not expected) 2022-02-02 21:43:26,471 INFO spawned: 'prusaslicer' with pid 51 2022-02-02 21:43:26,518 INFO exited: prusaslicer (terminated by SIGFPE; not expected) 2022-02-02 21:43:26,471 INFO spawned: 'prusaslicer' with pid 51 2022-02-02 21:43:26,518 INFO exited: prusaslicer (terminated by SIGFPE; not expected) 2022-02-02 21:43:27,519 INFO gave up: prusaslicer entered FATAL state, too many start retries too quicklyWhen navigating to the IP:8080 I get the connect dialog then a blank/black VNC screen. Any ideas?
-
51 minutes ago, bonienl said:
There is NO such entry. The allowed IPs for the peer are automatically generated based on the interfaces/networks present on the server.
Three possible approaches:
1. Configure an IP address + subnet on the VLAN interface for the server. This will add an entry to the peer config
2. Use "Remote tunneled access". This sets a default route (=all subnets) on the peer
3. Manually add the entry at the peer side. What you are doing right now
Thanks @bonienl!
-
Thanks for this guide, it's working well for me. I can access my containers on my separate VLAN (192.168.5.0/24) when connected via WireGuard. My unRAID server is 192.168.1.50.
In my client configuration I get:
AllowedIPs=10.253.0.1/32, 192.168.1.0/24
For everything to work on the client I need to explicitly add 192.168.5.0/24 to the list (e.g when setting up my phone, I had to do this on the phone itself).
What is a valid config entry in unRAID to have other subnets populate? I tried adding 192.168.5.0 and 192.168.5.0/24 to the 'Peer allowed IPs' setting but that seems to make no difference.
-
Aha cheers! This was run through the web UI. I'll re-do it from the cli
-
Thank you @remotevisitor
I've followed the instructions here - https://lime-technology.com/wiki/Check_Disk_Filesystems
I'm not familiar with the output but it appears to me that there aren't any issues, you may say otherwise... This was run with -nv options.
Disk 1: Phase 1 - find and verify superblock... - block cache size set to 749704 entries Phase 2 - using internal log - zero log... zero_log: head block 1754761 tail block 1754761 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 0 - agno = 2 - agno = 3 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Thu Feb 22 18:45:36 2018 Phase Start End Duration Phase 1: 02/22 18:45:31 02/22 18:45:31 Phase 2: 02/22 18:45:31 02/22 18:45:32 1 second Phase 3: 02/22 18:45:32 02/22 18:45:34 2 seconds Phase 4: 02/22 18:45:34 02/22 18:45:34 Phase 5: Skipped Phase 6: 02/22 18:45:34 02/22 18:45:36 2 seconds Phase 7: 02/22 18:45:36 02/22 18:45:36 Total run time: 5 seconds Disk 3: Phase 1 - find and verify superblock... - block cache size set to 742224 entries Phase 2 - using internal log - zero log... zero_log: head block 820249 tail block 820249 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 - agno = 3 - agno = 4 - agno = 5 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Thu Feb 22 18:47:07 2018 Phase Start End Duration Phase 1: 02/22 18:46:46 02/22 18:46:46 Phase 2: 02/22 18:46:46 02/22 18:46:47 1 second Phase 3: 02/22 18:46:47 02/22 18:47:02 15 seconds Phase 4: 02/22 18:47:02 02/22 18:47:02 Phase 5: Skipped Phase 6: 02/22 18:47:02 02/22 18:47:07 5 seconds Phase 7: 02/22 18:47:07 02/22 18:47:07 Total run time: 21 seconds Disk 4: Phase 1 - find and verify superblock... - block cache size set to 749664 entries Phase 2 - using internal log - zero log... zero_log: head block 696667 tail block 696667 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 3 - agno = 1 - agno = 4 - agno = 5 - agno = 6 - agno = 7 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Thu Feb 22 18:48:21 2018 Phase Start End Duration Phase 1: 02/22 18:47:52 02/22 18:47:52 Phase 2: 02/22 18:47:52 02/22 18:47:53 1 second Phase 3: 02/22 18:47:53 02/22 18:48:07 14 seconds Phase 4: 02/22 18:48:07 02/22 18:48:07 Phase 5: Skipped Phase 6: 02/22 18:48:07 02/22 18:48:21 14 seconds Phase 7: 02/22 18:48:21 02/22 18:48:21 Total run time: 29 seconds Disk 6: Phase 1 - find and verify superblock... - block cache size set to 749680 entries Phase 2 - using internal log - zero log... zero_log: head block 1056269 tail block 1056269 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 0 - agno = 3 - agno = 2 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Thu Feb 22 18:49:17 2018 Phase Start End Duration Phase 1: 02/22 18:48:48 02/22 18:48:48 Phase 2: 02/22 18:48:48 02/22 18:48:49 1 second Phase 3: 02/22 18:48:49 02/22 18:49:04 15 seconds Phase 4: 02/22 18:49:04 02/22 18:49:04 Phase 5: Skipped Phase 6: 02/22 18:49:04 02/22 18:49:17 13 seconds Phase 7: 02/22 18:49:17 02/22 18:49:17 Total run time: 29 seconds Cache: Phase 1 - find and verify superblock... - block cache size set to 757096 entries Phase 2 - using internal log - zero log... zero_log: head block 146793 tail block 146793 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Thu Feb 22 18:50:24 2018 Phase Start End Duration Phase 1: 02/22 18:49:47 02/22 18:49:47 Phase 2: 02/22 18:49:47 02/22 18:49:48 1 second Phase 3: 02/22 18:49:48 02/22 18:50:12 24 seconds Phase 4: 02/22 18:50:12 02/22 18:50:12 Phase 5: Skipped Phase 6: 02/22 18:50:12 02/22 18:50:24 12 seconds Phase 7: 02/22 18:50:24 02/22 18:50:24 Total run time: 37 seconds -
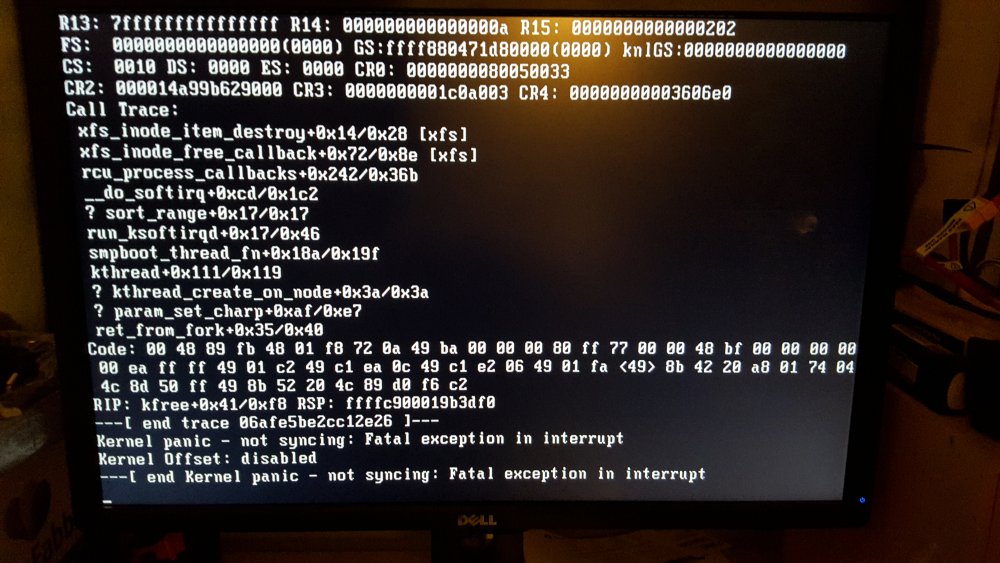
Hello,
I'm using unRAID 6.4.1 and every few weeks I discover that my server has crashed with a kernel panic. I've not managed to go about getting hold of a syslog or any proper diagnosis. I've attached a photo of the screen once the panic has occurred.
I have 3 VMs setup but these haven't been running for ages, were off at the time and are not set to autostart.
I'm running 2 Docker containers - UniFi and UniFi Video.
I've attached my diagnostics file for whatever use they may be.
Any help would be greatly appreciated.
Thank you,
Rich
-
There is one on Google for ToughSwitch. You might be able to use that as a framework for making one that works with UniFi. After all, the settings are just stored in a (I think) JSON file.
-
I've created a container for the UniFi beta but it isn't in a repo that you can get in unRAID so takes a bit of manual work to get up and running. If you know what you're doing then you can grab it from:
https://hub.docker.com/r/psyvision/docker-unifi/
I will try and keep it up to date but wont support it at all, especially not here as this is LS.io's spot. If they add the beta to their repo then I will remove it altogether as I like their shiz, I will also drop it when it hits RTM.
-
I see they have just released UniFi Video 3.2
 ;)
;)nblain1 - I had to run it from my cache drive or else mongodb wouldn't work, some sort of file read/write speed check it does at startup fails otherwise.
-
I tried a re-build before posting and it failed after a couple of hours, it should take ~9 to do a full rebuild apparently.
Cache and disk5 appear to be online, just that disk5 gets marked as a red.
I have enough disk space to move data off both drives, would it be okay to move the data to other drives and then replace 2 and 5 as though they were new drives?
-
THank you Johnnie.
How is best to do this? If I put a new disk2 in then it tells me it's the wrong one. I see I should mark it as empty and then shutdown, put the new one in and then assign it to the slot. However, I am told that i have either too many or the wrong disks assigned. Unfortunately disk5 is still showing red-balled/cross so I'm not sure it will let me build it.
-
Okay I powered off the server and have re-connected all of the power connectors. I may have had an extra drive on one of the power leads that should have been on the other (3 and 5 rather than 4 and 4). I have powered on and then done nothing, logs attached.
WD-WMAV50355779 (sdh) is my cache drive
WD-WCAU45077221 (disk 2, sdc) is an old 1TB drive that potentially could be failing? I would be happy to replace this if needs be (of course).
-
Yea disk 5 was replaced. That disk and another are on the same onboard motherboard controller, with only those two disks.
I will check cables and cycle later and then post back results with more information on things you've asked.
Thank you!
-
Hi All,
A few weeks ago one of my drives started failing on me. I switched it out and replaced it with a new drive. On rebuilding the drive it showed there were 288 errors. I thought there could be an issue with the SATA cable so I also replaced that, I then unassigned the drive and re-assigned it to rebuild it from parity. The drive rebuilt but showing 288 errors again. I've repeated this process again, changing the SATA cable (as some of mine are old and possibly broken) and again, 288 errors.
Below is a sample of my syslog and I have attached the diagnostics download.
Feb 11 21:11:39 nas kernel: ata7.00: exception Emask 0x0 SAct 0x2000 SErr 0x0 action 0x6 frozen Feb 11 21:11:39 nas kernel: ata7.00: failed command: WRITE FPDMA QUEUED Feb 11 21:11:39 nas kernel: ata7: hard resetting link Feb 11 21:11:49 nas kernel: ata7: COMRESET failed (errno=-16) Feb 11 21:11:49 nas kernel: ata7: hard resetting link Feb 11 21:11:59 nas kernel: ata7: COMRESET failed (errno=-16) Feb 11 21:11:59 nas kernel: ata7: hard resetting link Feb 11 21:12:10 nas kernel: ata8.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen Feb 11 21:12:10 nas kernel: ata8.00: failed command: WRITE DMA EXT Feb 11 21:12:10 nas kernel: ata8: hard resetting link Feb 11 21:12:16 nas kernel: ata8.00: failed to IDENTIFY (I/O error, err_mask=0x4) Feb 11 21:12:16 nas kernel: ata8.00: revalidation failed (errno=-5) Feb 11 21:12:16 nas kernel: ata8: hard resetting link Feb 11 21:12:27 nas kernel: ata8.00: failed to IDENTIFY (I/O error, err_mask=0x4) Feb 11 21:12:27 nas kernel: ata8.00: revalidation failed (errno=-5) Feb 11 21:12:27 nas kernel: ata8: hard resetting link Feb 11 21:12:34 nas kernel: ata7: COMRESET failed (errno=-16) Feb 11 21:12:34 nas kernel: ata7: hard resetting link Feb 11 21:12:39 nas kernel: ata7: COMRESET failed (errno=-16) Feb 11 21:12:39 nas kernel: ata7: reset failed, giving up Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 1465144063 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 977254148 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 977254151 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 0 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 977254181 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 1465328951 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 1465329367 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 0 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 37607 Feb 11 21:12:39 nas kernel: blk_update_request: I/O error, dev sdh, sector 978674575 Feb 11 21:12:39 nas kernel: XFS (sdh1): metadata I/O error: block 0x575452c0 ("xfs_buf_iodone_callbacks") error 5 numblks 32 Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 183166111, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 183166112, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 183166163, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 183166164, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 122334314, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 122334315, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 122334344, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 122334345, lost async page write Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 124078201, lost async page write Feb 11 21:12:39 nas kernel: XFS (sdh1): metadata I/O error: block 0x3a3fb6c5 ("xlog_iodone") error 5 numblks 64 Feb 11 21:12:39 nas kernel: Buffer I/O error on dev sdh1, logical block 122334346, lost async page write Feb 11 21:12:39 nas kernel: XFS (sdh1): Log I/O Error Detected. Shutting down filesystem Feb 11 21:12:39 nas kernel: XFS (sdh1): metadata I/O error: block 0x3a3fb6c8 ("xlog_iodone") error 5 numblks 64 Feb 11 21:12:39 nas kernel: XFS (sdh1): metadata I/O error: block 0x3a3fb6e6 ("xlog_iodone") error 5 numblks 64 Feb 11 21:12:39 nas kernel: XFS (sdh1): xfs_log_force: error -5 returned. Feb 11 21:12:59 nas kernel: ata8.00: failed to IDENTIFY (I/O error, err_mask=0x4) Feb 11 21:12:59 nas kernel: ata8.00: revalidation failed (errno=-5) Feb 11 21:12:59 nas kernel: ata8: hard resetting link Feb 11 21:13:00 nas kernel: blk_update_request: I/O error, dev sdi, sector 251287064 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287000 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287008 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287016 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287024 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287032 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287040 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287048 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287056 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287064 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287072 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287080 Feb 11 21:13:00 nas kernel: md: disk5 write error, sector=251287088I'm not sure how to resolve this? Is it possible that I've corrupted my parity such that when rebuilding the data drive it rebuilds incorrectly?
-
I can't post logs at the moment as I'm in bed now but I did some more digging albeit in the NZBGet container...
So I can ping Google.com and I can ping nzbget.org (i think it was) from inside the container (ssh in) my etc resolv file has Google nameservers listed (from my host).
If I try and execute the curl command that fetches the nzb JSON file it just sits there doing nothing. It seems that apt-get update is basically doing the same in this and all other containers too.
Googling for info shows some people having issues with iptables and routing, I don't have any weird config setup though. I've got VMs turned off but do have bridging enabled - this is no change from recent, though I have recently upgraded hardware, but this shouldn't cause this problem.
A reboot hasn't fixed the issue either.
-
Any ideas on this... my CouchPotato (and NZB from you guys) have both become inaccessible over the last few days. I've deleted both containers and images, and re-created and they still wont open up (connection refused error). I've tried deleting all couch files apart from config.ini and it still wont load.
-
Hi Gary,
I hadn't seen your message until now when I started to look back at this. I logged onto my server and it was doing a parity sync at 3.8MB/s which is painfully slow. When booting the server it spends 10 minutes looking for a disk in each of the 4 slots and then eventually boots. Holding (and ramming) Ctrl + A doesn't allow me to get into the menu.
I suspect there must be some sort of compatibility issue as this card has worked fine previously. I'm not too fussed on fixing it as I have ordered a SATA3 card to replace it (as this is SATA2). If someone else is searching and has an issue then try what Gary says

-
I read about disabling it last night but couldnt try it for a couple of reasons. I rebooted this morning and whacked Ctrl+A a whole load and got nothing, tried to hold it for the boot process and still got nothing - had to leave for work but will try again tonight!
Thanks!
-
Hi All,
Not sure this is strictly the best place to put this but it's a hardware issue alone (doesn't involve unRAID).
My unRAID server has been working fine and I decided to upgrade it from an AMD Semperon based system. I've installed the following:
Intel i3 6100T
Gigabyte GA-Z170-D3H Micro ATX
Corsair Vengeance 4x4GB RAM
This setup will boot fine on it's own.
However, if I put my Adaptec 1430sa card (with two hard drives attached) into either the PCIeX16 or X4 slot it will boot and the card's BIOS will sit there looking for the drives forever and the system never boots properly.
I used the Adaptec card with my old setup okay (i.e. had adjusted the BIOS on it to be in normal SATA mode not RAID).
Any ideas?
Thanks,
Rich
-
I had the same issue as dirtysanchez, once I fixed the port conflict issue I updated unRAID to 6.1.4 and when going back to the container this evening it was down but apparently running. Restarting it made it hang at the refreshing packages stage. Re-adding the container now to see if it fixes it. Edit: Fixed it
As an aside - is there any chance of you guys doing one for the video controller app please? I've just ordered one of their cameras
-
Got it!
I knew two couldn't use the same port but couldn't work out what was using it given it was stopped.
All up and running with your containers now
Thanks!
-
I rebooted with both containers off and then turned just this one on. Is there some sort of port reserving going on within docker?
-
Stopped the old container, rebooted and then re-created your container and have the same address in use.
Error log - http://pastebin.com/KPRPKTSK
hmmmm
-
I had a look at the logs a bit better and I'm wrong on the permissions.
So I have been using pducharme/unifi:latest. I stopped this running.
I then created a new container of linuxserver/unifi:latest (all using the unRAID UI) and pointed at a new config folder on my cache drive. So basically as if I've never used unifi before.
I have additional errors in my log that relate to addresses in use. I have checked and there is no port conflicts with other containers (on the host side). I can't think that the old container is causing an issue as it is stopped - I could be wrong though?

[Support] Prusaslicer noVNC
in Docker Containers
Posted
Thank you very much, that seems to have done the trick!