urbancore
Members
-
Joined
-
Last visited
-
I wanted to follow up on this. The disks were absolutely fine and the HBA being too hot was the issue. My solution in this case was to remove the heat sink on the HBA, re-paste the sink with new thermal compound and then re-attach the heat sink using 25mm Nylon bolts and nuts with a 40mm Noctua fan going on it. This has the card nice and cool and I was able to re-add the same disks back to the array with no issues aside from a 3 day rebuild time. So yes, heat is an issue on these HBAs designed for high-speed air movement in a rack mounted system when not getting the air it's expecting. Cool those cards people.
-
Thank you! I might very well have missed that. I will get a small 40mm fan at once to put on that LSI Card. I was low-key worried about this before but we got a few parity checks in and it didn't seem to be an issue so I suppose I forgot about it. Thanks! Now once I shut down the server to attach the fan and start back up is there anything I need to do? How do I re-enable those drives? And finish up the parity check I presume?
-
Hello all, Currently I have a parity check (which I run every 90 days) on an array of 32 drives which paused about halfway or so through and two of my newly added drives which have been added in the last six months have disabled. Both of those drives are empty currently and the SMART check on them looks okay. They are both connected via a SAS backplane and are both in my main chassis. I have six more drives in DAS which are also empty and not having issues. I have replacement drives available if that is what must be done, I just wish to make sure I do this correctly. As I stated there is no data on either of the disabled drives at this time. I am posting diagnostics below, the server has not been rebooted so they should be helpful. The parity check was happening while I was away at work for the last two days. I verified with my wife there are no power fluctuations or hits during that time and both the NAS and DAS have their own UPS in good health. Any guidance would be welcome? Thanks in advance you all. I am sure you get this a lot but this is my first real tango with a failed disk. tower-diagnostics-20240208-0138.zip
-
Marking this solved. So for those who are reading this with possible similar issues here was what the problem was. High I/O wait as shown here in glances caused the GUI to spit out a higher cpu use then htop or top showed. The cause of this was an external plex box I built for using quicksync hardware transcoding which was attached to the unRaid box via NFS which was doing library scans and thumbnail generation sucking up a ton of bandwidth (like 6/800 mbps) and that was causing the I/O delays. So apparently the GUI reads I/O wait as CPU use in some cases. I found this using Glances and Netdata dockers.
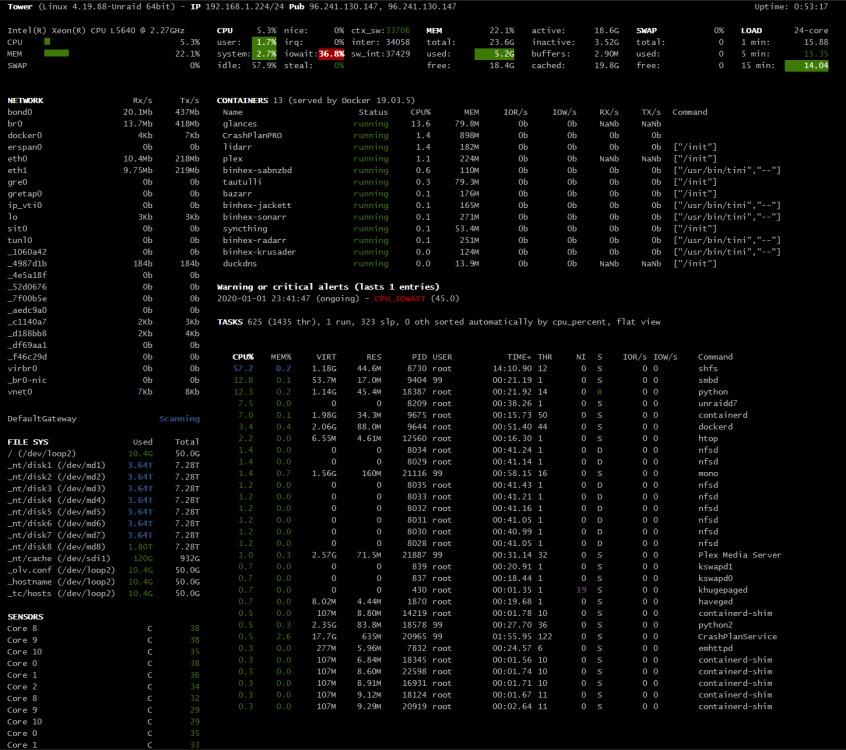
-
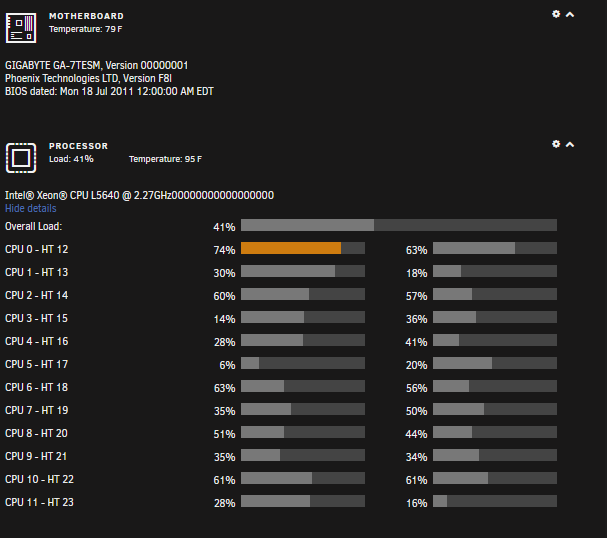
HTOP is wildly different then the web gui which I am adding here. Is this a web gui bug?
-
Allow me to try and explain this. A few days ago I upgraded from 6.7 to 6.8 and this problem has developed since then. I have tried the following solutions, I've shut down all VMs and Dockers, I've turned off the one external VM which has NFS mount access to some of my shares and I've even rebooted and the same command comes back persistently using a good quarter of my 24 core system. /usr/local/sbin/shfs /mnt/user -disks 511 2048000000 -o noatime,allow_other -o remember=330 No disk check is being done. No mover process is running. Last parity check came back clean. I know this process is not unusual at all and a number of them run at all times on the system. But *one* of them is constantly sucking up a good quarter of all my CPU for reasons I can not seem to isolate. I've posted a screenshot and a dump of my current diagnostics, any help would be welcome in tracking down my rogue process or plugin that is doing this? Thanks! - Urbancore. tower-diagnostics-20200101-2301.zip