




hwilker
Members
-
Joined
-
Last visited
-
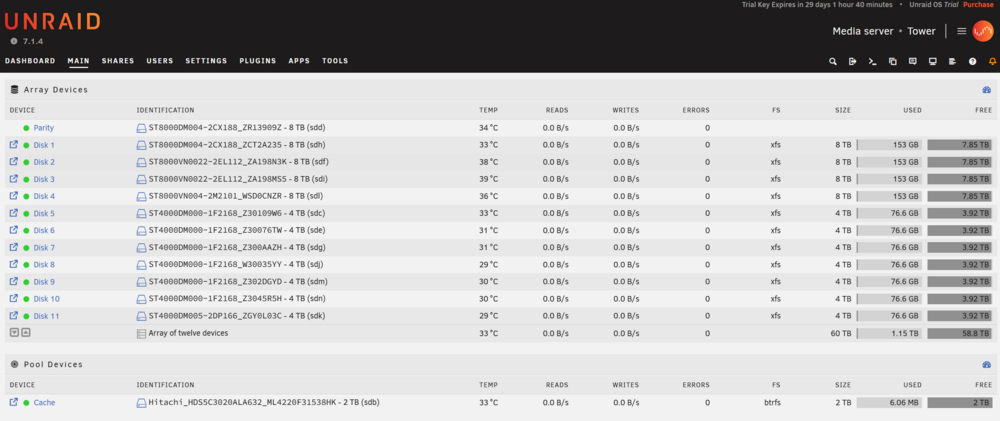
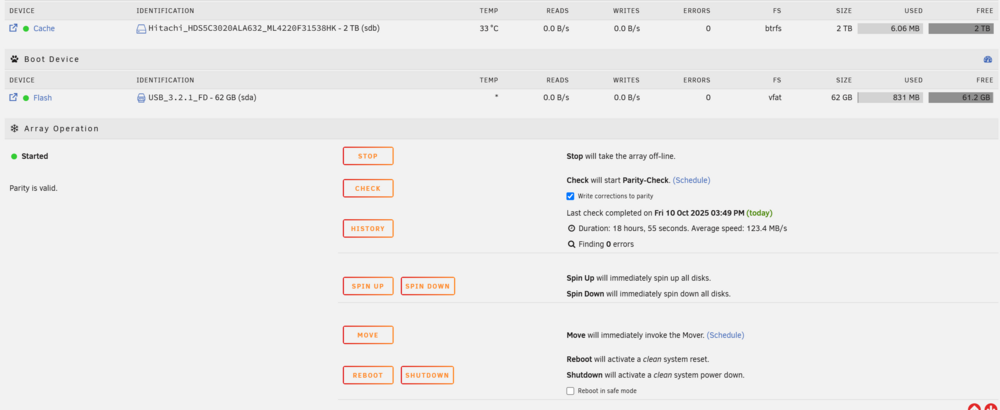
Norco 4224 chassis with all slots wired. Functioning 60TB array Plug and play. Ready to use No shipping. Local pickup only. Bay area Oakland CA Payment: Venmo, cash Price: $850 OBO Components - 2 IBM M1115 LSI 9223-8i HBA card 'newish' - Purchased 9/25 from ebay (probably server pulls) - Intel Celeron G1610 CPU (old but works fine) - ASRock Z77 Extreme4 (old but works fine) - Corsair HX750X (overkill but good if you plan to fill all bays) - 16 slots connected through HBA cards - 8 slots connected via motherboard SATA ports. Current Array: - 5 × 8 TB data drives (XFS) - 6 × 4 TB data drives (XFS) - 1 × 8 TB parity drive - 1 × 2 TB cache drive (BTRFS) All disks freshly formatted, parity rebuilt, array shows clean. Also Includes - 21 2TB drives - not currently in array - Handy for filling the rest of the chassis or for backups/spares Condition - System boots straight into Unraid web UI - Functioning Trial Key included for ease in getting up and running - All disks passed SMART short tests before format - Parity verified during rebuild - Case, backplane, and cooling all functional

-
OK. Thank you.
-
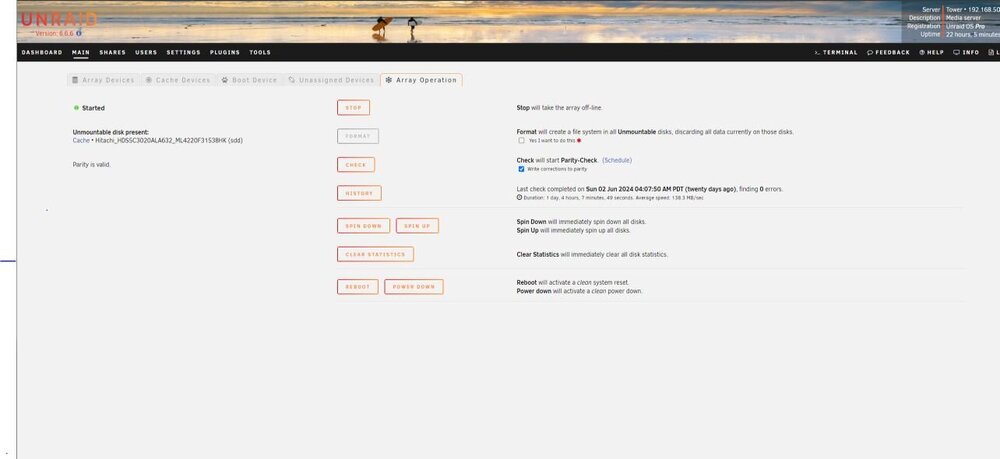
Thanks. I think this is what you're referring to. See attached. I just want to confirm this is what you mean before I start. I see it lists my cache drive as the only unmounted drive, but it's placement on the Main screen gives me some pause. If it's not too much bother please confirm that this is what you meant. Thank you
-
I have been using unraid for a long time now, easily a decade. I use it in a very simple manner. A pool of disks, with a cache drive and a parity drive (now two parity drives, but who's counting). I use it solely as a media server. I have no VM's cache pools or other features enabled. My unraid version is 6.6.6, and I'm using the reiserfs file system. Until yesterday, I've been using a 640GB ancient hard drive as a cache drive. I noticed it was getting hot and so I decided to replace it with a 2TB hard drive I had laying around. I stopped the array, inserted the larger drive in the same physical location, and restarted the array. I then precleared the new disk. When completed, I stopped the array, allocated the 'new' disk as the cache drive, and restarted the array. It seemed to mount just fine but it lists the drive as 'Unmountable: No file system'. It must be looking for a formatted disk, but there is no option I can see to format it. I've replaced plenty of hard drives over the years without problems. Preclear to new drive. Stop the array. Either add the disk to an unused slot, if extending, or select it as the new drive in that slot if replacing. Then restart and let the array rebuild if you are replacing a disk. So, my hopefully simple question is, how do I get unraid to recognize or format the new drive that I've allocated as a cache drive? Any help would be appreciated.



