




Skipdog
Members
-
Joined
-
Last visited
Everything posted by Skipdog
-
@Kboogie Thanks for the detailed data point. Looks identical to my issue. I did look at another post where another user replaced his card with a 94xx series but they are expensive and i quickly ditched that idea. Hope they are able to fix the regression. 7.3.0 works great.
-
@paolobosco Good to know my scenario isn't a result of some strange configuration on my side. I can validate that going to 16.00.12.00 does not fix this problem so you can skip that!! @JorgeB I can mark your response to wait for a potential fix via Kernel update as the solution.
-
@JorgeB Thanks for the input. That being the case it must be something different with the 9305-16e (my card) vs the internal variant -- SATA timings, expander negotiation, etc. I'll stay on the working version for now!
-
@JorgeB What is the best way forward-- is there an avenue to log the bug report (regression) with Slackware, etc?
-
@rerror Which UNRAID version are you running?
-
OK some new data- Upgraded to 16.00.12.00 and rebooted into the same 7.3.0 version to make sure everything worked good (it did) Upgraded to 7.3.1 and rebooted and confirmed the timeout/resets are still happening (they are) Tried to add pci_aspm=off to boot statement -- did not fix. The AI wants a couple more tests on the boot statement like: /bzimage initrd=/bzroot pcie_aspm=off pci=noaer and nomodeset pci=noaer pcie_aspm=off and... pcie_port_pm=off pci=noaer At this point I think i will revert it back to 7.3.0 and wait to see what can be done. Otherwise will need to change out the card to advance in UNRAID versions. Skip
-
@JorgeB Before taking the plunge - the AI assistant is recommending trying to append "pcie_aspm=off" to the boot statement - do you think this is worth a try in lieu of flashing first?
-
@jynxsee I wasn't following the answer "Same firmware" -- same firmware as what? Are you running 16.00.11.00 or 16.00.12.00 ? @JorgeB I'm very hesitant to even try the firmware upgrade as it is the only card I have to drive the external enclosure and these cards have doubled in price now.. Definitely don't want to render my system unusable. I would love to find out if anyone else having this issue is already on 16.00.12...
-
@JorgeB I could be wrong but for the 9305-16e it appears it is maxed out stable at: IT_Nexus mode - fw: 16.00.11.00, nvdata: 10.00.91.xx: Channel_9305-16e_IT_Nexus.bin Abort Task Set - fw: 16.00.11.00, nvdata: 10.00.92.xx: Channel_9305-16e_ATS.bin I don't believe there is anything newer but definitely could be wrong. Skip
-
Just one more note- OpenAI analysis spit out: Diagnostics show repeated 30-second I/O timeouts resulting in task aborts and device resets on host0 (LSISAS3216 / SAS9305-16e running FW 16.00.11.00). No corresponding aborts are seen on host1 (LSISAS2308 running FW 20.00.07.00). Rolling back from Unraid 7.3.1 to 7.3.0 immediately resolves the issue. Controller remains operational and does not enter IOC fault state; failures appear to be command timeout related rather than HBA crashes. I'm wondering would BIOS/Firmware update be worth it ? My feeling is no it would not help. Skip
-
For me it looks like the bios/firmware is: LSISAS3216: FWVersion(16.00.11.00)
-
Perhaps 7.3.1 as Jorge mentioned might have a regression for LSI 3xxx cards? I had to revert to 7.3.0 to fix my install as well. Ref: https://forums.unraid.net/topic/199098-unraid-730-731-array-startperformance-related-issues/ Skip
-
@JorgeB Fair enough. I didn't dive into the diagnostic- could you tell if the problem was actually coming from the 3216 or the 2308? I can check firmwares but i was pretty sure these old cards did not have updates. Thanks, Skip
-
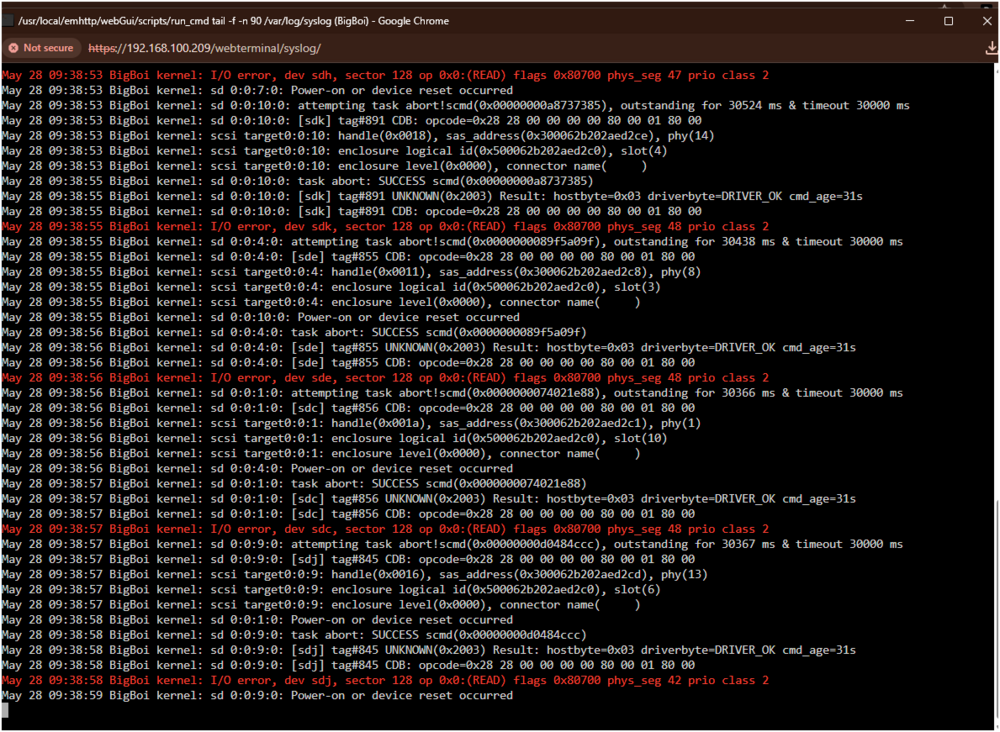
System: Supermicro CS836 chassis with a QNAP enclosure added via LSI SAS3216 Mobo: MSI Pro Z790-P WI-FI with 12700K Drives: 22 mostly WDC SATA in BTRFS Upgrade went smoothly. Rebooted and immediately noticed that UNRAID CLI was reporting the following repeatedly when tyring to scan the hard drives: May 28 09:21:55 BigBoi kernel: I/O error, dev sdh, sector 128 op 0x0:(READ) flags 0x80700 phys_seg 48 prio class 2 May 28 09:21:55 BigBoi kernel: sd 0:0:10:0: attempting task abort!scmd(0x00000000fcba39fa), outstanding for 30463 ms & timeout 30000 ms May 28 09:21:55 BigBoi kernel: sd 0:0:10:0: [sdk] tag#5615 CDB: opcode=0x28 28 00 00 00 00 80 00 01 80 00 May 28 09:21:55 BigBoi kernel: scsi target0:0:10: handle(0x0018), sas_address(0x300062b202aed2ce), phy(14) May 28 09:21:55 BigBoi kernel: scsi target0:0:10: enclosure logical id(0x500062b202aed2c0), slot(4) May 28 09:21:55 BigBoi kernel: scsi target0:0:10: enclosure level(0x0000), connector name( ) May 28 09:21:55 BigBoi kernel: sd 0:0:7:0: Power-on or device reset occurred This happened over and over -- eventually the server booted (30-40 mins) and then allowed me to login where it struggled for another 30 mins to start the array (It eventually did) I was able to grab snippets and diags prior to rolling back to 7.3.0. Roll back successful and everything is running perfect on 7.3.0. Happy to provide more information. Skip bigboi-diagnostics-20260528-0934.zip
-
I'm running 7.1.2 and running the binhex-plex docker as well. In the last week plex hasn't crashed and i noticed i've updated the docker a couple of times. Hopefully just a fluke. Did you review this thread for spin/up/down ? I let my drives sleep because a few of the drives in the center of my 3U Supermicro cause a lot of heat and the spin down helps my overall temps quite a bit. I've always done this and never have had a problem. Sometimes if someone tries to access media on the drives that are spun down it will take plex a bit to start to stream. As a side note the biggest performance i've gotten was installing a new MSI z790 board and then installing a gen4/5 NVME and making sure appdata was running from that. Skip
-
@andykai Are you running the latest 7.12 or 7.x? My Plex has been doing the same thing now every couple of days and it started with the most recent 7.1 release/patches. Plex appears to be up sometimes but when trying to stream media it doesn't play. Other times the server is actually down (alerted by Plex Dash or Tautulli. My disks have spun down for years so I don't think that is it. I need to find the location of the plex log file to see why it thinks it is crashing.
-
Thank you! Good to go! Skipdog
-
Balance completed! I see the space issue looks correct now. New diags attached here. I assume I can do something as you said to collapse the pool to 1? Skip unraid-diagnostics-20250123-1524.zip
-
Hi JorgeB, Yes for now I want to have a pool with a single NVME drive with the original size of 2TB. Skipdog

-
JorgeB, Thank you so much that got my cache drive back up and working. I'll definitely perform a backup now of appdata. It looks like when I assigned the single drive and it mounted it returned the pool devices to original 2 slot. Should I invoke mover and get it all back on the array and then wipe the cache and then user mover to reduce cache drive to 1? Also the 2TB is showing half the capacity. New Diags uploaded. Skipdog unraid-diagnostics-20250122-1520.zip

-
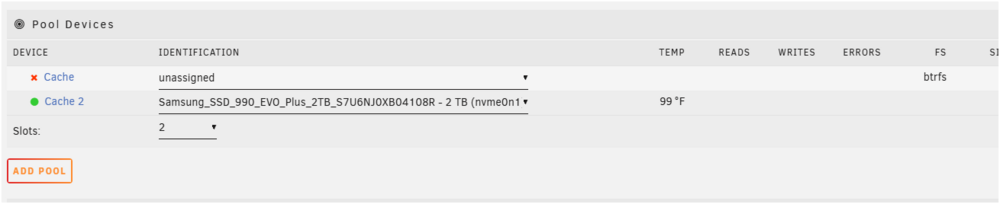
Summary: I had replaced the guts of the system with a new motherboard/cpu and added a shiny new 2TB NVME drive. I added another slot to Cache Pool and added the NVME to slot 2. Everything synced and was happy. I had decided to try to remove the old cache pool drive (2.5 SSD) and was able to remove it. Of course now I was in a weird state of a half working RAID1 pool. I was doing more maintenance on the server and rebooted a couple times. After the last reboot the array fails to start with "Wrong Pool State - cache too many wrong or missing devices" Cache2 correctly identifies the NVME 2TB drive and its green color. Cache1 is unassigned. I've tried removing cache2 and then I've tried to mount it in order to back up the data and that doesn't work. At this point I know how to fix it destructively, but i'd like to get appdata off the cache drive. Is there anyway to recover the data? I've got old backups on the array that I could use so its not the end of the world. Diags attached. Skipdog unraid-diagnostics-20250122-1401.zip
-
Hi JorgeB, Yes IPMI works great. I went ahead and updated BIOS to 2.0 which i think reset BIOS completely. I went in and played with the legacy USB support settings. Legacy USB was already enabled and when I disable it -- it won't boot UNRAID USB. Not a huge deal- it seems like the X11SDV-4C-TLN2F has issues with USB lower power devices like keyboards/mice and UNRAID. Oh, and yes I did try back of motherboard USB, and i plugged in front USB cable and tried those. They all do the same thing. I appreciate your help! Skip
-
Ah- just figured the slow boot issue was indeed tied to the network interfaces being port up but down. Bootup times are now restored and good! This does leave the USB issue which isn't critical at all. I do see that UNRAID is seeing the low speed keyboard connected. Skip edit: Bus 001 Device 003 Port 1-2 ID 04f2:1125 Chicony Electronics Co., Ltd Asus Keyboard
-
UNRAID Version: 6.12.6 Hi there. I upgraded my Supermicro CS836 X9 based system to a Supermicro MBD-X11SDV-4C-TLN2F-O Xeon D-2123IT. A few problems i'm troubleshooting: 1) UNRAID boot stalls at "Triggering udev events: /sbin/udevadm trigger --action=change" for a long period of time. If I wait long enough it seems to boot and operate OK. I tried a new clean UNRAID USB and it boots up immediately and doesn't get stuck at this point. Do I need to do something in UNRAID to rediscover the new hardware/drivers? I also notice that when it finally does bootup IPv4 Address says "not set" but the webgui does work with the static IP that is assigned. 2) The USB port on the back of the MBD-X11SDV used for keyboard doesn't seem to work once UNRAID is booting/booted. Could this be related to the hardware change and #1? Seems maybe driver related? I dont think i want to rebuild the licensed USB key but open to suggestions to fix. Thanks, Skip
-
UNRAID V. 6.12.6 Supermicro X9DRH with E5-2670 and about 12 drives in array with a cache disk. Installed new container HOOBS and couldn't get homekit to connect to network set in bridge mode. Changed it to custom bridge and immediately fixed the homekit connection issue. However overnight system locked up hard. System locks up if turned on for a period of time. Disabling the custom bridge did seem to allow the system to run normally. Docker setting is Maclan so I will try ipvlan but i'm hesitant to do this being all my other functions are completely normal. Attaching diag. Skip diagnostics-20231203-1416.zip




