




Dreytac
Members
-
Joined
-
Last visited
Everything posted by Dreytac
-
Changing the shares wasn't the fix for the problem. I have containers running on "/mnt/user/appdata" now and they're running fine. I'm 95% positive that setting "Permit exclusive shares" to "Yes" is what fixed the problem for me. I haven't had a single crash related to this Docker issue since changing that setting.
-
I haven't had a single related crash since I made the change of enabling exclusive shares. I feel the issue is with the underlying FuseFS system combined with Docker. Enabling exclusive shares, or changing /mnt/user/appdata to /mnt/cache/appdata, bypasses that system. I still have no idea what is causing the issue in the first place, or if the issue is fixed with current updates (I'm not willing to break something that isn't currently broke to test). I can confirm it started happening during the 6.11 update releases but unsure which one. I didn't end up finding any related Dockers as mine crashed with ANY Docker container accessing /mnt/user/appdata. Interestingly it was only the /mnt/user/appdata share that caused the problem. Other /mnt/user shares operated fine.
-
I finally seem to have fixed this issue! It had NOTHING to do with hardware after all that. I found an obscure Reddit comment from a year ago that mentioned Docker consistently crashing and shares becoming unresponsive after a couple of days. The user worked out that there was a bug in either FuseFS, Docker or Unraid (or a combination) where there is a chance for FuseFS to crash when a Docker container uses a FuseFS share (usually /mnt/user/appdata). Switching all my containers to use /mnt/cache/appdata fixed the problem and they no longer crashed. I found an option in Unraid under Global Share Settings that enables "exclusive shares" so as a test I set my containers back to using /mnt/user/appdata and sure enough, after 2 days, it crashed. I restarted, enabled the exclusive shares option (and made sure to change nothing else) and it's now been 8 days (the longest uptime I've had in over a year) since my last crash, seemingly confirming it's an issue with FuseFS, Docker and Unraid. Unfortunately neither myself or the Reddit poster have been able to find or properly report the issue as it's not consistently reproducible and doesn't generate any logs.
-
Unfortunately the crashing was occurring before the upgrade to 6.12 on 6.11 so the Docker version isn't the issue (I was hoping the upgrade to 6.12 would fix the issue). The only issue I've had with 6.12 was the macvlan issue but that's fixed. I upgraded to 6.12.2 just after this crash but that's unrelated to this problem.
-
I shouldn't have said anything... Docker has crashed again... The only hardware from the original build still there is the H200 and ServerRAID so it must be one of those causing an issue somehow... Those 2 100% cores just stay pinned to 100%.
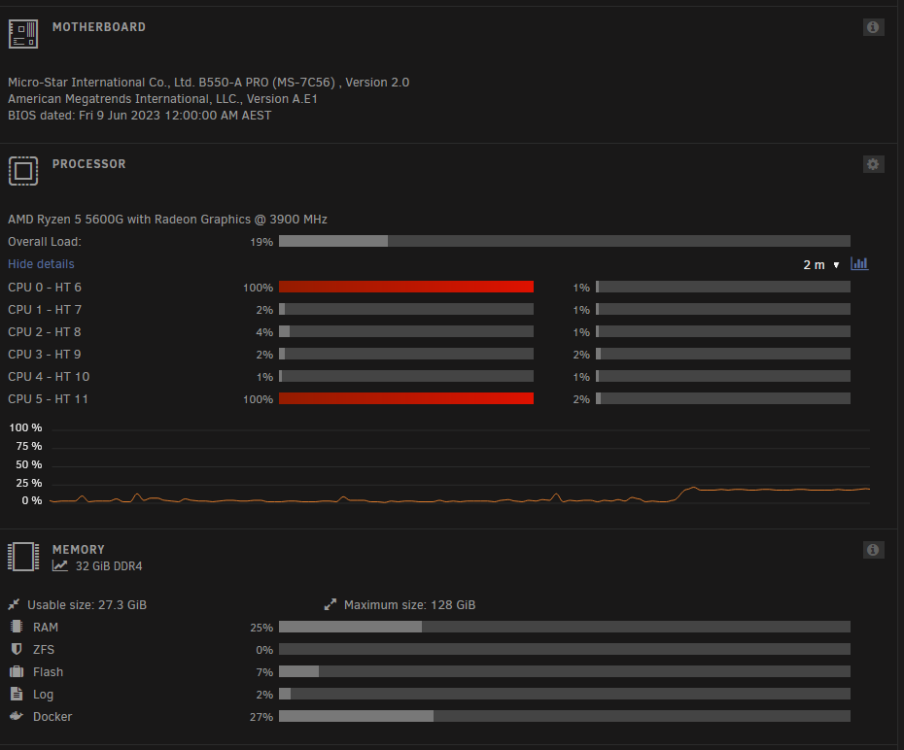
-
6 days after the upgrade and everything is running smoothly. No crashes, lock ups or anything of the like and usually Docker would only last a max of 5 days before crashing. I'm going to put this issue down to a faulty motherboard as the rest of the components had either been swapped or are still in the new build.
-
I assume the BIOS is up to date? Otherwise that's completely understandable. This ones about 4 years old now. Being on a disability pension has forced me to delay the inevitable but Unraid has become a much more important part of my life than I thought a NAS would be. Everything from email to media, cloud storage and home automation is on this thing so I need to keep it running somehow. The downside of how easy Unraid made it to run multiple Docker containers with very little messing around.
-
Yeah, I've been looking at an upgrade for the last few months anyway. I actually bought another CPU at the time for a dedicated game server and swapped them over to no avail. Figured I'd just bite the bullet as this problem doesn't look like something I can fix with software and it's been going on far to long to bother troubleshooting anymore. I'm also over the stress of worrying about if the server will be OK while I leave the house occasionally. Lol. The hard lockups are the final straw as I can't even reboot it from outside the house anymore.
-
Since the 6.12 update it's now completely hard locking the system instead of just crashing Docker. The only way back is to manually power off and on the system. I've tried completely recreating the docker image and all the containers so I'm now more convinced it's a hardware issue. As none of the drives have ever reported an error and the parity check has never found an error I'm going to assume the H200 and ServeRAID cards are fine. I'll be replacing the motherboard, CPU and RAM completely in the next couple days. My best guess at this point is the motherboard has developed a hardware fault.
-
So I've updated to Unraid 6.12 and in 2 days the system has crashed 6 times! I can't get a diagnostics report to complete when the issue happens. It stalls on performing "sed" for the shares. I've tested and replaced all 4 ram sticks, replaced numerous drives, replaced SATA cables, tried enabling docker images one by one for a few days at a time (Docker crashes with random combinations of images running, doesn't seem to be specific). I even tried a complete Unraid reinstall to no avail. No drives are throwing up errors and parity checks are always successful after a crash. When containers become unresponsive, the system appears to continue running until doing anything with Docker. I think I'm going to have to replace the entire system as I can't get any indication as to what is failing. The only difference I've noted with 6.12 is that dashboard processor display continues to update (usually with 1 or 2 random cores stuck at 100%) and the memory display appears normal (instead of displaying all 0%). Running "top" in a terminal shows very little CPU activity so where it's getting the 100% cores from I'm not sure. I've attached the latest diagnostics after a rebooted crash in case anyone can spot anything. Here is a relevant part of the syslog to show it's not reporting ANYTHING (the crash happened around 8:30pm (20:30), I tried to get diagnostics and eventually force rebooted the system at 8:50pm: Jun 19 19:15:10 Groot kernel: eth0: renamed from veth3bc769c Jun 19 19:15:10 Groot kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethfe0bf0c: link becomes ready Jun 19 19:15:10 Groot kernel: br-9d32ee26343a: port 2(vethfe0bf0c) entered blocking state Jun 19 19:15:10 Groot kernel: br-9d32ee26343a: port 2(vethfe0bf0c) entered forwarding state Jun 19 19:15:14 Groot kernel: vethe870c94: renamed from eth0 Jun 19 19:15:14 Groot kernel: br-9d32ee26343a: port 1(veth1d9205c) entered disabled state Jun 19 19:15:14 Groot kernel: br-9d32ee26343a: port 1(veth1d9205c) entered disabled state Jun 19 19:15:14 Groot kernel: device veth1d9205c left promiscuous mode Jun 19 19:15:14 Groot kernel: br-9d32ee26343a: port 1(veth1d9205c) entered disabled state Jun 19 19:15:24 Groot kernel: br-9d32ee26343a: port 1(veth27edc5e) entered blocking state Jun 19 19:15:24 Groot kernel: br-9d32ee26343a: port 1(veth27edc5e) entered disabled state Jun 19 19:15:24 Groot kernel: device veth27edc5e entered promiscuous mode Jun 19 19:15:24 Groot kernel: br-9d32ee26343a: port 1(veth27edc5e) entered blocking state Jun 19 19:15:24 Groot kernel: br-9d32ee26343a: port 1(veth27edc5e) entered forwarding state Jun 19 19:15:24 Groot kernel: br-9d32ee26343a: port 1(veth27edc5e) entered disabled state Jun 19 19:15:24 Groot kernel: eth0: renamed from veth03e77e1 Jun 19 19:15:24 Groot kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth27edc5e: link becomes ready Jun 19 19:15:24 Groot kernel: br-9d32ee26343a: port 1(veth27edc5e) entered blocking state Jun 19 19:15:24 Groot kernel: br-9d32ee26343a: port 1(veth27edc5e) entered forwarding state Jun 19 19:50:02 Groot sSMTP[26172]: Creating SSL connection to host Jun 19 19:50:02 Groot sSMTP[26172]: SSL connection using TLS_AES_256_GCM_SHA384 Jun 19 19:50:05 Groot sSMTP[26172]: Sent mail for [email protected] (221 2.0.0 Bye) uid=0 username=root outbytes=712 Jun 19 20:50:01 Groot root: Delaying execution of fix common problems scan for 10 minutes Jun 19 20:50:01 Groot unassigned.devices: Mounting 'Auto Mount' Devices... Jun 19 20:50:01 Groot unassigned.devices: Mounting partition 'sdm1' at mountpoint '/mnt/disks/torrents'... Jun 19 20:50:01 Groot unassigned.devices: Mount cmd: /sbin/mount -t 'xfs' -o rw,noatime,nodiratime '/dev/sdm1' '/mnt/disks/torrents' Jun 19 20:50:01 Groot kernel: XFS (sdm1): Mounting V5 Filesystem Jun 19 20:50:01 Groot kernel: XFS (sdm1): Starting recovery (logdev: internal) Jun 19 20:50:01 Groot kernel: XFS (sdm1): Ending recovery (logdev: internal) Jun 19 20:50:01 Groot kernel: xfs filesystem being mounted at /mnt/disks/torrents supports timestamps until 2038 (0x7fffffff) Jun 19 20:50:01 Groot unassigned.devices: Successfully mounted 'sdm1' on '/mnt/disks/torrents'. Jun 19 20:50:01 Groot unassigned.devices: Adding SMB share 'torrents'. Jun 19 20:50:01 Groot unassigned.devices: Warning: Unassigned Devices are not set to be shared with NFS. Jun 19 20:50:01 Groot emhttpd: Starting services... Jun 19 20:50:01 Groot emhttpd: shcmd (258): /etc/rc.d/rc.samba restart Jun 19 20:50:01 Groot nmbd[5161]: [2023/06/19 20:50:01.707635, 0] ../../source3/nmbd/nmbd.c:59(terminate) Jun 19 20:50:01 Groot nmbd[5161]: Got SIGTERM: going down... Jun 19 20:50:01 Groot wsdd2[5171]: 'Terminated' signal received. Jun 19 20:50:01 Groot wsdd2[5171]: terminating. Jun 19 20:50:01 Groot winbindd[5174]: [2023/06/19 20:50:01.709400, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) Jun 19 20:50:01 Groot winbindd[5174]: Got sig[15] terminate (is_parent=1) Jun 19 20:50:01 Groot winbindd[5181]: [2023/06/19 20:50:01.710060, 0] ../../source3/winbindd/winbindd_dual.c:1957(winbindd_sig_term_handler) Jun 19 20:50:01 Groot winbindd[5181]: Got sig[15] terminate (is_parent=0) Jun 19 20:50:02 Groot rsyslogd: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="10855" x-info="https://www.rsyslog.com"] start Jun 19 20:50:03 Groot root: error: /plugins/unassigned.devices/UnassignedDevices.php: wrong csrf_token Jun 19 20:50:03 Groot root: Starting Samba: /usr/sbin/smbd -D Jun 19 20:50:03 Groot smbd[11288]: [2023/06/19 20:50:03.909536, 0] ../../source3/smbd/server.c:1741(main) Jun 19 20:50:03 Groot smbd[11288]: smbd version 4.17.7 started. Jun 19 20:50:03 Groot smbd[11288]: Copyright Andrew Tridgell and the Samba Team 1992-2022 Jun 19 20:50:03 Groot root: /usr/sbin/nmbd -D Jun 19 20:50:03 Groot nmbd[11290]: [2023/06/19 20:50:03.933145, 0] ../../source3/nmbd/nmbd.c:901(main) Jun 19 20:50:03 Groot nmbd[11290]: nmbd version 4.17.7 started. Jun 19 20:50:03 Groot nmbd[11290]: Copyright Andrew Tridgell and the Samba Team 1992-2022 Jun 19 20:50:03 Groot root: /usr/sbin/wsdd2 -d -4 Jun 19 20:50:04 Groot wsdd2[11304]: starting. Jun 19 20:50:04 Groot root: /usr/sbin/winbindd -D Jun 19 20:50:04 Groot winbindd[11305]: [2023/06/19 20:50:04.037035, 0] ../../source3/winbindd/winbindd.c:1440(main) Jun 19 20:50:04 Groot winbindd[11305]: winbindd version 4.17.7 started. Jun 19 20:50:04 Groot winbindd[11305]: Copyright Andrew Tridgell and the Samba Team 1992-2022 Jun 19 20:50:04 Groot winbindd[11308]: [2023/06/19 20:50:04.042659, 0] ../../source3/winbindd/winbindd_cache.c:3116(initialize_winbindd_cache) Jun 19 20:50:04 Groot winbindd[11308]: initialize_winbindd_cache: clearing cache and re-creating with version number 2 Jun 19 20:50:04 Groot emhttpd: shcmd (262): /etc/rc.d/rc.avahidaemon restart Jun 19 20:50:04 Groot root: Stopping Avahi mDNS/DNS-SD Daemon: stopped Jun 19 20:50:04 Groot avahi-dnsconfd[5244]: read(): EOF Jun 19 20:50:04 Groot root: Starting Avahi mDNS/DNS-SD Daemon: /usr/sbin/avahi-daemon -D Jun 19 20:50:04 Groot avahi-daemon[11354]: Found user 'avahi' (UID 61) and group 'avahi' (GID 214). groot-diagnostics-20230619-2048.zip
-
Sorry, I have done a 6 hour memtest with both new and old memory in the system (in between my posts from March and now). Came back with no errors reported. Other things I've done since March are replace SAS cables and replaced a few HDD's. The crashes are still intermittent (from hours to weeks) and I still cannot find a single common thing between them which is why I'm presuming it's a hardware fault of some kind. The last thing I did was replace a SATA cable and it's been stable for about 5 days which is unusual but has happened before. The original SATA cable wasn't in the system when these issues started though.
-
Unfortunately not. I believe it's a hardware issue with my setup. I've swapped CPU and RAM so it's either the motherboard, the Dell PERC H200 or IBM ServeRAID card. From what I can gather, a drive stops responding for a short while causing Docker to lock up. Unraid continues to work until something tries to access the Docker daemon (usually me through the Web UI) which then causes Unraid to lock up completely. Once it hits that state, the only way I've found to reboot the machine is the manually power cycle it. If Unraid doesn't lock up, using "/sbin/reboot" twice in a terminal will reboot the machine. The uptime robot solution has been working fine although it isn't a great solution but I don't have funds to try anything else right now.
-
I tried that a few weeks ago. Disabled all Dockers, moved important ones temporarily to another server (read: my PC, not sustainable) and let it run. It went for a week without a crash. Used the next week to enable Dockers one by one and it never crashed. 3 weeks later, the crashes started again. The randomness of this issue is what's making it so hard. It can go anywhere from a few hours to a few weeks between crashes. There is nothing in ANY log file I can find, I can't reproduce it, it doesn't happen with any sort of consistency and it never used to do this pre, I think, Unraid 6.10, but I know it DIDN'T start happening around the time of an upgrade. I can't remember exactly when it started though because I didn't even notice it was problem at first. Just thought the server was being temperamental and lived with it but now I have some more important services running (email, cloud, basically my entire PIM) and it's become a bigger issue. For now I've just setup an uptime robot to monitor the services and when they go down I get notified on my phone, login with Wireguard, fire up a terminal, reboot the server and stop the parity check (it always comes back with no errors and I'm worried doing 3+ parity checks a week is going to kill my drives). One thing to note though, even with everything running on a reboot, it NEVER crashes during a parity check but has crashed within an hour of restarting the server with a canceled parity check. I'll keep investigating but I'm afraid, short of an entirely new server, there's nothing more I can do.
-
Crashed again this afternoon. Literally nothing written to the syslog within 12 hours of the crash. I did try to view the syslog in the terminal after it crashed but before I restarted it. Only got to use the following commands before the terminal crashed and had to reboot manually: cd /mnt ls
-
I've looked at the syslog before and nothing was there but since moving the Shinobi docker off the server, these lines now appear at the time of the crash: Mar 9 12:12:05 Groot kernel: Plex Media Scan[27061]: segfault at 14bb1e40fff0 ip 000014bb23bd28ec sp 00007ffdca0898e0 error 4 in Plex Media Scanner[14bb23b7f000+2df000] Mar 9 12:12:05 Groot kernel: Code: a5 70 ff ff ff 0f 84 fc 00 00 00 48 89 8d 78 ff ff ff 48 8b 01 48 63 08 48 6b c9 68 4c 8b ad 70 fd ff ff 4c 8b bd 78 fd ff ff <4a> 8b 4c 29 c0 48 89 4d 98 4c 63 70 04 49 6b c6 68 42 8b 5c 28 c0 Mar 9 12:12:22 Groot kernel: Plex Media Scan[27466]: segfault at 150692320ff0 ip 0000150697bd28ec sp 00007ffdc2d12a00 error 4 in Plex Media Scanner[150697b7f000+2df000] Mar 9 12:12:22 Groot kernel: Code: a5 70 ff ff ff 0f 84 fc 00 00 00 48 89 8d 78 ff ff ff 48 8b 01 48 63 08 48 6b c9 68 4c 8b ad 70 fd ff ff 4c 8b bd 78 fd ff ff <4a> 8b 4c 29 c0 48 89 4d 98 4c 63 70 04 49 6b c6 68 42 8b 5c 28 c0 Mar 9 12:12:31 Groot kernel: Plex Media Scan[27711]: segfault at 1505486b6fe0 ip 000015054ddd28ec sp 00007fffc6f8fbf0 error 4 in Plex Media Scanner[15054dd7f000+2df000] Mar 9 12:12:31 Groot kernel: Code: a5 70 ff ff ff 0f 84 fc 00 00 00 48 89 8d 78 ff ff ff 48 8b 01 48 63 08 48 6b c9 68 4c 8b ad 70 fd ff ff 4c 8b bd 78 fd ff ff <4a> 8b 4c 29 c0 48 89 4d 98 4c 63 70 04 49 6b c6 68 42 8b 5c 28 c0 These weren't being generated before (when the server would go to 100% usage and crash) so I didn't think to check again. I assume that is causing Unraid itself to crash? Edit: Those lines are the ONLY lines written at the time of the crash BUT they are there EVERY DAY since I removed the Shinobi container, around the same time (12:10 to 12:40) so I'm not sure if they're the root cause as it isn't crashing every time those lines are written. For context, these are the lines written to the log on March 9th up until the server reboot at Mar 9 22:07 (I don't know exactly when the server crashes, only when I first notice Dockers are unresponsive): Mar 9 03:49:36 Groot kernel: br-b34d75de8302: port 15(veth2c58d4f) entered blocking state Mar 9 03:49:36 Groot kernel: br-b34d75de8302: port 15(veth2c58d4f) entered disabled state Mar 9 03:49:36 Groot kernel: device veth2c58d4f entered promiscuous mode Mar 9 03:49:37 Groot kernel: eth0: renamed from vethd0ea9a8 Mar 9 03:49:37 Groot kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth2c58d4f: link becomes ready Mar 9 03:49:37 Groot kernel: br-b34d75de8302: port 15(veth2c58d4f) entered blocking state Mar 9 03:49:37 Groot kernel: br-b34d75de8302: port 15(veth2c58d4f) entered forwarding state Mar 9 03:49:37 Groot CA Backup/Restore: done! Mar 9 03:49:38 Groot avahi-daemon[5344]: Joining mDNS multicast group on interface veth2c58d4f.IPv6 with address fe80::2816:d1ff:fe9b:d45f. Mar 9 03:49:38 Groot avahi-daemon[5344]: New relevant interface veth2c58d4f.IPv6 for mDNS. Mar 9 03:49:38 Groot avahi-daemon[5344]: Registering new address record for fe80::2816:d1ff:fe9b:d45f on veth2c58d4f.*. Mar 9 03:49:39 Groot CA Backup/Restore: ####################### Mar 9 03:49:39 Groot CA Backup/Restore: appData Backup complete Mar 9 03:49:39 Groot CA Backup/Restore: ####################### Mar 9 03:49:39 Groot CA Backup/Restore: Deleting Dated Backup set: /mnt/user/appdata-backup/[email protected] Mar 9 03:49:39 Groot CA Backup/Restore: Backup / Restore Completed Mar 9 03:50:36 Groot kernel: TCP: request_sock_TCP: Possible SYN flooding on port 58946. Sending cookies. Check SNMP counters. Mar 9 05:00:45 Groot root: /var/lib/docker: 47 GiB (50431684608 bytes) trimmed on /dev/loop2 Mar 9 05:00:45 Groot root: /mnt/cache: 115 GiB (123505455104 bytes) trimmed on /dev/sdv1 Mar 9 12:12:05 Groot kernel: Plex Media Scan[27061]: segfault at 14bb1e40fff0 ip 000014bb23bd28ec sp 00007ffdca0898e0 error 4 in Plex Media Scanner[14bb23b7f000+2df000] Mar 9 12:12:05 Groot kernel: Code: a5 70 ff ff ff 0f 84 fc 00 00 00 48 89 8d 78 ff ff ff 48 8b 01 48 63 08 48 6b c9 68 4c 8b ad 70 fd ff ff 4c 8b bd 78 fd ff ff <4a> 8b 4c 29 c0 48 89 4d 98 4c 63 70 04 49 6b c6 68 42 8b 5c 28 c0 Mar 9 12:12:22 Groot kernel: Plex Media Scan[27466]: segfault at 150692320ff0 ip 0000150697bd28ec sp 00007ffdc2d12a00 error 4 in Plex Media Scanner[150697b7f000+2df000] Mar 9 12:12:22 Groot kernel: Code: a5 70 ff ff ff 0f 84 fc 00 00 00 48 89 8d 78 ff ff ff 48 8b 01 48 63 08 48 6b c9 68 4c 8b ad 70 fd ff ff 4c 8b bd 78 fd ff ff <4a> 8b 4c 29 c0 48 89 4d 98 4c 63 70 04 49 6b c6 68 42 8b 5c 28 c0 Mar 9 12:12:31 Groot kernel: Plex Media Scan[27711]: segfault at 1505486b6fe0 ip 000015054ddd28ec sp 00007fffc6f8fbf0 error 4 in Plex Media Scanner[15054dd7f000+2df000] Mar 9 12:12:31 Groot kernel: Code: a5 70 ff ff ff 0f 84 fc 00 00 00 48 89 8d 78 ff ff ff 48 8b 01 48 63 08 48 6b c9 68 4c 8b ad 70 fd ff ff 4c 8b bd 78 fd ff ff <4a> 8b 4c 29 c0 48 89 4d 98 4c 63 70 04 49 6b c6 68 42 8b 5c 28 c0
-
It's happened twice more now. Once yesterday and then once tonight. Can someone point me in ANY direction on where to go from here? I've tried disabling Dockers one by one but as I can't reproduce this issue manually and have to "wait" for Docker to stop working, I can't work out what's causing it and it isn't feasible to have my Dockers down for a week+ at a time. That's if Docker is even the root cause of the issue. Some of the Docker containers appear to still be operating as, for example, Plex logs are still generating (although the media server is unresponsive), Deluge continues downloading, but I can't access any of them through the reverse proxy container or manually via a containers IP:Port. It's almost as though any inbound network traffic is going unanswered but outbound network traffic is working. Clicking the Docker tab still crashes the entire web UI. I can open a VPN tunnel with Wireguard when I notice it has crashed and force a reboot from the terminal. Is there a command I can enter at the terminal to try and generate diagnostics instead of the web UI?
-
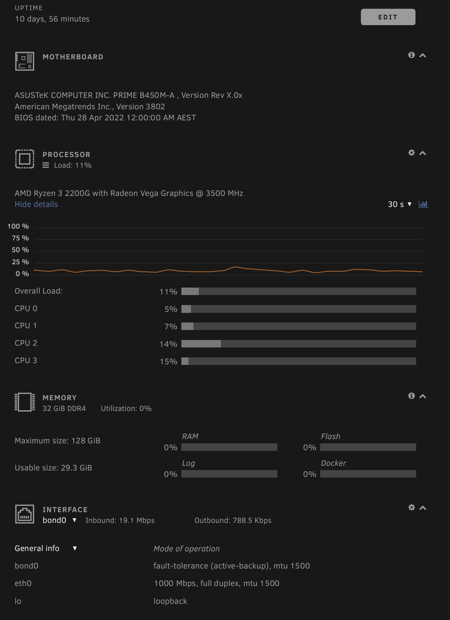
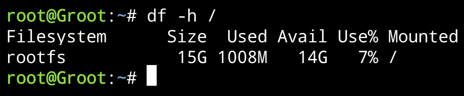
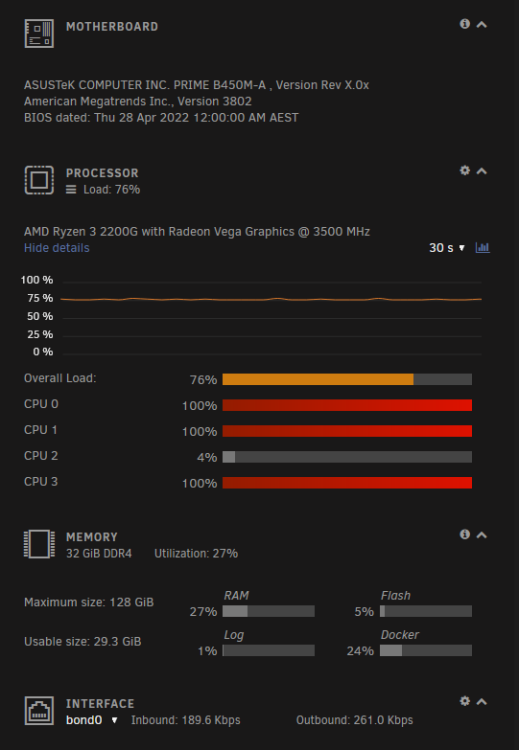
It seems the Shinobi Docker wasn't the root cause. It happened again tonight (after 10 days). It was a slightly different crash this time though. There was no 100% CPU usage and CPU usage appeared to show correctly, updating every second as usual but the RAM, Flash, Log and Docker sections showed 0%. It required a "/sbin/reboot" twice in the console before the server would restart. Here's a screenshot of the dashboard: At this point, Docker is unresponsive, although my downloads (at 19Mbps) appear to still be transferring. Attempting to generate diagnostics stops at the same spot it did before: @trurl: Running that command shows this output: I wish I could provide more information to at least narrow down the cause. There's nothing in the syslog, there's no diagnostics being generated and none of Docker container log files contain any errors.
-
Strangly it hasn't happened since I made this post. The only thing I changed was removing my Shinobi docker onto it's own machine as I wanted to use AI based motion detection. I'm not sure what about that container would cause this issue as it has worked fine for a couple years or it could just be complete coincidence. @cakeman: That does sound VERY similar. Do you happen to run a Shinobi docker container? The only way I could get it to shutdown without manually resetting it was to send the /sbin/reboot command twice to an already open SSH session. @trurl: If it happens again I will run that command and post the results.
-
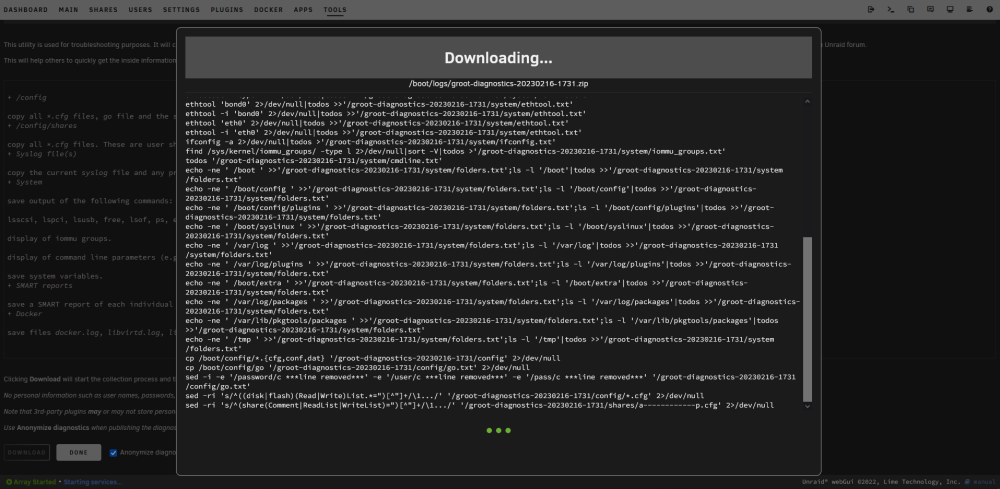
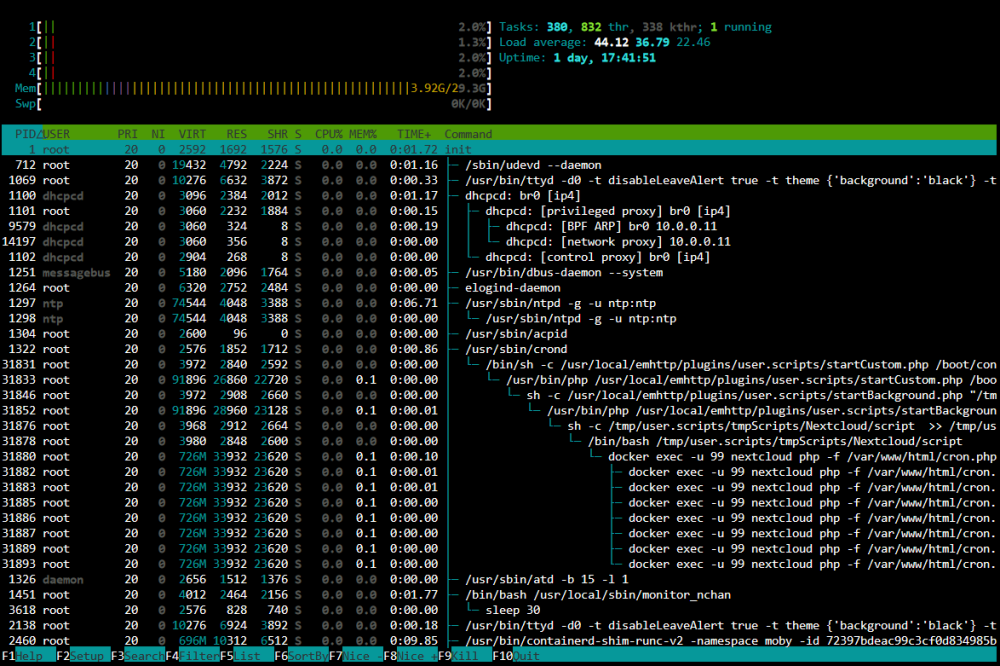
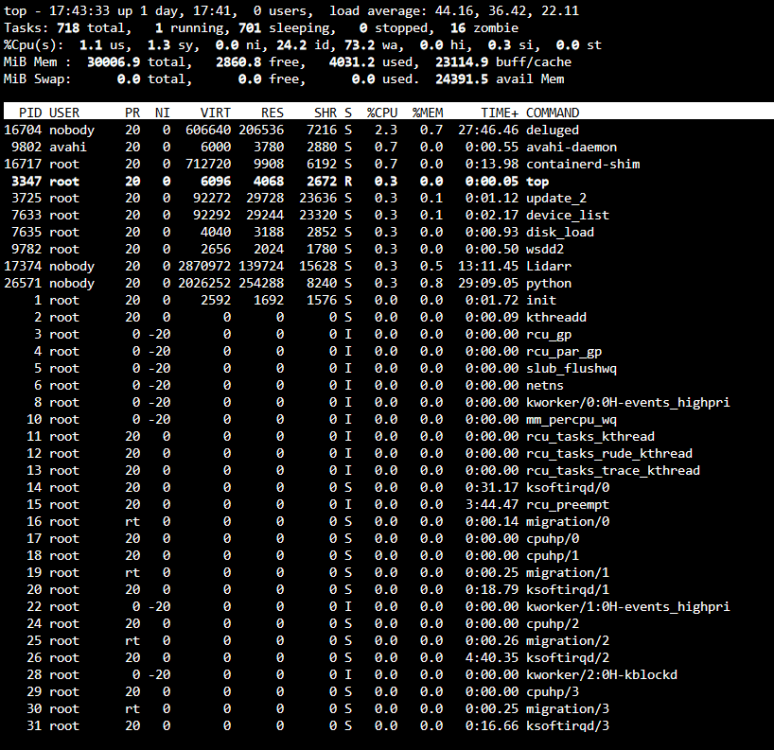
Hi everyone. I've been struggling with this issue for a few months now and can't get to the bottom of it. Randomly (anywhere from an hour to a week), my Unraid server will becoming unresponsive and crash. I usually notice it first as my Docker containers become unresponsive. Checking the web UI, 2 or 3 CPU cores will be at 100% but the UI will still work as long as I don't click on the Docker tab. If I leave it for a few minutes or click on the Docker tab, the UI becomes unresponsive and I have to manually restart the server. Trying to generate diagnostics fails in the generation process as seen in the attached images. The syslog doesn't contain anything consistent and just stops logging at the time the server becomes unresponsive. If I can get to it quick enough, I can use /sbin/reboot in the terminal to reboot the server but a parity check then ensues showing an unclean shutdown. I've attached some images of what I think are relevant but any ideas or suggestions would be appreciated. I'm not sure how to get any better diagnostics when even generating the diagnostics crashes. EDIT: Using Unraid v6.11.5. EDIT2: Attached diagnostics from after a reboot if they're any use. groot-diagnostics-20230216-1815.zip
-
Yeah it's unfortunate that I didn't start my appdata backups until just after this occurred as I was still testing Unraid. Also can't believe I didn't think to wipe the appdata to test if that was the issue...
-
Unfortunately going back didn't work and neither does removing the image and re-installing it. Wiping out my appdata and starting over from scratch has worked but unfortunately my entire library has to be re-added. Copying back the "musiclibrary.blb" file causes the issue to start again.
-
Hi saarg. The docker run command is: docker run -d --name='beets' --net='proxynet' --log-opt max-size='50m' --log-opt max-file='1' -e TZ="Australia/Brisbane" -e HOST_OS="Unraid" -e 'PUID'='99' -e 'PGID'='100' -p '8337:8337/tcp' -v '/mnt/user/appdata/data/':'/downloads':'rw' -v '/mnt/user/music/':'/music':'rw' -v '/mnt/disks/Torrents/':'/torrents':'rw,slave' -v '/mnt/user/appdata/beets':'/config':'rw' 'linuxserver/beets' I've attached the log file. Eventually the Docker container crashes and stops. I can use the terminal in the container fine until it crashes but there is no web-ui. The container worked fine since I installed it weeks ago up until a container update applied a day before my last post. beets-log.txt
-
Hi! I am having an issue with the latest version I updated to today. When running the docker container, the log is spammed with "error: unknown command web". Obviously, I have no web UI with this error occuring. I can still console into the docker and it works until Unraid decides to kill the docker container (I assume due to not being able to startup properly). Prior to today's update, the container was working fine. Nothing else has changed on my end.








