




GerryGER
Members
-
Joined
-
Last visited
-
No splitters, the PSU is also rather new (max. 2 years or so). Because of your previous comment I regained my hope ;) and tried once more. I connected the HDD to a different Port on the JMB and reseated the SATA Power, lets see... Edit: Yeah, that didn't work out. I will switch to a different SATA Power port, just in case... Edit 2: I'm having a virtual stroke right now, I went back and checked my screenshot with all my drives and... well, realized that BOTH MY TOSHIBAS END ON THE SERIAL F94G... when searching the HDD, I only checked those last 4 digits and was working on the wrong drive the whole time! Get the Cat5 o’ nine tails and give me a good whipping and do it again for me still not having labeled them! And do it a third time, for me forgetting that I put the drives in Top Down order from Parity to last Disk inside the case... So I changed the correct SATA cable now and also switched the SATA Power port, just in case. First 150GB are looking fine. Now at 600GB read and its still looking clean. What would the recommended best practice approach be? Rebuilding or trusting the drive? I'm pretty (like 99,x%) sure I haven't written anything to the disk since the error. Moved from it? Not 100% sure, but since the disk is basically full, I doubt it or is the stat on that not correctly displayed, since it was emulated?
-
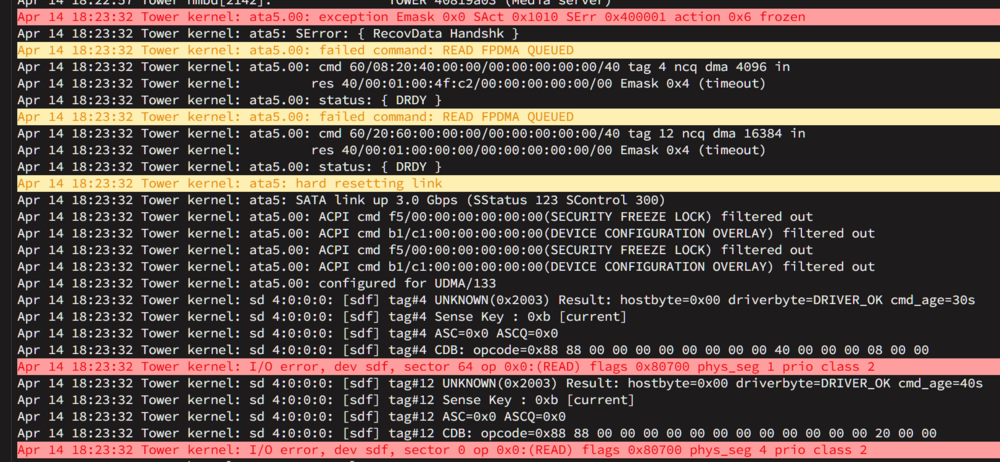
Yeah and that's the problem... I already changed cables twice and used different SATA Ports. The result is still this: I mean I could wait until the HBA arrives and try with that, but I would prefer to try the HBA with a working unRAID... anyway, I ordered brand new SATA cables, just to be sure. I can check those tomorrow.
-
tower-diagnostics-20260414-1826.zip Edit: Wtf is it with the unRAID Forum deleting whole messages, when attaching the diagnostics... anyway, I'm not typing all of it again. TL;DR FYI: OG error happened on Mainboard SATA Port -> new cable and attached to JMB585 -> error occurred again -> switched out to a new cable again and attached back to Mainboard Port since I'm still waiting on my LSI 9207-8i.
-
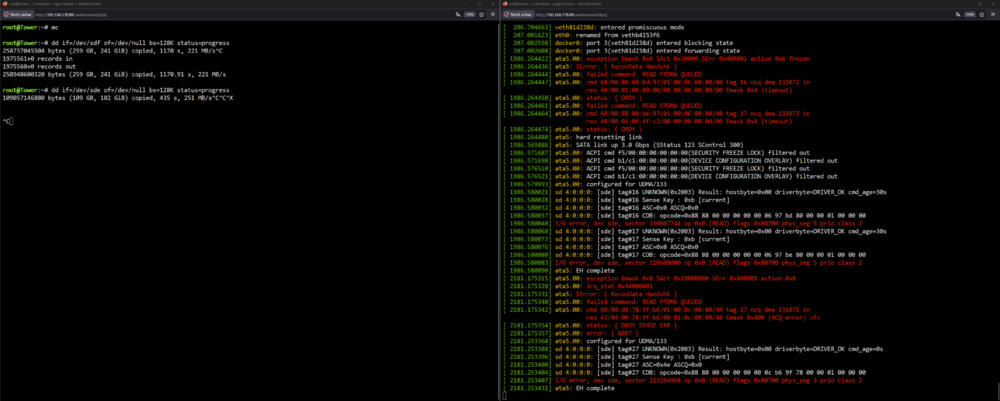
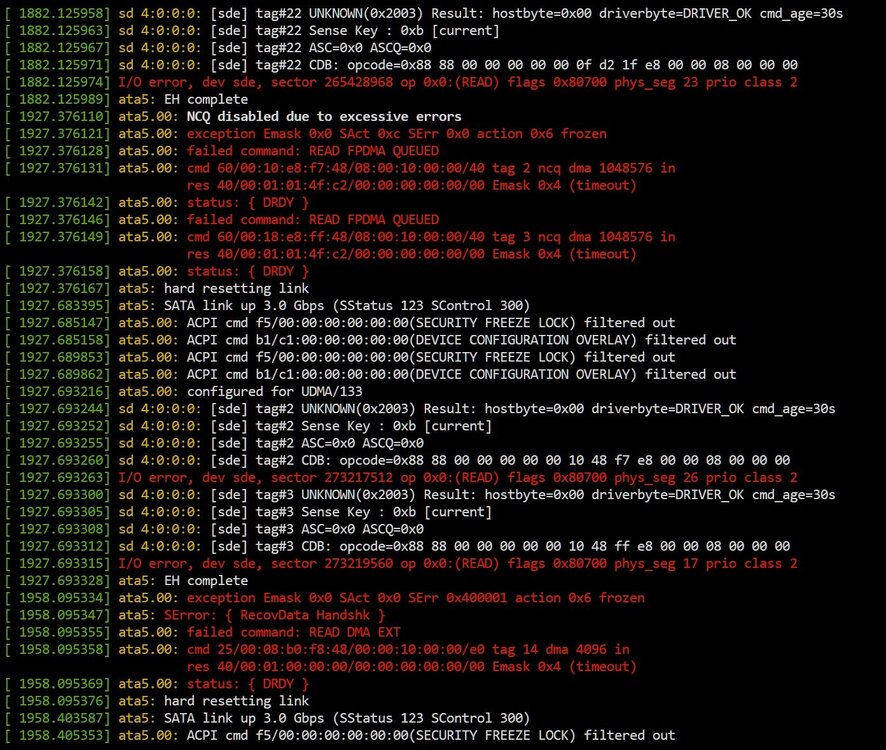
Hi, maybe someone can already help me with this info, I can upload a proper log / diagnostic tomorrow. Apr 12 22:34:40 Tower kernel: ata5.00: status: { DRDY } Apr 12 22:34:40 Tower kernel: ata5.00: failed command: READ FPDMA QUEUED Apr 12 22:34:40 Tower kernel: ata5.00: cmd 60/40:c0:e0:04:5d/00:00:00:04:00/40 tag 24 ncq dma 32768 in Apr 12 22:34:40 Tower kernel: res 40/00:01:01:4f:c2/00:00:00:00:00/00 Emask 0x4 (timeout) ... Apr 12 22:37:56 Tower kernel: ata5.00: sense data available but port frozen Apr 12 22:37:56 Tower kernel: ata5.00: exception Emask 0x10 SAct 0x80fc0007 SErr 0x400101 action 0x6 frozen Apr 12 22:37:56 Tower kernel: ata5.00: irq_stat 0x08000000, interface fatal error Apr 12 22:37:56 Tower kernel: ata5: SError: { RecovData UnrecovData Handshk } Apr 12 22:37:56 Tower kernel: ata5.00: failed command: WRITE FPDMA QUEUED Apr 12 22:37:56 Tower kernel: ata5.00: cmd 61/08:00:28:26:0a/00:00:00:03:00/40 tag 0 ncq dma 4096 out Apr 12 22:37:56 Tower kernel: res 43/84:01:00:00:00/00:00:00:00:00/00 Emask 0x10 (ATA bus error) Apr 12 22:37:56 Tower kernel: ata5.00: status: { DRDY SENSE ERR } Apr 12 22:37:56 Tower kernel: ata5.00: error: { ICRC ABRT } Apr 12 22:37:56 Tower kernel: ata5.00: failed command: WRITE FPDMA QUEUED Apr 12 22:37:56 Tower kernel: ata5.00: cmd 61/08:08:30:26:0a/00:00:00:03:00/40 tag 1 ncq dma 4096 out Apr 12 22:37:56 Tower kernel: res 43/84:01:00:00:00/00:00:00:00:00/00 Emask 0x10 (ATA bus error) Apr 12 22:37:56 Tower kernel: ata5.00: status: { DRDY SENSE ERR } Apr 12 22:37:56 Tower kernel: ata5.00: error: { ICRC ABRT } Apr 12 22:37:56 Tower kernel: ata5.00: failed command: READ FPDMA QUEUED SMART data showed: Reallocated Sectors = 0 Pending Sectors = 0 Uncorrectable = 0 I guessed I hit the SATA cable when I replaced a SSD, so I switched out the cable and also switched the SATA Port, just in case. Did a test read with dd if=/dev/sde of=/dev/null bs=100M status=progress and checked the log: I guess it wasn't just hit to the cable...? I'm still on warranty and checked RMA with Toshiba, but before RMAing and uploading 14TB of data to a friends unRAID, I would like to know if my HDD is dying or my SATA ports are just F-ed, since it's an old Z68 Sandy Bride board. Thanks.

-
So, can I consider everything ok again? What's the safest way to restoring Docker? Deleting it via the WebGUI and restoring the containers? (They should be recoverable via the Docker selection or not?)
-
Must have been an old .cfg as they are definitely NOT shared. Not in unRAID and not visible on the network. Never saw that option, thanks, just did that. I now put it at 15GB min. and cleared up 50GB on the Cache. A few 100GB on the Array itself. As soon as Docker runs again, I can clean up more stuff.
-
Yeah, will do. ;) Attached. tower-diagnostics-20260203-2227.zip
-
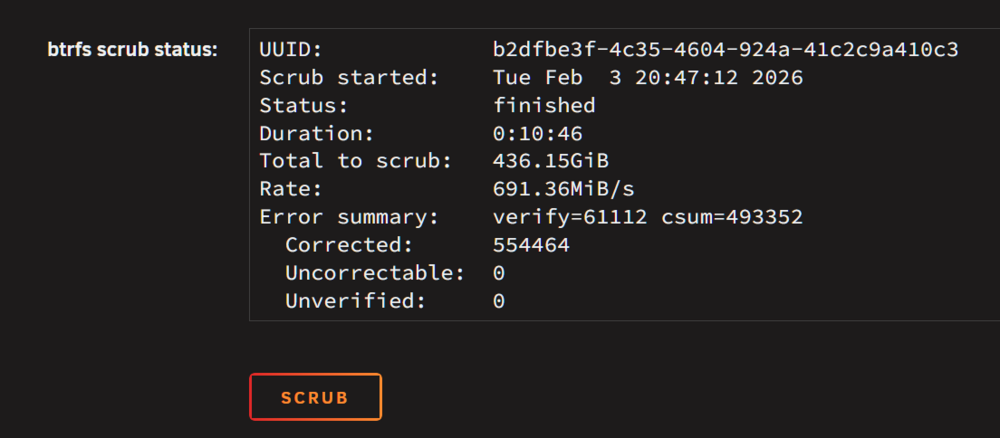
Yeah, with current HDD prices, that is only going to change marginally. Maybe I will gut my 4TB external and use that for the time being. Disabled both, I'm not using VMs anyway. Scrub:
-
Edit: uh... why the hell is all my text gone?! Have to retype this when I'm back. I will keep the diag attached. Reattached the cables and didn't see the errors anymore. tower-diagnostics-20260203-1757.zip
-
Well, I thought I did that... checked all cables and no disk is shown as error / no CRC errors pop up.
-
Hi, I'm greeted on the Docker Tab as the title states: "Docker Service failed to start". I saw that I accidentally filled the whole cache pool and thought.... "Well, I guess that's the problem", cleared up some space and... nope, still failed to start. Then I checked the Log and saw that there were some errors with sdb (which makes me sweat a little, since it's one of my 14TB drives) and BTRFS errors on sdc, which would make more sense in the context of Docker, since sdc should be my cache (pool) and apps/docker are on there. sdc and sdf are some "old" 250GB SSDs which I use for the pool. First I thought it was caused by sdf, since the SATA cable came loose a bit(? -> unRAID reporting the SSD as disconnected) when I opened my case to install an Intel Gigabit CT Desktop NIC, but I guess that was just coincidence? The array wasn't on while I was doing this. How should I go about this? I don't dare to try anything in repairing BTRFS, without someone's more experience opinion... tower-diagnostics-20260202-2156.zip
-
Meh, I actually wanted to say "Latest unRaid update fixed this", but the problem just occurred again, after working for the last few days... Diagnostics is right after it happened again, first the files were written to unRaid with like 50-60MB/s and after a few GB written dropped to 1,3MB/s. tower-diagnostics-20240404-1559.zip
-
So far, no. Only after sleep it seems. But at the other hand... I never kept the server running... I will keep the server running for today and tomorrow and check what happens. Edit: Ironically, that just happened. I rebooted the server, deactivated S3 sleep, copied files, worked for a few GB and then stuck at 1.1MB/S again. Diagnostic attached. tower-diagnostics-20240328-1317.zip
-
So far I couldn't reproduce the mid transfer drop, but attached a log where it got stuck on 1-3MB/s again. Before going to sleep, I copied some files and it worked fine... Yes. tower-diagnostics-20240325-2301.zip
-
I wonder what could cause this? I have been using the S3 plugin for the last 10 years and never experienced something like this. Just now, again it started out perfectly fine, even topping out at 110MB/s, but then gets stuck at 1,xxMB/s...




