




LoyalScotsman
Members
-
Joined
-
Last visited
-
any idea how to fully rule this out ? I do know old provide BT had no issues
-
Adding update have rebooted and fix common problems no longer has alert and logs no longer being spammed but still looking for advise on this to see what caused it and how to provent it thanks in advance for the help
-
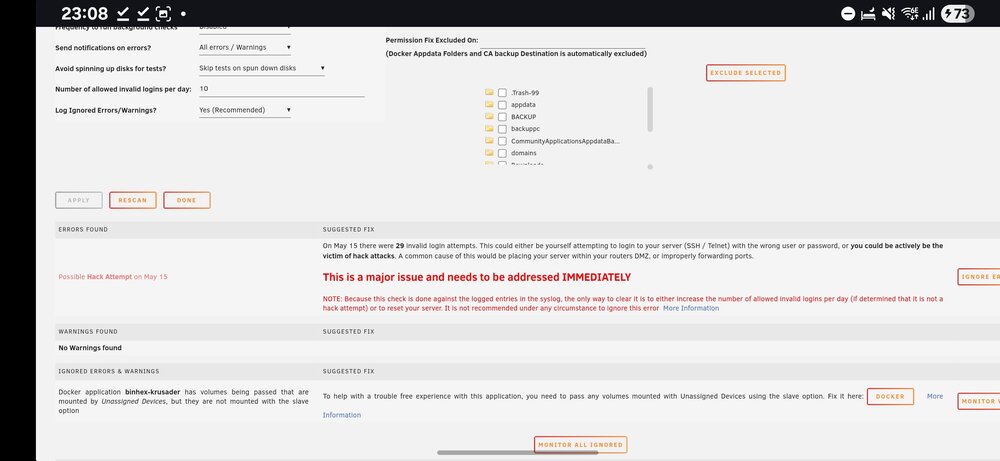
Assistance please turnt my server off today due to electrical work in my house and upon turning back on I'm getting the error Possible Hack Attempt the syslog shows the IP for the router but shown differnet invalid usrs login attempts, any idea what this can be ? Provider is Vodafone and it does have secure net so not sure if it's this causing it As far as I'm aware Plex is only thing that can assess outside my network via UPnp, I have no interest in access my server outside the network other than plex vault101-diagnostics-20250515-2307.zipvault101-syslog-20250515-2206.zip
-
just remembered i have appdata backup setup and it has backups. So i would be good just to recover from that then will be replacing with 2x m.2 drives so will restore to them and see how goes
-
What would you say is best way off doing this ?
-
I have disabled Docker if i remember i have done this in past and its helped speed up the process I have a script set to run hourly to check for corruption due to nearly loosing everything in past Script Starting Jan 31, 2025 11:47.01 Full logs for this script are available at /tmp/user.scripts/tmpScripts/checkcachedrives/log.txt [/dev/sdd1].write_io_errs 0 [/dev/sdd1].read_io_errs 0 [/dev/sdd1].flush_io_errs 0 [/dev/sdd1].corruption_errs 0 [/dev/sdd1].generation_errs 0 [/dev/sde1].write_io_errs 0 [/dev/sde1].read_io_errs 0 [/dev/sde1].flush_io_errs 0 [/dev/sde1].corruption_errs 0 [/dev/sde1].generation_errs 0 Script Finished Jan 31, 2025 11:47.01 Full logs for this script are available at /tmp/user.scripts/tmpScripts/checkcachedrives/log.txt Scrub cant run cause mover is running Daigs attached FYI the reason be hide this is due to upgrading hardware noticed the following in logs could this be related ? vault101-diagnostics-20250131-1201.zip


-
So ran a extended smart test came back - Completed without error it does have - 199UDMA CRC error count - 1 but been acknowledged few years back no issue - disk is old say 7 years roughly going by unraid the 62 errors in above screenshot is new can some review logs and see if issues with disk and should replace or monitor in case increases ? Is there away to clear these errors ? daigs attached vault101-diagnostics-20241211-1344.zip

-
marked your usb as soltuion but once i changed them over to usb3 it was back to normal speeds
-
yeah i tried that no joy so stopped the rebuild and juggled the usb caddle around until i get a new raid card, but turns out the slow speed was cause i used a usb 2.0 instead of the 3.0 port now back up to 100mb/s - 150mb/s
-
is there away to get docker running again without a reboot ?
-
never had the issue before hand but i was thinking that the new USB HHD holder i got might be causing it to run very slow
-
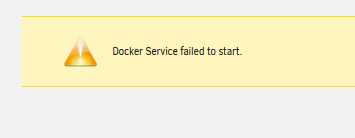
Myself again I have acquired 2 8tb disks so was putting them both into parity so I can upgrade down the line but my estimated rebuild speed shown as 19.9 MB/sec "see screenshot" the history of parity checks are normally around 100 MB/s. "see screenshot" Disk specs New parity 1 disk - ST8000NM012A - RPM 7200 Parity 2 - MG08ADA400NY - RPM 7200 Disk 1 - MG08ADA400NY - RPM 7200 Disk 2 - WD40EFRX - RPM 5400 Disk 3 - MG08ADA400NY - RPM 7200 Old party disk going into array - WD40EZRX - RPM 5400 Parity 2 will be another ST8000NM012A - RPM 7200 disk not yet connected So i know it aint the RPM 5400 causing this slow down since not been an issue in the past there is one error shown but i assume that is due to the new disks temp being hot logs/daigs before i stopped docker - vault101-diagnostics-20240312-1033.zip vault101-syslog-20240312-1032.zip Stopped docker cause there was some activity from plex but made no difference to the speeds Tried to start docker again but I has failed to start don't want to reboot cause the rebuild in progress unless someone advised to reboot but can someone assist here please ? EDIT logs after i tried to start docker vault101-syslog-20240312-1055.zipvault101-diagnostics-20240312-1055.zip



-
thank you i shall do this but another issue occurred so will post this and await response
-
So i have done the above and errors cleared hopefully it also stops the pop up when logging in that occurs ever hour with regards to COW my appdata share is set to auto shares system and domains is set to no how do i change this cause it appears greyed out I assume this COW option is only for shares directly saved on the cache ?

-
the script appears to still be picking up errors is there a command to clear this ? Script Starting Mar 08, 2024 19:47.01 Full logs for this script are available at /tmp/user.scripts/tmpScripts/checkcachedrives/log.txt [/dev/sde1].write_io_errs 0 [/dev/sde1].read_io_errs 0 [/dev/sde1].flush_io_errs 0 [/dev/sde1].corruption_errs 0 [/dev/sde1].generation_errs 0 [/dev/sdk1].write_io_errs 2668196 [/dev/sdk1].read_io_errs 3936 [/dev/sdk1].flush_io_errs 0 [/dev/sdk1].corruption_errs 1779689 [/dev/sdk1].generation_errs 2592 Script Finished Mar 08, 2024 19:47.03








