




BlueSialia
Members
-
Joined
-
Last visited
Everything posted by BlueSialia
-
The problematic server is the Intel one.
-
Any idea on how to find that hardware problem? Memtest passes. SMART checks are clean. What else can I do?
-
This issue keeps happening to me. No clear pattern. And this time no docker appears to function. Sometimes the server reaches an uptime of almost a month, sometimes it lasts less than a week. I plugged a HDMI display to check if something was displayed. It shows a GUI login screen but I cannot interact with it with a plugged keyboard. Also, the HDD LED light of the case is flashing at regular intervals of 500 ms. Any idea on what I can do to diagnose this? I have like 40 dockers in this server. Running in safe mode with all dockers disabled and start them one by one each month will take years. And most of those dockers I use daily. These are the last 2 hours of logs as received on my other server: You can see there that the last entry happened at Jan 12 07:37:36. An user of my Plex confirms that they were using it at 08:25.

-
It took almost 2 weeks for the issue to happen again. So I don't know how I'll be able to tell that it's not happening. I could stop one of the 30 dockers running on it. Spend weeks without having a problem and I'll still doubt if it's fixed or if I was just lucky. It's something I can try, and I appreciate the advice. But it's not very practical.
-
WebUI and SSH stopped working in Server 2 again. This time I didn't do any stuff in Server 1 so it doesn't freeze and I went directly to the syslog because each server sends the syslog to each other. And the syslog of Server 2 has nothing relevant. Latest entries are from almost 12 hours ago and are totally normal: Aug 18 10:52:47 UnBlue2 webgui: fileflows: Could not download icon https://raw.githubusercontent.com/revenz/FileFlows/master/icon.png?raw=true Aug 18 10:53:02 UnBlue2 webgui: grocy: Could not download icon https://raw.githubusercontent.com/linuxserver/docker-templates/master/linuxserver.io/img/grocy-logo.png Aug 18 10:53:03 UnBlue2 webgui: stirlingpdf: Could not download icon https://raw.githubusercontent.com/Frooodle/Stirling-PDF/main/src/main/resources/static/favicon.png Aug 18 11:26:32 UnBlue2 monitor_nchan: Stop running nchan processes Aug 18 11:28:31 UnBlue2 webgui: fileflows: Could not download icon https://raw.githubusercontent.com/revenz/FileFlows/master/icon.png?raw=true Aug 18 11:28:46 UnBlue2 webgui: stirlingpdf: Could not download icon https://raw.githubusercontent.com/Frooodle/Stirling-PDF/main/src/main/resources/static/favicon.png Aug 18 12:27:13 UnBlue2 webgui: Successful login user root from 192.168.10.21 Aug 18 12:27:42 UnBlue2 monitor_nchan: Stop running nchan processesThe latest warning is from over a day ago: Aug 18 04:41:23 UnBlue2 root: Fix Common Problems: Warning: Docker Application frigate has an update available for it Aug 18 04:41:23 UnBlue2 root: Fix Common Problems: Warning: Docker Application grocy has an update available for it Aug 18 04:41:23 UnBlue2 root: Fix Common Problems: Warning: Docker Application paperless has an update available for it Aug 18 04:41:23 UnBlue2 root: Fix Common Problems: Warning: Docker Application qbittorrent has an update available for it Aug 18 04:41:23 UnBlue2 root: Fix Common Problems: Warning: Docker Application Rallly has an update available for it Aug 18 04:41:23 UnBlue2 root: Fix Common Problems: Warning: Docker Application romm has an update available for it Aug 18 04:41:23 UnBlue2 root: Fix Common Problems: Warning: Docker Application swag has an update available for it Aug 18 04:43:14 UnBlue2 root: Fix Common Problems: Warning: The plugin folder.view.plg is not known to Community Applications and is possibly incompatible with your server ** IgnoredThe latest error is from almost a week ago: Aug 13 12:51:45 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 0, async page read Aug 13 12:51:45 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 0, async page read Aug 13 12:51:45 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 0, async page read Aug 13 12:51:46 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 0, async page read Aug 13 12:51:46 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 0, async page read Aug 13 12:51:46 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 4, async page read Aug 13 12:51:46 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 8, async page read Aug 13 12:51:46 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 16, async page read Aug 13 12:51:46 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 32, async page read Aug 13 12:51:46 UnBlue2 kernel: Buffer I/O error on dev md2p1, logical block 64, async page read
-
I have 2 servers. "Main Server" one for VMs with GPU passthrough and a few low resources dockers. The other is the "Media Server" with lots of dockers, specially those that use GPUs for transcoding or AI. I use unassigned devices to mount some shares between them. I woke up this morning and the Media Server was not serving the Samba shares. I go check and WebUI is not there at all. Not even Nginx serving error pages. SSH said connection refused or reseted by peer, I can't remember exactly. But the WebUIs of the docker containers appear to be fine. At least the 3 random ones I checked (Plex, Sonarr & Radarr). I go to the WebUI of the Main Server and click on the share from Media Server that is still mounted according to the WebUI, hoping to see some error or any info. That causes the WebUI to stop responding. Opening a new tab and navigating to the WebUI now causes the browser to forever load a page that never arrives. I SSH into Main Server and look around. Lot's of [Main Server hostname] key.dns_resolver: [Media Server hostname].LOCAL: No address associated with name error logs. lsof doesn't work cause of lsof: no pwd entry for UID 100 and lsof: no pwd entry for UID 508 and killing the processes started by those UIDs is not enough cause they get restarted immediately. Get tired of trying random things so I run diagnostics. Shutdown both servers. Media Server via holding power button because I don't know how else. Power on both and generate diagnostics for Media Server. Here are both attached. Can somebody help me shed some light on what has happened? So far I only noticed the Docker filesystem was at 90% so I increased it. But I doubt that made everything stop working BUT the dockers, right? unblue-diagnostics-20250806-1147.zip unblue2-diagnostics-20250806-1222.zip
-
So what is the prefered solution? Enable Virtual Machine in Windows or disable arch-capabilities in the VM definition?
-
Did you ever figure this out? I'm trying to setup a workflow where Readarr downloads, auto-m4b merges it and then use the single file in Plex, Storyteller, etc.
-
Hey @BAZOOKAPANDA. How are you solving this scenario 3 years later? I'm exploring all the solutions for this now and I'm very sad how every option doesn't work for at least some games.
-
I'm trying to give multiple gaming VMs a place to install games that they can share, so that games do not need to be installed multiple times. First I tried mounting a Samba share but some software does not like to be installed or operate on mapped network drives. So I turned to VirtIO-FS. I followed the instructions in SpaceInvader One video. But some software still doesn't like it. Battle.net refuses to install or operate on any game located there. I created a Reddit post about it looking for help. I've also tried to run Elden Ring and Deep Rock Galactic and both fail. For Elden Ring I've created a Steam discussion. It appears that the issue is always with permissions. Every file in the VirtIO-FS drive is owned by "Everyone" and looks like by default "full control" permissions are given to "Everyone" as well. The permissions can be changed but the owner can't? So I'm guessing some games expect files to be owned by the "User" or the "Administrator" of the system and fail if they are not. Is it possible to deal with this in some way? Or is it still impossible to have multiple VMs share a common place to install most games and programs?
-
I'm aware USB drives can be corrupted. But how can I test for that?
-
A few days ago I updated the BIOS, replaced my RAM and my PSU and upgraded to Unraid 7.0.0 in the same afternoon. Today my server was suddenly super slow. The WebUI would not load, SSHaccess took minutes, random pings took over a second... Then, after 30-60 minutes of that slowness thing became responsive again but the WebUI was all broken up (guess some JS/CSS was not loading) and no commands were available through SSH. Not even top or powerdown. The WebUI was saying the USB drive was corrupted. I shutdown the server holding the power button. Booting it up only was taking me to the BIOS until I took out the USB drive, blowed on it GameBoy-Cartridge style, and connected it again. Now I'm writing this from my usual VM. Everything working as expected. It does look like either the USB or the USB port had an issue. Which steps can I follow to diagnose the USB? Also, just in case, can somebody with more knowledge than me confirm that the upgrades I carried out didn't cause this? unblue-diagnostics-20250120-2016.zip
-
So I enabled bridging, disabled bonding and enabled "preserve custom networks" because I felt brave. But now I have the "Fix Common Problems" plugin mentioning the error "Macvlan and Bridging found" and pointing me to this page. Which is what happened months ago and I disabled bridging because of it.
-
Cannot do it right now because the data rebuild from the drive swap is still going. But will try. Although I think I disabled bridging myself like a month or two ago, when I updated to 6.12.6 and the "fix common problems" plugin told me to because it was the recommended macvlan configuration for docker or something like that. The bonding being enabled... I do think it's useless because I have a single ethernet connection (that's what it is for, right? to use multiple ethernet connections as if it was a single one) but I've had it enabled since day one years ago. So like I have "preserve custom networks" disabled even though I have a custom docker network. I'm afraid to touch it because it works (or was working, at least). What do I get by disabling bonding? Any performance improvement or lower use of resources?
-
Sure! unblue-diagnostics-20240911-1920.zip
-
Everything was working fine. Turned the server off to switch a hard drive for a larger one and now I can't access the Web UI or ping the server from inside a VM. My local network is 192.168.1.0/24. Unraid server is at 192.168.1.3 and the VM is 192.168.1.21. The VM uses vhost0, which I don't know what it means. I also don't understand what virbr0 or docker0 are. Attached is my routing table. br-4ea9173f4445 I guess is a custom docker network I created because I otherwise couldn't make the containers reach each other. I named it "dockernet" don't know why it has a weird name in the routing table. And I don't have "preserve custom networks" enabled, but it doesn't get deleted. I'm afraid to enable it. I've read some posts about adding a route from 192.168.1.0/24 to vhost0, but when I add it nothing changes. The routing table stays the same. Can somebody help me?
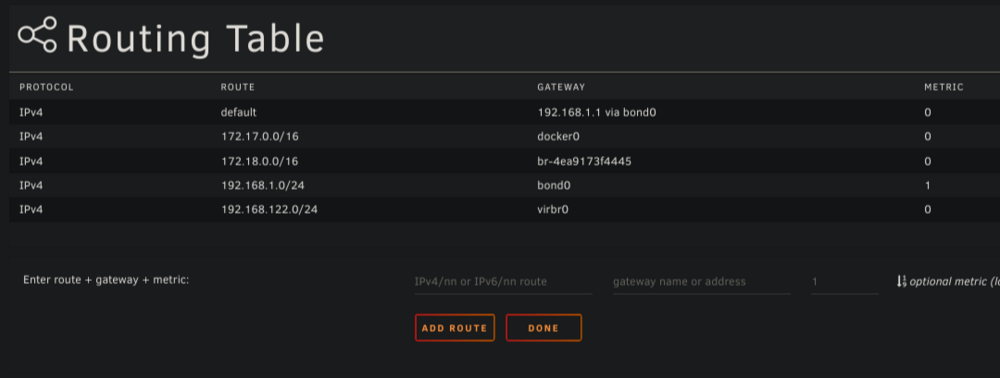
-
A VM was running. I started another one that uses different cores and a different GPU. Entire system almost freezes. The previous running VM is completely frozen. Any docker container like Plex or Nextcloud is totally unresponsible. The Web UI kind of works. Super slow but I manage to generate and download diagnostics which I'm attaching. It took like 15-20 minutes to generate. Then I order a shutdown from the Web UI. That doesn't power off Unraid, but it shutdowns the started VM and unfreezes the second VM that was mid starting. But every USB peripheral that is connected to a USB PCIe card assigned to the second VM is off. I order another shutdown from the Web UI and it shutdowns to the point it doesn't even respond to pings. But the computer is still powered with the fans spinning. After 5-10 minutes since I checked that it didn't respond to pings I manually forced a power off holding the button. I started the VM probably no more than 5 minutes before 20:00. I see lots of errors in the logs about something that cannot change power state from D0 to D3hot and some spurious native interrupt. unblue-diagnostics-20240430-2003.zip
-
So the root of the issue was obvious and so was the solution as well. The docker and libvirt images where precisely in the disk with the least free space. Literaly less than 1 MB. Moving a couple files from that disk to another fixed everything. I was a little bit afraid of doing that while the data recovery was taking place, but everything went well from what I can tell.
-
I had 4 disks in my array. One parity drive of 8TB, two 8TB drives and a 2TB drive. I was rapidly approaching max usage on them so I bought a 16TB drive. Replaced the parity drive with the new drive and recalculated parity. Then, because I didn't monitor it properly I reached 100% of usage on my array. So with the recalculated parity finished less than 24 hours ago I replaced the 2TB drive with the 8TB that I was using as parity before. But now, as the replacement drive is being filled with the data from the replaced drive I have the issues of Docker not starting and no VMs showing in the VMs panel. Extra information: I've also replaced a NVIDIA 1060 GPU with a NVIDIA 4070 GPU at the same time I replaced the 2TB drive. And also enabled the option in Docker about keeping user-defined networks. I've been using a user-defined network for months with that disabled without issue (I think) but I enabled it now because I noticed it was a thing. unblue-diagnostics-20231024-2022.zip
-
Did you figure it out? I just replaced an old and small disk from my array with a larger one and I have the same issue as you. Same libvirt log, just different VMs names, as you would expect.
-
Recently I've discovered that my server was crashing/freezing because the Ryzen CPU doesn't play nice with Linux's c-states. So I disabled them in the BIOS. Which means my server has a power consumption of 150 watts while idle. My system information: M/B: ASUSTeK COMPUTER INC. ROG STRIX X570-F GAMING Version Rev X.0x - s/n: 190754725200579 BIOS: American Megatrends Inc. Version 4021. Dated: 08/09/2021 CPU: AMD Ryzen 9 3900X 12-Core @ 3800 MHz HVM: Enabled IOMMU: Enabled Cache: 768 KiB, 6 MB, 64 MB Memory: 64 GiB DDR4 (max. installable capacity 128 GiB) Network: bond0: fault-tolerance (active-backup), mtu 1500 Kernel: Linux 5.19.17-Unraid x86_64 OpenSSL: 1.1.1s Attached is my BIOS settings. Any clue of what to do to reduce the power consumption? BIOS_setting.txt
-
I finally found a solution. But a very undesirable one. The issue was this. My Ryzen CPU doesn't support Unraid's (Linux) c-states. I disabled them in the BIOS. Now, as it is expected, my server has a very high power consumption even at idle.
-
One year since this started happening to me and the issue is still the same. At some point, the server just dies somehow. The hardware is still on but the system is not even part of the network. And I have no idea about how to debug this problem. I think the only thing I can do is turn off every docker and VM that is not critical, wait and see if it exhibits the same behavior. If by any chance it manages to reach an uptime of a month then I can enable what I turned off slowly. Like one per 2 weeks or something. Even if this works it'll mean months of having most of my things disabled. I'm just hopeless.
-
I didn't upload the entire file. Just posted the log entries of one of the days the server crashed.
-
Yes I did. Just after the post you quoted.

