





Maddeen
Members
-
Joined
-
Last visited
-
Hey, hopefully someone can help me or at least have an idea what can I try I'm running Unraid 6.12.4 with everything updated. I'm also running a Win 10 VM (latest updates done) on it. This VM uses a passthrough Nvidia RTX 2060 Super with USB-C Ports (also passthrough to the VM) On this USB I connected a 10m USB extension kabel and an active USB Hub (this one here -> https://atolla.us/products/4-port-usb-hub-with-power ) On this hub the following devices are attached Plantronics Headset (with external power supply) Razor Basiliks V2 (wired) Steelseries Apex PRO TKL (wired) For over a year it works fine. I might need to unplug/plug the keyboard when changing the USB hub from my unraid server to my MacMini. But this was totally fine for me. But in the last weeks my keyboard start flickering (RGB) and become unresponsive until I plugged it out and in again. It started even when I dont switch from VM to MacMini. When I unplug/plug it immediately starts working - but only for some minutes In my (basic knowledge) of power mathematics I would now assume: The HUB provides 15Watt (5V/3A) The headset got its own power supply = 0 Watts of consum The Razor Basilisk consumes 200mW at 5V = 1 Watt The Apex Pro TKL consumes 600mW at 5V = 3 Watt So in total I need only 4 watts to power all of them. Why doesnt it work anymore Especially due to the fact, that the GPU also provides x-Watts of power to the USB-C port. So it should be def. more power available than I would ever need. For the notes: The keyboard works fine when the USB hub is connected to my MacMini. No flickering, no outtages - just works. So an issue with the keyboard seems to be not the case. It must have something to do with Unraid or the VM itself - at least in my opinion. Highly appreciate every hint you can provide me. THX in advance.
-
Mhh not even one with the same problem or even an idea…. Or are everybody using the binhex-docker of Plex?
-
One additional information that could be useful. Direct streaming is working flawlessly with 9Mbits (of a max 10Mbit due to my ISP) So imho the problem seems to be only relevant for downloading. Why I get worse speed in downloading but nearly full speed (9Mbit) when streaming 🤷🏼 Can’t understand this …. Update - rolled back to plexinc/pms-docker:1.32.1.6999-91e1e2e2c — same behavior… 😞
-
Hi there, Hope someone can help me out of this. I already asked this question in the Plex community - no solution 😞 Sorry for such a long text but I want to put any useful information up in front. I never used the download feature in the past, so I dont have any comparision. But now I went to holiday and want to see some movies while in the plane. First some important notes. I‘m running the official Plex docker on an unRAID server. My clients are a MacMini M1, iPad Pro 12.9“ 2020 and iPhone 13 Pro. Imho not relevant but worth to know, every App, OS are up to date. Which means: Unraid at 6.12.3 Plex Server (docker) at 1.32.5.7328-2632c9d3a iOS/iPad OS at 16.5.1 Every file transfer - local or remote - straight to the server runs awesome. That means, that file transfer from and to the unraid server (also to the shares of movies for Plex) have tremendous speed. Copying in both directions gigabytes of movies within minutes or just seconds (local via LAN or WiFi 6) Even remote downloading / uploading via 5G and my home ISP (40 Mbit/S down / 10 Mbit/s up) running as expected. Which means, that transfering a 1GB file from my server via 5G to my iPad Pro last about 14 minutes. So thats my expectation too, when it comes to „downloading“ movies/series within Plex. But - unfortunaly - its undescribeable worse!! Prior to my flight - while locally connected via WiFi 6 - i started to download two movies with a total amount of only 13GB. In even the worst scenario I can think of, this should only last 10 Minutes. Worst means, that transfer speed has only 150Mbit/s which is very worse, due to WiFi 6 specs and my high performance Unifi network with only WiFi 6 AP Pros. iPad Pro has up to 1200Mbits in theory - so 150Mbit is a very low expectation. Even 300Mbit would be bad imho. For comparision. Downloading the same amount of data from Netflix, Amazon, Sky or Disney runs as expected - fast! But the download of those two files last about 8 hours - forcing me to run my iPad the whole night. Exact time isnt known to me because I went frustrated to bed. Now I‘m in Greece and want to prepair some downloads for my flight back. And again facing this worse speeds. My home ISP provides 10Mbit/s of upload. Currently no one is at home so full speed shouldnt be any problem. Downloading a 300MB episode (as test) isnt even finished after over one hour!!! I tried four different types of transferring: 1) using Wifi of the hotel (about 60Mbits) without VPN to my home network 2) using 5G (about 120Mbits) without VPN to my home network 3) using Wifi of the hotel while being connected to my home VPN 4) using 5G of the while being connected to my home VPN All test cases remains with this worse speed and now I‘m running out of ideas. I also tried the four variants describes above with my iPhone 13 Pro - no changes. I already checked the settings of the Plex app - of the clients and of the server. I have no restrictions - neither on download settings nor in any place. Just set all to „Original“ and „unlimited“ where ever it was possible. Is anyone able to help me… Thanks for any help — i‘m very interested in even the slightes hint… Diagnostics are attached v1ew-s0urce-diagnostics-20230722-1623.zip
-
Thx @JorgeB. That did the trick. Have a nice day
-
Hi, first of all, I'm on the side of the team "never had problems" before. So using unRAID for years now I don't have any problems. After upgrading to 6.12.2 this error is shown by fixed common problems app. macvlan call traces found So as a listening (and a "dont like errors") person I did what was written --> For the most stable system, you should switch the network driver in Settings - Docker (With the service stopped) from macvlan to instead be ipvlan So I stopped the service, change the parameters, started the service and run FCP again. But the error is still there? How do I get rid of this warning now? Or better - after reading some other threads here - should I really change anything besides the fact that I didnt had any problems in the past? I attached the diagnostics file for deeper analysis. hanks for your help. Highly appreciate. v1ew-s0urce-diagnostics-20230710-1625.zip
-
Thanks. I’ll try it but I’m pretty sure that I’ll come back and ask for more support 🙈 Hope you’ll have the time for assisting me again. I’m a complete noob when it comes to CMD/scripting stuff. In the end, my requirement sound easy - just perform a ssh call on a daily basis. But for me it’s mostly rocket science 🙈😜
-
Hey everybody, hope someone can help me out with this because im not that into SSH stuff. Background: I need to perform the following SSH command to reconnect my UniFi Dream Machine Pro to my local ISP. This is recommended to make sure that the reconnect will apply on a time no one at my home cares. Due to the fact that this is a UniFi specific problem I searched in the common communities and found that solution Sadly the person - as you can read - uses a tool called SSHPASS and I‘m not aware how to install/use this on unRAID nor - and this is even more interesting - if I need this tool in this case, because maybe unRAID can handle it out of the box? Here is the command that the person I quoted has stated out. 0 3 * * * sshpass -p <MY_UDM_SSH_PASSWORD> ssh -o StrictHostKeyChecking=no root@<MY_UDM_IP> "killall -HUP pppd" Can anyone help me out here and tell me the best way to achieve my goal? Thanks in advance. Nice easter everybody!
-
I'm not lucky too. I tried this docker because my MacMini stopped "finding" my native unraid TM share. First I set up a share - see first screenshot - honestly 100% like @moritzf After that I installed the docker and left everything as default. See second screenshot. Than I run the command as adviced: sudo chown -R 1000:1000 /mnt/user/timemachine/ Due to the fact that I got no error message this should worked Than - to make sure - I just restarted the docker. But the Time Machine preferences still dont find a correct volume do choose for backup. I also attached the docker_run. Hopefully someone can help me out here. Thanks in advance
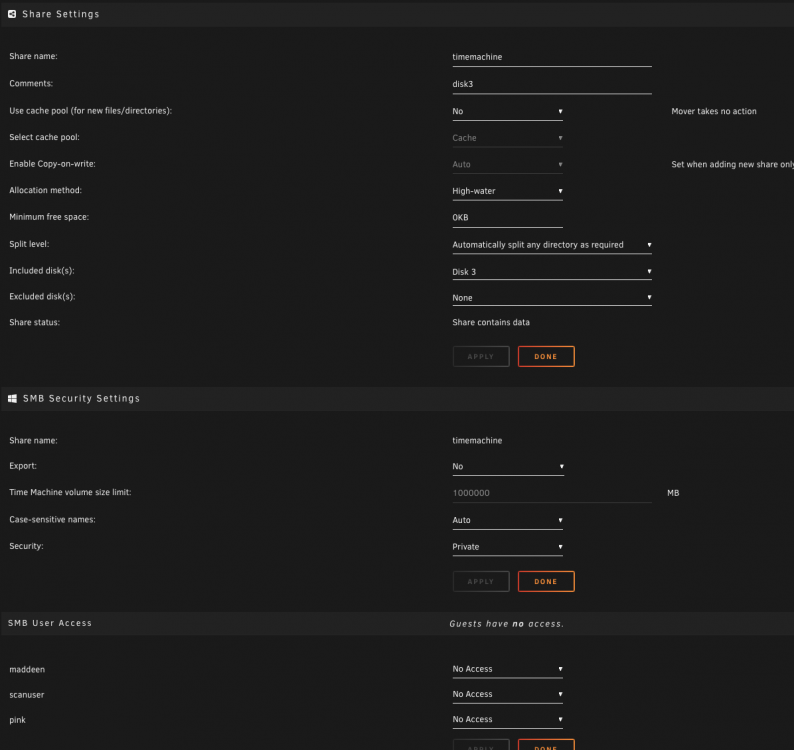
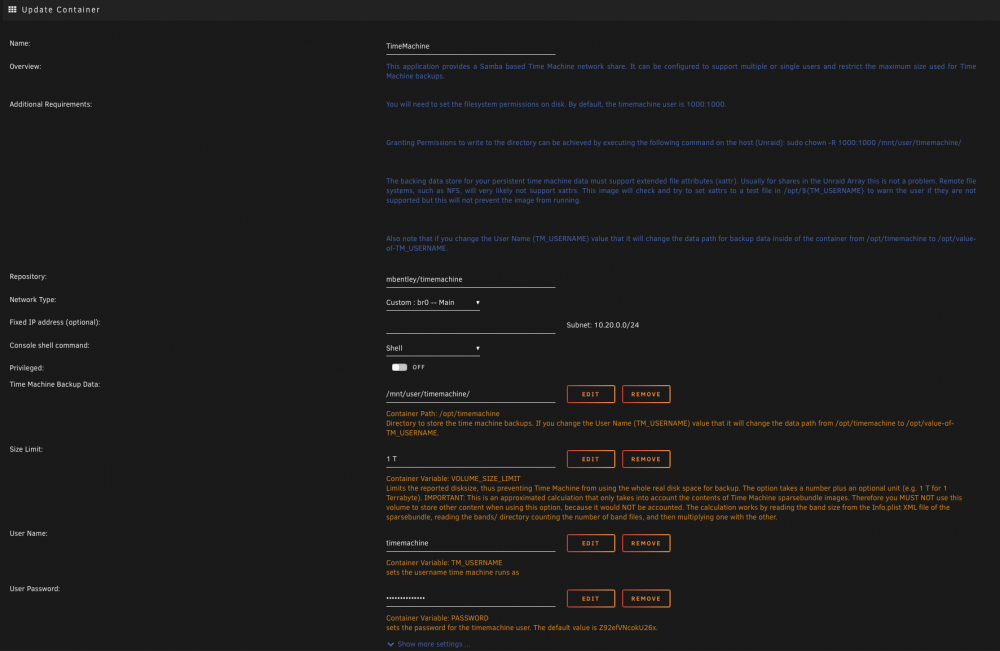

-
Short question: Is it now possible to run a MacOS VM based on ARM? I saw a note in the change log of 6.10 that ARM support was added (experimentally) Or do I misunderstand that note? Thanks
-
@ChatNoir - no - straight via Krusader docker... running in unraid itself. last time I just could browse to mnt -- and then see the directories for cache, disk 1, disk 2, disk 3 e.g. But now - maybe with 6.9.2 - the folder mnt is completly empty. And I just found the shares in /media/
-
That did the trick. 6 Files were corrupt - luckily 5 within the krusader docker and one on the cache drive itself Deleted - run another scrub - all fine. Backup also worked fine. Thank you very much @JorgeB May I ask you one more question? While searching for the corrupt files to delete, I recordnize, that I cant browse to /mnt/diskx or /mnt/cache. But I'm pretty sure that the last time I browsed (months ago) I could easily browse directly to the mounting points. Does anything changed? Thanks again - have a great/happy new year!!!
-
Thanks @JorgeB but how do I do that? I just found another thread where you replied but sadly you nor the thread-starter said how to do this?
-
@JorgeB - Thanks again. Today I received my new RAM. Memtest found no errors and I could succesfully started the "move" process to bring my files from the cache to my normal HDDs. Sadly that seems not to solve all of my problems. I'm still getting this errors when I start a backup of my appdata and libvirt. What can I do now? I attached a new diagnostics zip in this post. Thanks in advance Dec 27 19:05:54 v1ew-s0urce CA Backup/Restore: Using command: cd '/mnt/cache/appdata/' && /usr/bin/tar -cvaf '/mnt/user/unraid_backup/appdatabackup/[email protected]/CA_backup.tar.gz' * >> /var/lib/docker/unraid/ca.backup2.datastore/appdata_backup.log 2>&1 & echo $! > /tmp/ca.backup2/tempFiles/backupInProgress Dec 27 19:06:57 v1ew-s0urce kernel: BTRFS warning (device sdd1): csum failed root 5 ino 20152 off 541986816 csum 0xcbd848d6 expected csum 0x8941f998 mirror 2 Dec 27 19:06:57 v1ew-s0urce kernel: BTRFS error (device sdd1): bdev /dev/sdg1 errs: wr 0, rd 0, flush 0, corrupt 883, gen 0 Dec 27 19:06:57 v1ew-s0urce kernel: BTRFS warning (device sdd1): csum failed root 5 ino 20152 off 541986816 csum 0x7e36f534 expected csum 0x8941f998 mirror 1 Dec 27 19:06:57 v1ew-s0urce kernel: BTRFS error (device sdd1): bdev /dev/sdd1 errs: wr 0, rd 0, flush 0, corrupt 1044, gen 0 Dec 27 19:06:57 v1ew-s0urce kernel: BTRFS warning (device sdd1): csum failed root 5 ino 20152 off 541986816 csum 0xcbd848d6 expected csum 0x8941f998 mirror 2 Dec 27 19:06:57 v1ew-s0urce kernel: BTRFS error (device sdd1): bdev /dev/sdg1 errs: wr 0, rd 0, flush 0, corrupt 884, gen 0 Dec 27 19:10:49 v1ew-s0urce CA Backup/Restore: Backup Complete Dec 27 19:10:49 v1ew-s0urce CA Backup/Restore: Verifying backup Dec 27 19:10:49 v1ew-s0urce CA Backup/Restore: Using command: cd '/mnt/cache/appdata/' && /usr/bin/tar --diff -C '/mnt/cache/appdata/' -af '/mnt/user/unraid_backup/appdatabackup/[email protected]/CA_backup.tar.gz' > /var/lib/docker/unraid/ca.backup2.datastore/appdata_backup.log & echo $! > /tmp/ca.backup2/tempFiles/verifyInProgress Dec 27 19:11:04 v1ew-s0urce kernel: BTRFS warning (device sdd1): csum failed root 5 ino 20152 off 541986816 csum 0xcbd848d6 expected csum 0x8941f998 mirror 2 Dec 27 19:11:04 v1ew-s0urce kernel: BTRFS error (device sdd1): bdev /dev/sdg1 errs: wr 0, rd 0, flush 0, corrupt 885, gen 0 Dec 27 19:11:04 v1ew-s0urce kernel: BTRFS warning (device sdd1): csum failed root 5 ino 20152 off 541986816 csum 0x7e36f534 expected csum 0x8941f998 mirror 1 Dec 27 19:11:04 v1ew-s0urce kernel: BTRFS error (device sdd1): bdev /dev/sdd1 errs: wr 0, rd 0, flush 0, corrupt 1045, gen 0 Dec 27 19:11:04 v1ew-s0urce kernel: BTRFS warning (device sdd1): csum failed root 5 ino 20152 off 541986816 csum 0xcbd848d6 expected csum 0x8941f998 mirror 2 Dec 27 19:11:04 v1ew-s0urce kernel: BTRFS error (device sdd1): bdev /dev/sdg1 errs: wr 0, rd 0, flush 0, corrupt 886, gen 0 Dec 27 19:11:52 v1ew-s0urce Docker Auto Update: Community Applications Docker Autoupdate running v1ew-s0urce-diagnostics-20211227-1914.zip
-
Ahh - ok - so there will be no summary at the end that helps indicating. Thank you. Is it possible that the XMP feature causes this errors? Because I activated XMP due to better speeds with my gaming VM.




