filk
Members
-
Joined
-
Last visited
-
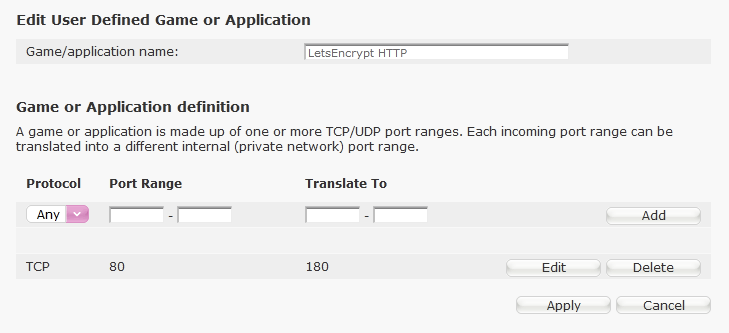
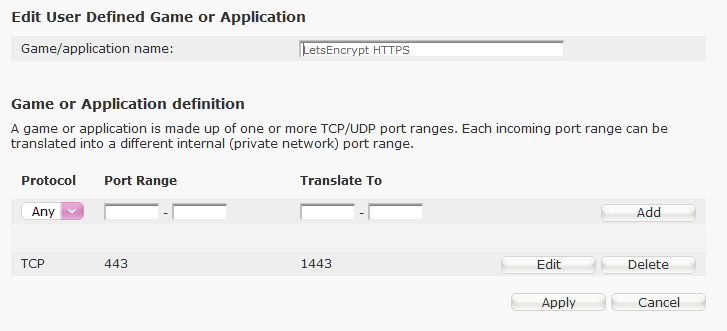
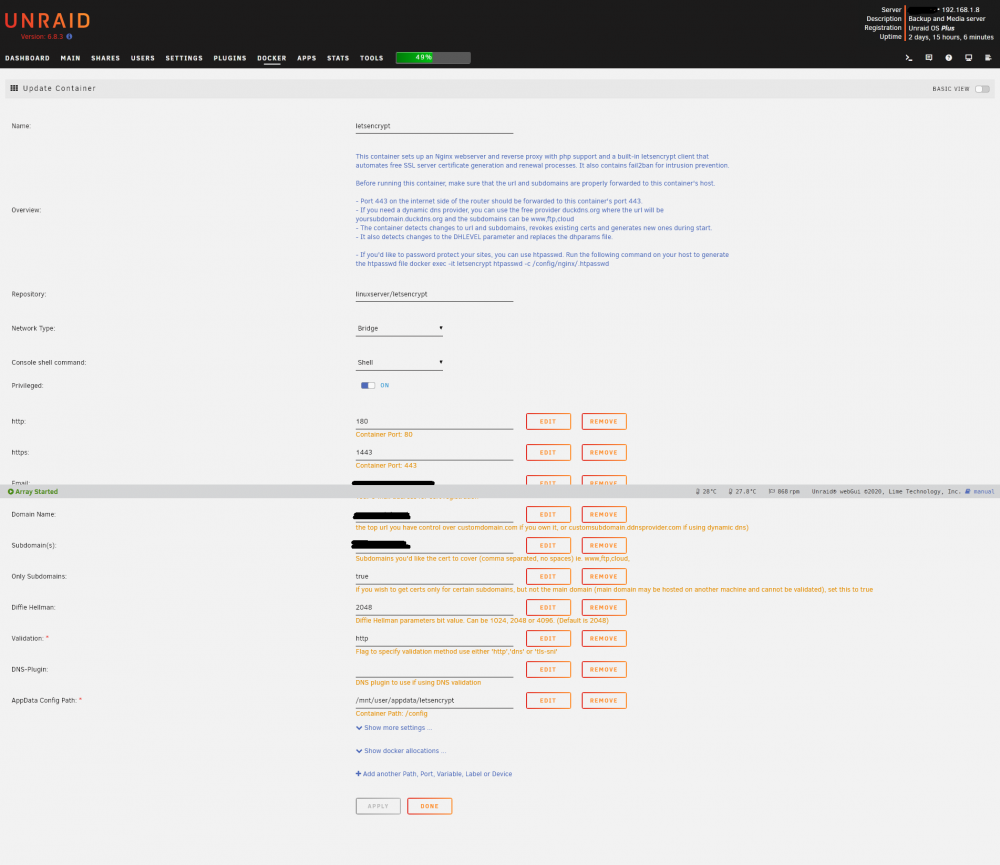
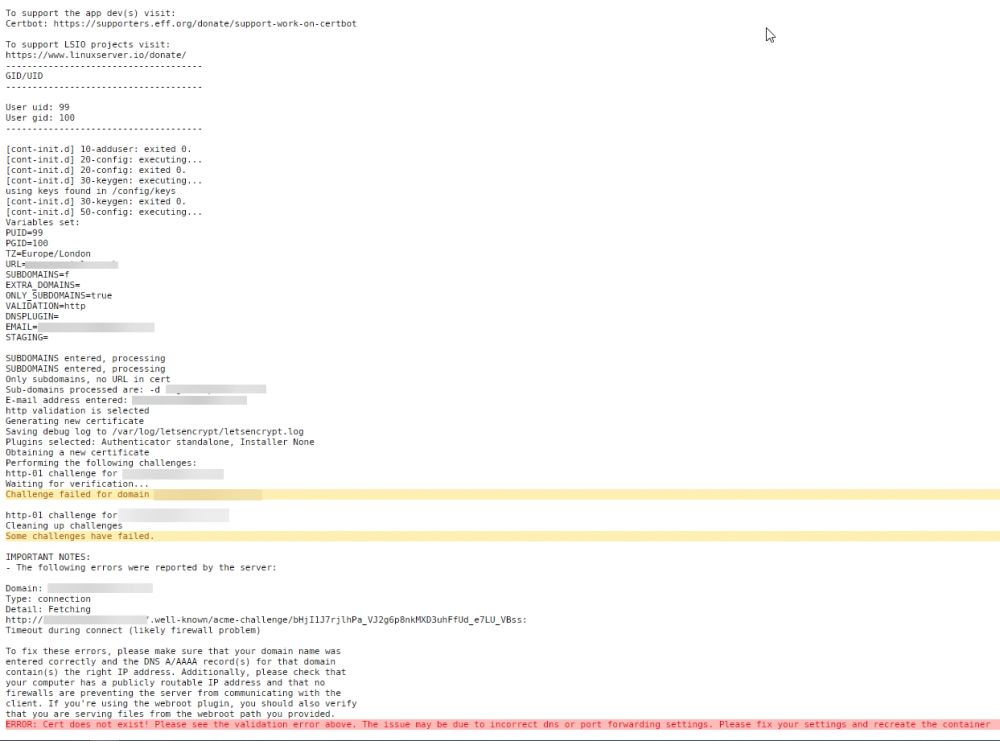
Apologies for hijacking this old thread, but I'm also getting the same issue. My Unraid server is 192.168.1.8, the port forwarding is as follows: HTTP: 180 > 80 HTTPS: 1443 > 443 I've sense checked everything multiple times but I can't find anything wrong with the below which makes me think it's something else but I'm falling short on what it could be. Any help is greatly appreciated!