




rvijay007
Members
-
Joined
-
Last visited
-
Intel support led me to upgrade the motherboard BIOS firmware to the latest Intel microcode (Update Intel uCode to 0x12F), and now my system stability is back to what is expected. Parity finished in an appropriate amount of time (<2 days for 20TB drives), and the system uptime is over a week now instead of crashing all the time. I am still not sure how much permanent damage has been sustained due to the Intel 13th/14th generation bugs, and their support doesn't seem interested in RMAing the chipset, but at least the system is stable again.
-
I reached out to Intel, which said I need to run the following Support Utility to see if it is a CPU error. This does run on Linux, but I'm not sure how I can get this to run on unRAID, or whether it would work at all in a VM. I know how to run it if I have a Linux shell, but unRAID isn't one of the supported types and doesn't work when I try. https://www.intel.com/content/www/us/en/download/18895/26735/download.html
-
I ran memtest86+ v6.20, and it seemed to pass as in the picture down below. Didn't realize that there were Intel 13th/14th gen CPU issues - I also went ahead and updated the motherboard BIOS to the latest stable firmware release. What data from those log files should I send Intel to get the chip RMA'd as I've never done anything like this before? TIA!
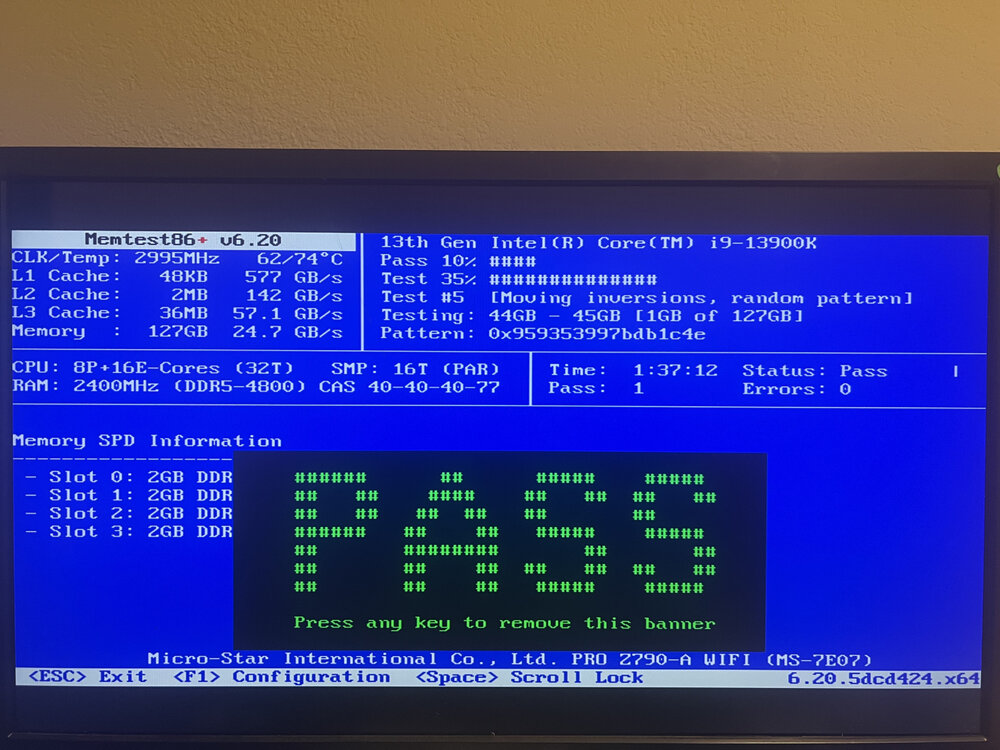
-
I attempted to hit cancel on the below screenshot state. Got the indeterminate progress indicator, but it never cancelled and didn't disappear until I clicked a different tab at the top and returned back to main. And still looks like it hasn't cancelled the parity check. Downloaded the syslog file and updated diagnostics at this point, which are attached below. alexandria-diagnostics-20250522-0202.zipsyslog-10.0.1.9 (1).log
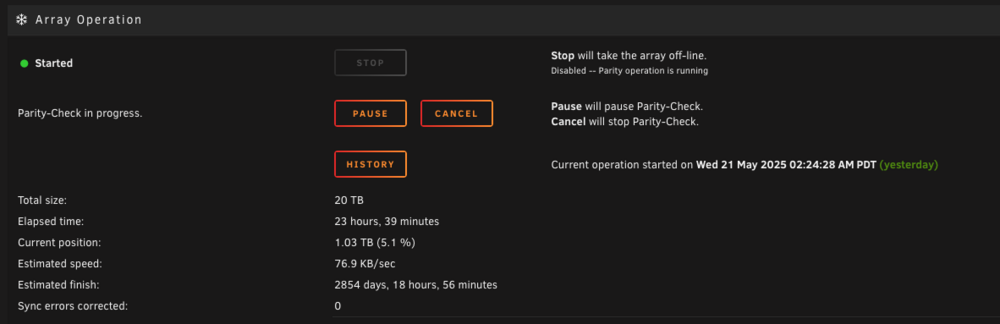
-
Does the memtest86 help diagnose the specific issues? Also, I'm noticing on certain parity runs that the speeds are absymally low, despite nothing aberrant coming up on SMART checks or DiskSpeed plugin, which benchmarks all the HDD drives at sufficient speeds. Parity check operated perfectly fine at the beginning of April, as they had always done. Not sure if this is a related issue or whether a separate problem...
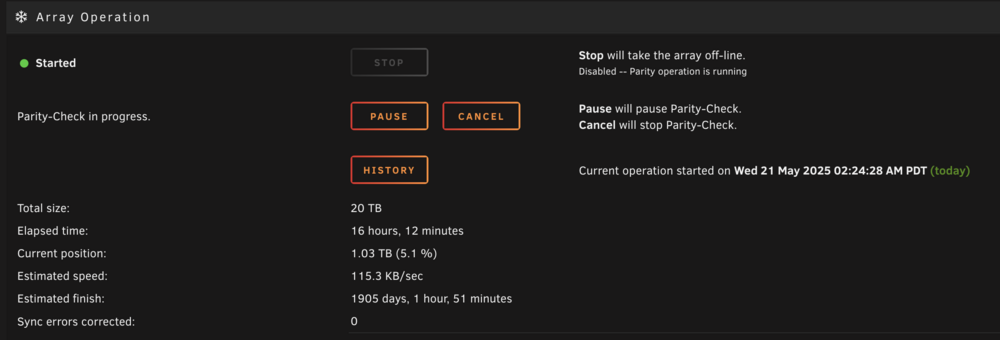
-
11:02 PM PT - Rebooted computer after setting "Mirror to Flash" option in Syslog folder I have enabled the syslog server, writing to my system folder. The system just crashed, around 10:50PM PT (22:50) today, after being up mostly all day. Pulled the syslog and diagnostics file, attached below. alexandria-diagnostics-20250520-2253.zipsyslog-10.0.1.9.log
-
Sorry, that was a title mistype. I'm on v6.12.15. The computer is barely 2 years old.
-
Hi all, I've been successfully running my unRAID server for many years now, but recently, it's been crashing within a day or less. Symptomatically, this appears at the GUI just hanging, and no longer can connect to it via ssh or smb. I'm not sure what is going on, because on reboot, everything seems to be operating properly, and it will work fine for a while, but at some random time, it will just freeze / hang. I downloaded the diagnostics and attached them here after one such recent incident, but could use your help in analyzing them. I've run SMART tests on all my drives (2 parity, 3 disks, 1 SSD cache), and all seem to be reporting just fine (Completed: No Error on SMART Long / Extended Tests), and the SMART values all look good to me. Scrutiny docker also says the drives are fine. Please help! TIA! 🙏 alexandria-syslog-20250516-0937.zip
-
I used this and my Windows11 VM finally booted to finish the Ubuntu 24.04 LTS WSL installation. However, when I checked the VM definition, it seems to have auto changed this section into the following: ``` <cpu mode='custom' match='exact' check='full'> <model fallback='forbid'>Broadwell-noTSX-IBRS</model> <topology sockets='1' dies='1' cores='8' threads='2'/> <feature policy='require' name='vmx'/> <feature policy='require' name='vme'/> <feature policy='disable' name='pcid'/> <feature policy='require' name='f16c'/> <feature policy='require' name='rdrand'/> <feature policy='require' name='hypervisor'/> <feature policy='require' name='arat'/> <feature policy='require' name='xsaveopt'/> <feature policy='require' name='abm'/> </cpu> ``` which seems to the be opposite of the intended effect. I'm running an Intel 13900K processor; does this have anything to do with this re-definition?
-
My server is on the exception list and the blocker doesn't show as processing on the server's address/webUI.
-
I have moved the system share to the Cache. One thing I noticed is that my cache is reporting 90.4GB used, but I have a VM that alone is 400+GB, as show in the screenshots below. Is this a clue as to what may be going on since the values aren't even being reported correctly, or is this a different issue?


-
Looks like other users are experiencing this issue as well, as seen in this new Reddit thread:
-
No, it doesn't. Steps performed: 1. Clicked the button to explore the disk contents in the webUI 2. Clicked back to go back to the Main screen 3. Blank disks as in the original post photo 4. Since webUI terminal doesn't work, I ssh'd into the server and typed touch /mnt/disk1/junk 5. Checked webUI, still nothing appears 6. Confirmed over ssh that file exists. Then deleted file. 7. webUI still doesn't show anything on Main
-
Anytime I explore a disk contents within the webUI, and then go back to the Main Tab in the webUI, all my disks don't show up, and my unRAID becomes more unstable. Trying to go to the webUI Terminal doesn't launch the Terminal (white screen), but I can navigate to other tabs. Trying to download diagnostics just seems to hang the UI, though I can hit Esc to quit the window. I can also launch VMs, and connect to shares via SMB, so things are working. Trying to manually invoke the Mover never seems to move any files, whereas hitting the "Move" button always used to invoke the Mover with older versions of unRAID. This UI issue seems to resolve when I reboot/shutdown the server and restart it, but will reoccur once I explore any disk. SMARTCTL doesn't show any issues on any of the disks. Given 10-20 minutes, the disks finally refresh and show up, but the issue immediately happens again if I explore into any disk. Does anyone know what is going on here??? Thanks in advance! alexandria-diagnostics-20240325-1247.zip
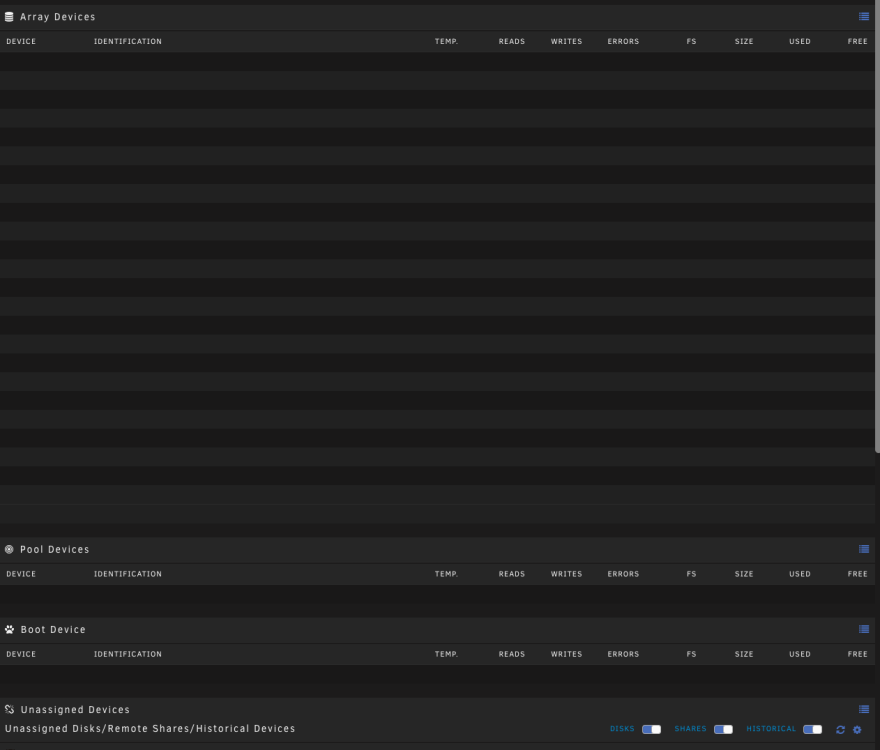
-
It's been up to date (v2024.01.11.1434), but I see my server has been on longer than the latest version. Will reboot - thanks!






