

Juniper
-
Posts
39 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Juniper
-
I wanted to add the 3 TB drive once the parity synch is done. Then do it again. First make sure it works then add the 3 TB drive, then run parity again. Thank you! I'll try that now: unassign the parity drive, start stop the array then reassign it and let parity synch run. This time it worked. Parity is building now with 8 TB. When it's finished I'll add the 3 TB drive and let it rebuild again. Will let you know when it's done.
-
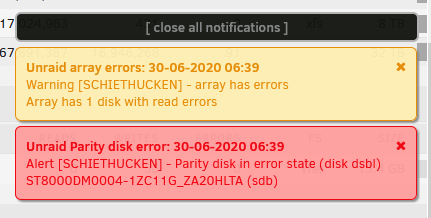
Unfortunately the parity rebuild on the original 8 TB parity disk complained: Log said: "Jun 30 06:38:09 Schiethucken kernel: sdb: rw=1, want=15628053176, limit=15628053168" and "Jun 30 06:38:09 Schiethucken kernel: attempt to access beyond end of device" How can I rebuild the parity on the smaller drive? schiethucken-diagnostics-20200630-0803.zip

-
Copying done. Array rebuilding parity now after taking out the former parity drive with https://wiki.unraid.net/Shrink_array "Remove Drives Then Rebuild Parity". Trying to rebuild parity on the old 8TB parity drive. Takes probably about 15-19h. But Unraid says it wants to rebuild 10 TB of parity, even though the data drives are all 8 TB. Let's see what happens. It took the assignment of the former parity drive back as parity drive without complaining.
-
I checked: it's just about 1.2 TB on the 8TB former parity drive now. I'll copy them back to my Win PC. Identified the exact stuff that is on the drive. Should take about 1.5 to 2 days. Will report back when everything is copied. This whole project will take about 1 week. But once it's done we'll know more, and I can then copy all the remaining data to the array from all the old drives I still have flying around somewhere. Then everything will be safe and sound on the array.
-
I'll try that. :) Will look stuff up and report back on progress.
-
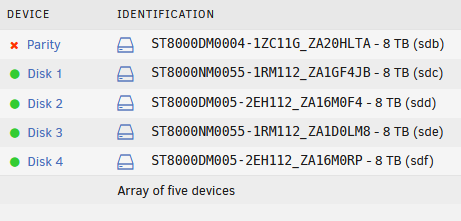
Is there a way to swap the parity from the 10 tb drive to one of the 8 TB drives? If yes, I can check which of the data drives has the least amount of stuff, and copy it to the other drives. Then when that data drive is empty I can try it backwards, and then repeat it with the same configuration. Just when I checked yesterday I couldn't find anything to replace a drive, data or parity, with a smaller drive. The 10 TB Iron Wolf is the largest drive I possess. If there is a way I'll do it. The original configuration was: 5 8TB drives and 1 3 TB drive. I could empty an 8 TB drive then try "shrink the array", add the 3 TB drive again and try a parity swap replacing the 10 TB Iron Wolf with the prior emptied 8 TB drive.
-
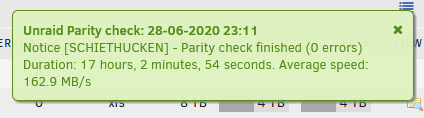
Parity check finished: 0 errors Problem solved. Thank you guys very much for taking the time and helping me! My configuration seems to help make the bug occur. Would be happy to help test it. Don't have another drive big enough to do more parity swaps under a different Unraid version but maybe there is anything else you guys can think of I could do to help.
-
Before I bought the new drive the array had 5 8TB drives and 1 3 TB drive. Then I bought the 10 TB Iron Wolf. I ran parity swap to use the Iron Wolf as the new parity drive, and replace the 3 TB drive with the old 8 TB parity drive. Sorry for not mentioning it earlier. Was worried about the 3.8 mil errors and somehow forgot. As part of the parity swap I took the 3 TB drive out of the array. Then the parity swap continued with swapping the parity from the old 8 TB parity drive to the new 10 TB drive and rebuilding the data of the drive I took out on the old parity drive, effectively turning it into a data drive. That is what I meant by "afterwards the old parity drive was added as data drive to the array". It makes sense now: the new parity drive is 2 TB larger than the old parity drive. Means I ended up with 2 TB of unsynched parity. That sounds so much better than 3.8 mil errors on the new drive. Thank you very much for your help! I'll start another parity check and will report back.
-
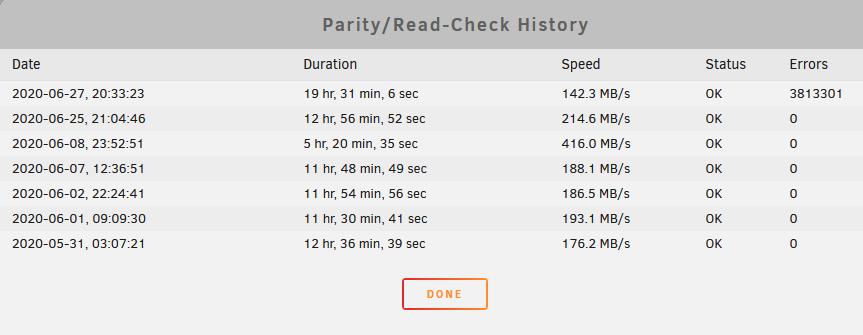
Unraid 6.83, 6 drives: 5 8TB Data drives, 1 10TB parity drive, no cache at this time. Unraid user since maybe 3 weeks. Got a new parity drive (Seagate Ironwolf 10 TB), and precleared it with the "Preclear Disks" plugin (1 pass). Test showed no problems. Then I ran the Parity swap procedure step by step as described in https://wiki.unraid.net/UnRAID_6/Storage_Management#Parity_Swap The Parity Swap procedure read the old parity drive (Seagate Exos 8TB) and copied the parity info to the new drive. Afterwards the old parity drive was added as data drive to the array. It finished successfully, no errors were reported. I was able to access all my shares just like before. Afterwards I copied ~3 TBs more data to the array. Then I started a Parity Check. The "write correction to parity" box was default checked I think. It ran 19.5h and when finished it reported 3.8 mil errors. During the parity check I only read from the array (watched videos from it), and didn't change or copy anything to it. The smart reports of the drives were fine before the parity check, just the known CRC errors for the drives where I once had problems with in my Win 10 pc. After the parity check I ran short smart tests on all drives: no errors. I got no idea what happened. The display in "Main" always showed "Parity is valid" before and after the parity swap, and also before and after the parity check. The temp is always around 30-33C on all drives, regardless of activity. The parity drive could not have gotten too hot: drives are in the cages from my old Antec 900 case (with new powerful fans). The syslog shows: parity check started at 1am, ran without any reports in the log for ~13h, then the errors started: Jun 27 01:02:17 Schiethucken kernel: md: recovery thread: check P ... Jun 27 03:40:01 Schiethucken root: mover: cache not present, or only cache present Jun 27 10:47:40 Schiethucken webGUI: Successful login user root from 192.168.1.152 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628053640 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628054664 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628055688 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628056712 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628057736 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628058760 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628059784 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628060808 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628061832 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628062856 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628063880 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628064904 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628065928 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628066952 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628067976 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628069000 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628070024 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628071048 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628072072 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628073096 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628074120 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628075144 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628076168 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628077192 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628078216 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628079240 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628080264 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628081288 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628082312 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628083336 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628084360 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628085384 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628086408 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628087432 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628088456 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628089480 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628090504 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628091528 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628092552 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628093576 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628094600 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628095624 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628096648 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628097672 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628098696 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628099720 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628100744 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628101768 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628102792 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628103816 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628104840 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628105864 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628106888 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628107912 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628108936 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628109960 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628110984 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628112008 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628113032 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628114056 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628115080 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628116104 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628117128 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628118152 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628119176 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628120200 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628121224 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628122248 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628123272 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628124296 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628125320 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628126344 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628127368 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628128392 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628129416 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628130440 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628131464 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628132488 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628133512 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628134536 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628135560 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628136584 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628137608 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628138632 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628139656 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628140680 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628141704 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628142728 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628143752 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628144776 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628145800 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628146824 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628147848 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628148872 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628149896 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628150920 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628151944 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628152968 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628153992 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: P corrected, sector=15628155016 Jun 27 14:02:53 Schiethucken kernel: md: recovery thread: stopped logging Is maybe the new parity drive defective? It survived the preclear test which ran 2 days (1 pass), and its smart short test after the parity check shows no errors. Is there anything I can do to fix this? Maybe run more tests on the new parity drive, e.g. run preclear again with more passes? I installed the "Parity Check Tuning" plugin, but I checked the log: that was hours after the errors had started. That could not have caused them. Attached are the diagnostics, and screenies with the disk configuration and the parity check info. Thank you very much for reading this! schiethucken-diagnostics-20200627-2209.zip


-
Could my Marvell controller have caused these errors?
Juniper replied to Juniper's topic in General Support
very sorry about this: each time I made a hardware change the system overwrote its logs. Noob here: I didn't know that I could generate logs with all system info. Still learning about Unraid. Next time I'll make diagnostics each time before hardware changes, and each time before shutting system down after errors, and save them somewhere. Thank you very much for having taken the time to help me! -
Could my Marvell controller have caused these errors?
Juniper replied to Juniper's topic in General Support
I checked and saw my return window closes today, so I brought the SSDs back to Best Buy. They might be fine, but after 12 days of error messages it felt better to run it safe. Will buy new ones. Thank you everybody who read my post, and a big special Thank you to johnnie.black for responding and willingness to wade through my diagnostics :) -
Could my Marvell controller have caused these errors?
Juniper replied to Juniper's topic in General Support
Thank you much for responding. Here are the diagnostics. The system is running just the array. No VM or anything else. Just the community plugin in case I want to play with docker sometime later. schiethucken-diagnostics-20200613-1158.zip -
Hardware config: ASUS P8Z68 Deluxe with 8 GB RAM, 2 port Marvell 9128 SATA 3, 2 port Intel SATA 3, 4 port Intel SATA 2 Intel I7-2600K (not OCed) Drives: Cache: 2 Samsung 860 EVO 1 TB (connected to Marvell 9128) Parity: Seagate 8 TB (connected to Intel SATA 3 port) Data: 4 Seagate 8 TB, 1 Seagate 3 TB Flash: Sandisk Cruzer Glide 15.4 GB Power: Rosewill 1000 watt power supply, 3 hard drives on each power strip I'm combining my Win 10 drives into an Unraid NAS. Cleared out 2 disks to start, then copied over / added the other disks to the array. During the copying (roughly 16 TB total) I often ran into errors in the log saying: kernel: ata19.00 exception Emask 0x0 SAct 0x800000 SErr 0x0 action 0x6 frozen kernel: ata19.00 failed command WRITE FPDMA QUEUED kernel: ata19.00 cmd 61/08:98:18:7b:20/00:00:0b:00:00/40 tag 19 ncq dma 4096 out kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) kernel: ata19.00 status: { DRDY } kernel: ata19: hard resetting link kernel: ata19: SATA link up 6.0 Gbps (SStatus 133 SControl 300) kernel: ata19.00: supports DRM functions and may not be fully accessible kernel: ata19.00: supports DRM functions and may not be fully accessible kernel: ata19.00: configured for UDMA/133 kernel: ata19: EH complete kernel: ata19.00: Enabling discard_zeroes_data Several instances of the above sequence were noted in both cache ssd's logs. None of the other drives had errors in their logs. I searched the forum and found other people with similar error messages. Recommendation was to change cables. I changed SATA cables to cables that have worked on other drives, and ran a test (copying 800+ GB to a new test share that uses the cache. First let it copy for 1h, then start the mover): same errors. I changed SATA cables to new fresh cables: test showed same errors Added a new power cable to my powersupply, and moved the 2 cache SSDs to it. Nothing else is on it: test showed same errors Bought new fresh molex to sata adapters and used them for the SSD drives: test showed same errors The last piece it could be was ... the SATA controller: the cache drives were connected to the Marvell 9128 on my motherboard. When I searched the forums for Marvell I found all kinds of warnings and yes, many folks had complained about similar errors with controllers from Marvell. I checked the forum and the 2 port Asmedia controller I still had lying around was supported. I added it to the array, connected the cache drives to the intel sata 2 controller and moved 2 data drives to the Asmedia controller, and disabled the motherboard Marvell controller in the BIOS: Yeaih, test showed no errors! I copied and moved all day today and had no errors at all. My question is: Could the errors have been caused by the motherboard's Marvell 9128 controller? Or are maybe the SSDs bad? Thank you so much for reading all of this! Apologies for the wall of text.






