




.jpg.9e9c7c7e9eb1460f4e66393ad5c55d03.jpg)
campfred
Members
-
Joined
-
Last visited
-
Thank you for the pointer! It looks like it redone the log on the f.s. and it's mounting properly, now! I'll wait 'till the end of the week to see if something comes up and the array locks up the drive again. If everything's fine by the weekend, I'll mark the thread as solved. Command output for anyone who'd be interested or are in the same situation : root@Alfred:~# xfs_repair /dev/md3 -Lv Phase 1 - find and verify superblock... - block cache size set to 1040488 entries Phase 2 - using internal log - zero log... zero_log: head block 5123 tail block 5119 ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... agi_freecount 128, counted 105 in ag 9 agi_freecount 128, counted 105 in ag 9 finobt agi_freecount 63, counted 61 in ag 10 agi_freecount 63, counted 61 in ag 10 finobt sb_fdblocks 331469875, counted 345095662 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 imap claims in-use inode 6443330471 is free, correcting imap imap claims in-use inode 6443330472 is free, correcting imap imap claims in-use inode 6443330473 is free, correcting imap imap claims in-use inode 6443330474 is free, correcting imap - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 3 - agno = 6 - agno = 1 - agno = 7 - agno = 5 - agno = 4 - agno = 8 - agno = 9 - agno = 10 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - traversal finished ... - moving disconnected inodes to lost+found ... disconnected dir inode 10856320197, moving to lost+found disconnected dir inode 21596214240, moving to lost+found Phase 7 - verify and correct link counts... resetting inode 1181372 nlinks from 3 to 5 Maximum metadata LSN (11:7988) is ahead of log (1:2). Format log to cycle 14. XFS_REPAIR Summary Tue Jul 13 09:33:48 2021 Phase Start End Duration Phase 1: 07/13 09:31:14 07/13 09:31:14 Phase 2: 07/13 09:31:14 07/13 09:31:46 32 seconds Phase 3: 07/13 09:31:46 07/13 09:31:58 12 seconds Phase 4: 07/13 09:31:58 07/13 09:31:58 Phase 5: 07/13 09:31:58 07/13 09:31:59 1 second Phase 6: 07/13 09:31:59 07/13 09:32:05 6 seconds Phase 7: 07/13 09:32:05 07/13 09:32:05 Total run time: 51 seconds done root@Alfred:~#
-
Hello everyone! I would like having some assistance with a drive suffering data corruption. I noticed about it not because of a notification but rather because I wasn't able to write to Array powered shares (Cache-only ones were working fine). So, I went to check on the syslog and noticed this : Jul 11 15:45:02 Alfred kernel: XFS (md3): Corruption detected! Free inode 0x1800d6ba7 not marked free! (mode 0x41ed) Jul 11 15:45:02 Alfred kernel: XFS (md3): Internal error xfs_trans_cancel at line 954 of file fs/xfs/xfs_trans.c. Caller xfs_create+0x280/0x2ea [xfs] Jul 11 15:45:02 Alfred kernel: CPU: 0 PID: 32201 Comm: shfs Tainted: P U O 5.10.28-Unraid #1 Jul 11 15:45:02 Alfred kernel: Hardware name: ASUS All Series/Z87-C, BIOS 2103 08/15/2014 Jul 11 15:45:02 Alfred kernel: Call Trace: Jul 11 15:45:02 Alfred kernel: dump_stack+0x6b/0x83 Jul 11 15:45:02 Alfred kernel: xfs_trans_cancel+0x52/0xc9 [xfs] Jul 11 15:45:02 Alfred kernel: xfs_create+0x280/0x2ea [xfs] Jul 11 15:45:02 Alfred kernel: xfs_generic_create+0xc9/0x1ed [xfs] Jul 11 15:45:02 Alfred kernel: vfs_mkdir+0x55/0x77 Jul 11 15:45:02 Alfred kernel: do_mkdirat+0x7a/0xc7 Jul 11 15:45:02 Alfred kernel: do_syscall_64+0x5d/0x6a Jul 11 15:45:02 Alfred kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9 Jul 11 15:45:02 Alfred kernel: RIP: 0033:0x14d104ab8467 Jul 11 15:45:02 Alfred kernel: Code: 1f 40 00 48 8b 05 29 8a 0d 00 64 c7 00 5f 00 00 00 b8 ff ff ff ff c3 66 2e 0f 1f 84 00 00 00 00 00 66 90 b8 53 00 00 00 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 8b 0d f9 89 0d 00 f7 d8 64 89 01 48 Jul 11 15:45:02 Alfred kernel: RSP: 002b:000014d0fdc18bb8 EFLAGS: 00000206 ORIG_RAX: 0000000000000053 Jul 11 15:45:02 Alfred kernel: RAX: ffffffffffffffda RBX: 000014d0e8083cc0 RCX: 000014d104ab8467 Jul 11 15:45:02 Alfred kernel: RDX: 00000000000001c0 RSI: 00000000000001c0 RDI: 000014d0e807aae0 Jul 11 15:45:02 Alfred kernel: RBP: 000014d0fdc18bf0 R08: 000014d0e8561820 R09: 0065766973756c63 Jul 11 15:45:02 Alfred kernel: R10: 000014d0e807fe80 R11: 0000000000000206 R12: 0000000000000000 Jul 11 15:45:02 Alfred kernel: R13: 000000000000a67d R14: 000014d0e8087040 R15: 00000000000001c0 Jul 11 15:45:02 Alfred kernel: XFS (md3): xfs_do_force_shutdown(0x8) called from line 955 of file fs/xfs/xfs_trans.c. Return address = 00000000a737bb2b Jul 11 15:45:02 Alfred kernel: XFS (md3): Corruption of in-memory data detected. Shutting down filesystem Jul 11 15:45:02 Alfred kernel: XFS (md3): Please unmount the filesystem and rectify the problem(s) What I understood from this message : Data corruption has been found on Drive 3 (md3) and unRAID is stopping all I/O transfers to the Array and requesting that I unmount and check the drive. Fine, I'm gonna follow the « Check Disk Filesystems » guide in the wiki and I should be good. Except, I ran the check in verbose with no modify (so, with « xfs_repair -nv /dev/md3 ») and I don't understand what's the error? Here's the output from it: Phase 1 - find and verify superblock... - block cache size set to 1040488 entries Phase 2 - using internal log - zero log... zero_log: head block 5123 tail block 5119 ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... agi_freecount 128, counted 105 in ag 9 agi_freecount 128, counted 105 in ag 9 finobt agi_freecount 63, counted 61 in ag 10 agi_freecount 63, counted 61 in ag 10 finobt sb_fdblocks 331469875, counted 345095662 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 imap claims in-use inode 6443330471 is free, correcting imap imap claims in-use inode 6443330472 is free, correcting imap imap claims in-use inode 6443330473 is free, correcting imap imap claims in-use inode 6443330474 is free, correcting imap - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 5 - agno = 3 - agno = 7 - agno = 6 - agno = 4 - agno = 8 - agno = 9 - agno = 10 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - traversal finished ... - moving disconnected inodes to lost+found ... disconnected dir inode 10856320197, would move to lost+found disconnected dir inode 21596214240, would move to lost+found Phase 7 - verify link counts... Maximum metadata LSN (11:7968) is ahead of log (11:5123). Would format log to cycle 14. No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Sun Jul 11 17:33:36 2021 Phase Start End Duration Phase 1: 07/11 17:33:18 07/11 17:33:18 Phase 2: 07/11 17:33:18 07/11 17:33:19 1 second Phase 3: 07/11 17:33:19 07/11 17:33:31 12 seconds Phase 4: 07/11 17:33:31 07/11 17:33:31 Phase 5: Skipped Phase 6: 07/11 17:33:31 07/11 17:33:36 5 seconds Phase 7: 07/11 17:33:36 07/11 17:33:36 Total run time: 18 seconds Okay, there's an alert for the FS' log telling me to mount the disk to resolve the log inconsistencies. ...Except after I did mount the Array back, I went back to square one with my array being I/O blocked because of corruption. So, I went back in Maintenance mode and tried to do the repair anyway to see if it's gonna attempt to do something with the log but nope, it asks me to mount the drive first. Phase 1 - find and verify superblock... - block cache size set to 1040488 entries Phase 2 - using internal log - zero log... zero_log: head block 5123 tail block 5119 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. I did power down the server and go replace the power and data cables for all my drives following that just in case it would be a cable fail causing this and there is no bend or kinks on them. 'Still getting that state, though. Now, I don't know what else I can do for resolving this issue. Does someone have an idea or a pointer that could potentially help me solve this? Of course, diagnostics data is attached to this post. Thank you very much for taking your time to read me! alfred-diagnostics-20210711-1735.zip
-
The config looked good on my end with my latest changes. But something escaped me and I noticed about it only later...more after the next quote. With your steps, I've been able to figure a few things I forgot about when trying to run this. Database names are always in lowercase. Dunno why I wrote it in uppercase. Creating the database reminded me of this after the database was listed as « netbox » even though I supplied « Netbox ». Oops. That resolved the Python exceptions I was getting. After that, I was still getting the 400 HTTP error. At this point, I was thinking maybe it was borked and so, I removed the container and repulled it with all the right environment variables. Once that was done, I basically only had to correct the deprecated Redis command and I was greeted with Netbox' web panel! (Hooray!) I'll check if there's a way I can contribute to the container for correcting the deprecated Redis command and the database name that could be automatically converted in lowercase before being written to the config. Just in case another noob like me does that mistake too. Especially since the library/postgre container does that by itself already (so, the noob me never noticed he had put capitalized letters upon runtime because hey, everything's fine on the database's creation part still). Anyway, thank you lots for these helpful details!
-
Alright. 'Done it but I still get the exceptions and it's still looking for the « redis » hostname... Commands : docker run -d --name='Postgres11Netbox' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'POSTGRES_PASSWORD'='(ThePassword)' -e 'POSTGRES_USER'='postgres' -e 'POSTGRES_DB'='Netbox' -p '5432:5432/tcp' -v '/mnt/user/Applications/Postgres11':'/var/lib/postgresql/data':'rw' 'postgres:11' docker run -d --name='redis' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'ALLOW_EMPTY_PASSWORD'='no' -e 'REDIS_PASSWORD'='(ThePassword)' -e 'REDIS_AOF_ENABLED'='yes' -p '6379:6379/tcp' -v '/mnt/user/Applications/redis/data':'/bitnami/redis/data':'rw' 'bitnami/redis:latest' docker run -d --name='netbox' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'PUID'='99' -e 'PGID'='100' -e 'SUPERUSER_EMAIL'='admin' -e 'SUPERUSER_PASSWORD'='(ThePassword)' -e 'ALLOWED_HOST'='' -e 'DB_NAME'='Netbox' -e 'DB_USER'='postgres' -e 'DB_PASSWORD'='(ThePassword)' -e 'DB_HOST'='192.168.10.10' -e 'DB_PORT'='5432' -e 'REDIS_HOST'='192.168.10.10' -e 'REDIS_PORT'='6379' -e 'REDIS_PASSWORD'='(ThePassword)' -p '8000:8000/tcp' -v '/mnt/user/Applications/netbox':'/config':'rw' 'linuxserver/netbox' Of course, you'll find the container's log attached. netbox.log
-
Sorry for missing out on that. I never checked on that window that appears. I always just ran it and went to other things while it was working on the server and come back on the web panel to check on things through the logs. Also, sorry for missing the sticky posts. My screen reader just goes past them and I have no idea as to why it skips these items in the posts table, so I never have been aware they were there. My apologies. Here are the command equivalent to the deployment of the containers so far! docker run -d --name='Postgres11' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'POSTGRES_PASSWORD'='//REDACTED//' -e 'POSTGRES_USER'='postgres' -e 'POSTGRES_DB'='postgres' -p '5432:5432/tcp' -v '/mnt/user/Applications/Postgres11':'/var/lib/postgresql/data':'rw' 'postgres:11' f8adc057221fdd1ff0b1a101899abfd73a3b956894a4057219a7184a58597fc4 docker run -d --name='redis' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'ALLOW_EMPTY_PASSWORD'='no' -e 'REDIS_PASSWORD'='//REDACTED//' -e 'REDIS_AOF_ENABLED'='yes' -p '6379:6379/tcp' -v '/mnt/user/Applications/redis/data':'/bitnami/redis/data':'rw' 'bitnami/redis:latest' ba73d23de343538c1b5cd900c98e254af20bdb0dfef2d177175960b46dcb6c95 docker run -d --name='netbox' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'PUID'='99' -e 'PGID'='100' -e 'SUPERUSER_EMAIL'='admin' -e 'SUPERUSER_PASSWORD'='//REDACTED//' -e 'ALLOWED_HOST'='' -e 'DB_NAME'='' -e 'DB_USER'='postgres' -e 'DB_PASSWORD'='//REDACTED//' -e 'DB_HOST'='192.168.10.10' -e 'DB_PORT'='' -e 'REDIS_HOST'='192.168.10.10' -e 'REDIS_PORT'='' -e 'REDIS_PASSWORD'='//REDACTED//' -p '8000:8000/tcp' -v '/mnt/user/Applications/netbox':'/config':'rw' 'linuxserver/netbox' 7f755b848a9c09526dce30a1b5673e22971a9b963d7b7c10943f533d06a707fc
-
While my searches on doing that didn't give me a meaningful answer so far, I although found the location of the configuration files (or user template files actually). So, have attached the current state of the container template for Netbox where I've put in the host's IP address instead as suggested and the log from the container where it is still looking for a « redis » hostname instead. Oh, and sorry for forgetting to respond about the ports, I do use the standard ports. I can give the container template files for both of them too if you want to check them out. my-netbox.xml netbox.log
-
Sorry about the assle with the screenshots. I didn't know it was possible to extract docker run commands from the configuration done inside the unRAID interface...but I can't find how to do that. How is it done?
-
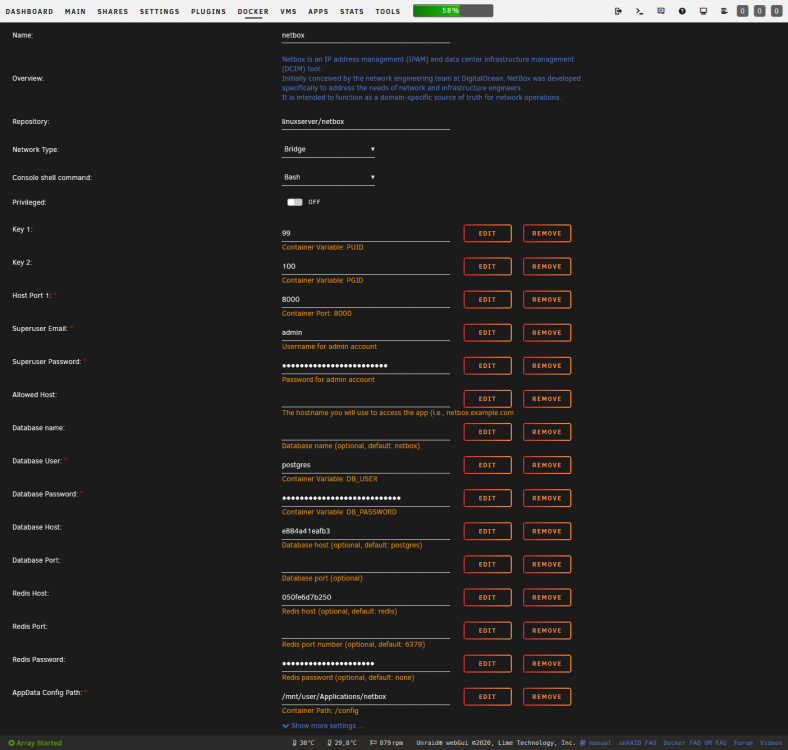
Well, that's weird because that's exactly what I've done : Supplying the actual hostname (or even the IP address as I mentioned in your quote). 🤔 Maybe you missed part of my message because I already assessed the IP possibility. But just for re-checking what I said previously, I entered the IP address instead and I got exactly the same result where the container still looks for something else than what I said. You will find attached a screenshot of the configuration using IP addresses instead and also another copy of the container's logs following that configuration using IP addresses where it still wants to talk to « redis » instead of what I actually supplied (172.17.0.14). Also, for the sake of answering you correctly, what you see in the screenshot that I put as the Redis server and the PostgreSQL server are the identifiers of the two containers respectively. They show up as that hostname when checked from inside the containers. Attached is a GIF that shows how I get them from the consoles. netbox.log
-
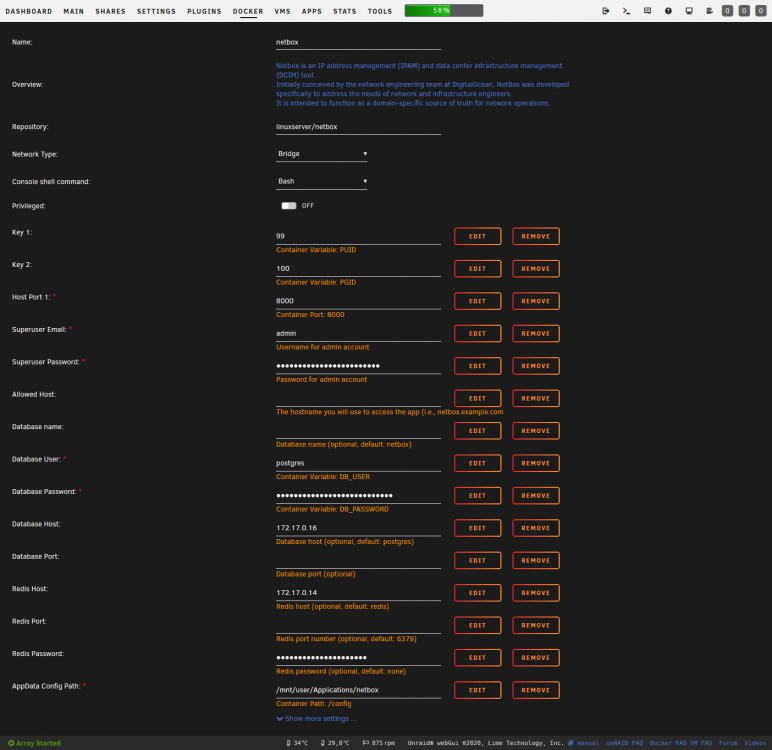
I'm also having that issue despite having a PostgreSQL and a Redis server container ready and I'm not sure how to resolve it. Although, the one thing that confuses me is how it's trying to connect to a server with the hostname « redis » while I actually supplied a REDIS_HOST that's way different than this. I also tried with an IP address but it's still looking for « redis »... It's also throwing Python exceptions at me in the logs which is probably part of the cause of the container not functioning but I have a hard time understanding them. So, I'd like some help on that too, please. 😅 Please find the current state of the Netbox container log and a screenshot of the current configuration for it attached. netbox.log
.thumb.jpg.6f5e1819db3929ac4d97a317ad4576b8.jpg)


