tjiddy
Members
-
Joined
-
Last visited
-
check completed (pretty quickly). Output attached. disk_check_output.txt
-
I have had nothing but trouble for a few weeks now. After finally resolving this mess, 2 days ago, another disk appeared to have died (diagnostics here:jabba-diagnostics-20231111-1557.zip). I replaced disk 1, rebuilt everything. Everything looked great. All bubbles green. no errors in syslog. Then I ran the mover, and started seeing errors. Nov 13 09:26:33 JABBA kernel: XFS (md13p1): Metadata CRC error detected at xfs_allocbt_read_verify+0x12/0x5a [xfs], xfs_bnobt block 0x26b8 Nov 13 09:26:33 JABBA kernel: XFS (md13p1): Unmount and run xfs_repair Nov 13 09:26:33 JABBA kernel: XFS (md13p1): First 128 bytes of corrupted metadata buffer: Here are today's diagnostics: jabba-diagnostics-20231113-0935.zip 1) From my first diagnostics, is there a way to tell what happened to disk1? 2) Could the disk1 which died have written corrupted data to parity, so when I rebuilt it back on a new disk, It is now corrupt? With SO many disk related problems in the past couple week, is it valid to think the disks might not be at fault, but the cables/controller card are dying?
-
I ran an extended SMART test. Completed: read failure I'll attach the report WDC_WD60EFRX-68L0BN1_WD-WX31D17DJK65-20231030-1343.txt
-
Thank you. How could this have been avoided? I thought the whole point of parity was to be able to rebuild the contents of failed drives?
-
Array is started. disk 22 only contains a lost+found directory with what looks like most the old contents of the drive spread throughout numeric folders. I've noted the filenames in case they need to be replaced. Does this mean the data is lost, or will parity be able to rebuild this disk once replaced? Thank you so much for getting me this far! What would be my next step?
-
Sorry to be overly paranoid, but it's still ok to start with with this message?

-
Done. Results attached. checkfs_output.txt
-
Phase 1 - find and verify superblock... - block cache size set to 717200 entries sb root inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 128 resetting superblock root inode pointer to 128 sb realtime bitmap inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 129 resetting superblock realtime bitmap inode pointer to 129 sb realtime summary inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 130 resetting superblock realtime summary inode pointer to 130 Phase 2 - using internal log - zero log... zero_log: head block 114006 tail block 114002 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
-
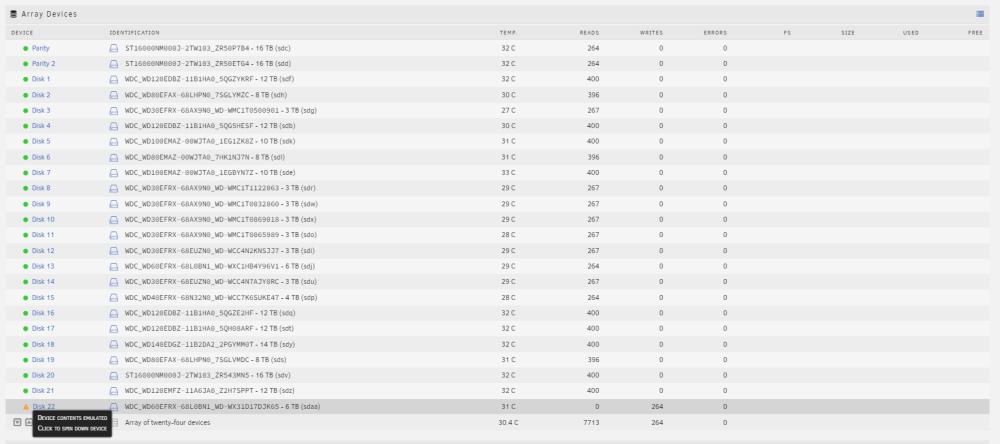
Thank you for all of your help so far. It's really appreciated. I'm a little confused how to check the filesystem for disk 22. This is what my UI is showing when the array is started in maintenance mode. When I go into the drive settings, I don't even see the check filesystem section, even though I'm in maintenance mode. (I do see it for the other drives). Do you want me to rebuild the drive from parity, then check the filesystem?
-
I must have missed a step. disk22 is currently emulated. That is the drive which was making a bad sound, had smart errors, and when I tried to attach the drive it showed up as "unmountable: unsupported of no filesystem". Now when I set the device into disk 22 the slot It warns me "All existing data on this device will be OVERWRITTEN when array is Started" Currently checking the filesystem on that device isn't possible because Unraid doesn't recognize the filesystem on the device. (Looks like it hasn't completely died yet, maybe just corrupted to the point where the fs is unrecognized due the controller errors/hard shutdown? ) Should I re-add it, and let Unraid rebuild it from parity before checking the filesystem? If so, since I'm planning on replacing that drive, would it be better to put the replacement in, let it rebuild, then check the fs?
-
Thanks! I followed your steps and the parity drives are now enabled. The missing disk is being emulated. Here are the new diagnostics. Just curious, why start in maintenance mode the first time?? jabba-diagnostics-20231029-0935.zip
-
Last night I noticed that my shares were not responding. After looking into it, all the drives attached to one of my LSI controllers were having issues. My log partition was full due to samba and subsequently syslog errors, and I was unable to generate a diagnostics. Any command which accessed the filesystem would just hang. I shut down the system (after being unable to do it gracefully after trying multiple ways, I did the power button hold of shame. I reseated both of my controller cards, and restarted. As the system was spinning back up, I heard the telltale clicking sound of a dead 6TB drive. Once the system rebooted, I was greeted with my 2 parity drives disabled, and another "unmountable: unsupported of no filesystem" drive. The drive which it thought needed to be formatted was indeed the 6TB drive making the dying sounds. I ran an extended smart test on both parity drives and they turned out OK. A SMART test on the questionable 6TB drive resulted in an error. I do have a replacement for the 6TB in hand. Here is my dilemma. The common fix for disabled parity drives is to remove/readd/rebuild parity. I don't want to do rebuild parity because I have a bad drive I need to rebuild. Any thoughts on: Should I just assume that the controller card unseated itself? Are there any telltale signs of a failing card? I've been running Unraid for over 13 years and have never had a card unseat itself like this. It seems like a pretty big coincidence that I had a drive die at the same time as the controller malfunction. One couldn't lead to the other would it? Is there a way to tell why my 2 parity drives were disabled (and only those 2 drives)? I know that might be tough/impossible w/o the logs from before my restart Is it safe to / is there a way to re-enable my 2 parity drives without having to rebuild what is on them, so I can rebuild the dead drive? If my best bet is to abandon the dead drive, rebuild parity without it, then replace it, is there a way to see at least the filenames which were on it so I know what I need to replace? I know about the LSI/Ironwolf drive disabling issue, but my 2 parity drives are Exos, and my card is a SAS3 card, which I believe doesn't suffer from the issue, correct? What would be the best way to make sure this doesn't happen again? Could I have gotten an alert as soon as the problem started? I'll attach my diagnostics. Unfortunately it's from after the system reboot as they wouldn't generate before (they hung trying to query the drive controller), but should include the extended SMART test of the parity drives. Thanks in advance! jabba-diagnostics-20231028-2240.zip
-
My system was rebuilding a drive today when I noticed my syslog was full. When I looked at it, I saw a bunch of errors saying REISERFS error (device md1): vs-5150 search_by_key: invalid format found in block 1001443464. Fsck? I stopped the rebuild, started in maintenance mode and ran reiserfsck --check /dev/md1. The final output said 16 found corruptions can be fixed only when running with --rebuild-tree I have 2 questions. which disk is this? Does md1 map to sda? If so, thats my flash drive, which is definitely not formatted as REISERFS. If it's sdb, then it's one of my two parity drives. That sounds scary. The wiki says to be very careful with this command and I was wondering if you guys thought it would be safe/recommended to run? I'll attach the full output from the reiserfsck as well as the diagnostics zip. Thanks in advance! jabba-diagnostics-20221118-1441.zip reiserfsck_output.txt
-
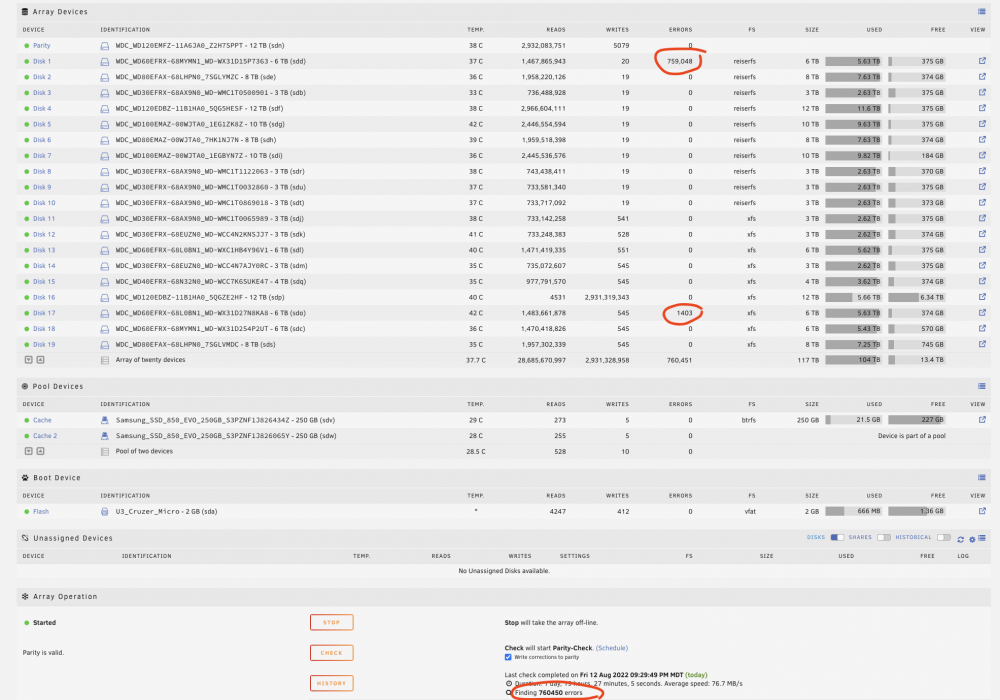
I had a drive go kaput. I followed the normal steps for replacing a drive, but during the data sync when it was rebuilding the new drive, 2 other drives showed errors. I did cancel the rebuild and tried reseting and replacing the cables on the drives in question, but when I initiated the rebuild again, the same 2 drives had errors. The rebuild completed, but I'm curious what the errors mean, does that mean my disk was rebuilt with errors on it? Is my parity drive now hosed? Since changing reseating/replacing the cables didn't fix the problem, am I looking at 2 more failing drives? I've attached my diagnostics zip file. Below is what my main page looks like after the rebuild completed. Thanks in advance for any help! jabba-diagnostics-20220812-2227.zip