




Neejrow
Members
-
Joined
-
Last visited
Everything posted by Neejrow
-
The errors have not increased in unRAID main tab, and no further warnings. I also done a comparison between a new SMART report and one from hours ago and the uncorrectable errors and reallocated sectors have not increased either. I am now running the Extended smart self-test again. And have re-enabled Mover to run again overnight, and it should write data to that drive at some point so will see if the errors increase and will report back tomorrow. Thanks for all the help so far, I appreciate it!
-
I don't know if this is useful or not, but I'll post the disk log from unRAID too. Unsure if this is available in the diagnostics. text error warn system array login Feb 2 15:30:46 Tower kernel: ata4: SATA max UDMA/133 abar m131072@0xfc580000 port 0xfc580280 irq 85 Feb 2 15:30:46 Tower kernel: ata4: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Feb 2 15:30:46 Tower kernel: ata4.00: ATA-11: ST8000VN004-2M2101, SC60, max UDMA/133 Feb 2 15:30:46 Tower kernel: ata4.00: 15628053168 sectors, multi 16: LBA48 NCQ (depth 32), AA Feb 2 15:30:46 Tower kernel: ata4.00: Features: NCQ-sndrcv Feb 2 15:30:46 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:30:46 Tower kernel: sd 4:0:0:0: [sdd] 15628053168 512-byte logical blocks: (8.00 TB/7.28 TiB) Feb 2 15:30:46 Tower kernel: sd 4:0:0:0: [sdd] 4096-byte physical blocks Feb 2 15:30:46 Tower kernel: sd 4:0:0:0: [sdd] Write Protect is off Feb 2 15:30:46 Tower kernel: sd 4:0:0:0: [sdd] Mode Sense: 00 3a 00 00 Feb 2 15:30:46 Tower kernel: sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Feb 2 15:30:46 Tower kernel: sdd: sdd1 Feb 2 15:30:46 Tower kernel: sd 4:0:0:0: [sdd] Attached SCSI disk Feb 2 15:31:01 Tower wsdd2[1463]: starting. Feb 2 15:32:00 Tower emhttpd: ST8000VN004-2M2101_WKD3HD7N (sdd) 512 15628053168 Feb 2 15:32:00 Tower kernel: mdcmd (6): import 5 sdd 64 7814026532 0 ST8000VN004-2M2101_WKD3HD7N Feb 2 15:32:00 Tower kernel: md: import disk5: (sdd) ST8000VN004-2M2101_WKD3HD7N size: 7814026532 Feb 2 15:32:00 Tower emhttpd: read SMART /dev/sdd Feb 2 15:32:00 Tower wsdd2[1463]: 'Terminated' signal received. Feb 2 15:32:00 Tower wsdd2[1463]: terminating. Feb 2 15:32:02 Tower root: /usr/sbin/wsdd2 -d Feb 2 15:32:02 Tower wsdd2[4129]: starting. Feb 2 15:33:31 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x200000 SErr 0x0 action 0x0 Feb 2 15:33:31 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:31 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:31 Tower kernel: ata4.00: cmd 60/08:a8:80:64:09/00:00:00:02:00/40 tag 21 ncq dma 4096 in Feb 2 15:33:31 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:31 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:31 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:31 Tower kernel: sd 4:0:0:0: [sdd] tag#21 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:33:31 Tower kernel: sd 4:0:0:0: [sdd] tag#21 Sense Key : 0x3 [current] Feb 2 15:33:31 Tower kernel: sd 4:0:0:0: [sdd] tag#21 ASC=0x11 ASCQ=0x4 Feb 2 15:33:31 Tower kernel: sd 4:0:0:0: [sdd] tag#21 CDB: opcode=0x88 88 00 00 00 00 02 00 09 64 80 00 00 00 08 00 00 Feb 2 15:33:31 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590550144 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Feb 2 15:33:31 Tower kernel: ata4: EH complete Feb 2 15:33:34 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x4 SErr 0x0 action 0x0 Feb 2 15:33:34 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:34 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:34 Tower kernel: ata4.00: cmd 60/08:10:88:5c:09/00:00:00:02:00/40 tag 2 ncq dma 4096 in Feb 2 15:33:34 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:34 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:34 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:34 Tower kernel: sd 4:0:0:0: [sdd] tag#2 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:33:34 Tower kernel: sd 4:0:0:0: [sdd] tag#2 Sense Key : 0x3 [current] Feb 2 15:33:34 Tower kernel: sd 4:0:0:0: [sdd] tag#2 ASC=0x11 ASCQ=0x4 Feb 2 15:33:34 Tower kernel: sd 4:0:0:0: [sdd] tag#2 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5c 88 00 00 00 08 00 00 Feb 2 15:33:34 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590548104 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Feb 2 15:33:34 Tower kernel: ata4: EH complete Feb 2 15:33:37 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x10 SErr 0x0 action 0x0 Feb 2 15:33:37 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:37 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:37 Tower kernel: ata4.00: cmd 60/08:20:90:58:09/00:00:00:02:00/40 tag 4 ncq dma 4096 in Feb 2 15:33:37 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:37 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:37 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:37 Tower kernel: sd 4:0:0:0: [sdd] tag#4 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:33:37 Tower kernel: sd 4:0:0:0: [sdd] tag#4 Sense Key : 0x3 [current] Feb 2 15:33:37 Tower kernel: sd 4:0:0:0: [sdd] tag#4 ASC=0x11 ASCQ=0x4 Feb 2 15:33:37 Tower kernel: sd 4:0:0:0: [sdd] tag#4 CDB: opcode=0x88 88 00 00 00 00 02 00 09 58 90 00 00 00 08 00 00 Feb 2 15:33:37 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590547088 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Feb 2 15:33:37 Tower kernel: ata4: EH complete Feb 2 15:33:41 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x100 SErr 0x0 action 0x0 Feb 2 15:33:41 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:41 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:41 Tower kernel: ata4.00: cmd 60/08:40:10:58:09/00:00:00:02:00/40 tag 8 ncq dma 4096 in Feb 2 15:33:41 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:41 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:41 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:41 Tower kernel: sd 4:0:0:0: [sdd] tag#8 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:33:41 Tower kernel: sd 4:0:0:0: [sdd] tag#8 Sense Key : 0x3 [current] Feb 2 15:33:41 Tower kernel: sd 4:0:0:0: [sdd] tag#8 ASC=0x11 ASCQ=0x4 Feb 2 15:33:41 Tower kernel: sd 4:0:0:0: [sdd] tag#8 CDB: opcode=0x88 88 00 00 00 00 02 00 09 58 10 00 00 00 08 00 00 Feb 2 15:33:41 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590546960 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Feb 2 15:33:41 Tower kernel: ata4: EH complete Feb 2 15:33:44 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x800 SErr 0x0 action 0x0 Feb 2 15:33:44 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:44 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:44 Tower kernel: ata4.00: cmd 60/08:58:f0:57:09/00:00:00:02:00/40 tag 11 ncq dma 4096 in Feb 2 15:33:44 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:44 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:44 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:44 Tower kernel: sd 4:0:0:0: [sdd] tag#11 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:33:44 Tower kernel: sd 4:0:0:0: [sdd] tag#11 Sense Key : 0x3 [current] Feb 2 15:33:44 Tower kernel: sd 4:0:0:0: [sdd] tag#11 ASC=0x11 ASCQ=0x4 Feb 2 15:33:44 Tower kernel: sd 4:0:0:0: [sdd] tag#11 CDB: opcode=0x88 88 00 00 00 00 02 00 09 57 f0 00 00 00 08 00 00 Feb 2 15:33:44 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590546928 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Feb 2 15:33:44 Tower kernel: ata4: EH complete Feb 2 15:33:48 Tower kernel: ata4.00: exception Emask 0x0 SAct 0xf400 SErr 0x0 action 0x0 Feb 2 15:33:48 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:48 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:48 Tower kernel: ata4.00: cmd 60/18:50:f8:57:09/00:00:00:02:00/40 tag 10 ncq dma 12288 in Feb 2 15:33:48 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:48 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:48 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:48 Tower kernel: sd 4:0:0:0: [sdd] tag#10 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:33:48 Tower kernel: sd 4:0:0:0: [sdd] tag#10 Sense Key : 0x3 [current] Feb 2 15:33:48 Tower kernel: sd 4:0:0:0: [sdd] tag#10 ASC=0x11 ASCQ=0x4 Feb 2 15:33:48 Tower kernel: sd 4:0:0:0: [sdd] tag#10 CDB: opcode=0x88 88 00 00 00 00 02 00 09 57 f8 00 00 00 18 00 00 Feb 2 15:33:48 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590546936 op 0x0:(READ) flags 0x0 phys_seg 3 prio class 0 Feb 2 15:33:48 Tower kernel: ata4: EH complete Feb 2 15:33:51 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x1e000 SErr 0x0 action 0x0 Feb 2 15:33:51 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:51 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:51 Tower kernel: ata4.00: cmd 60/58:68:98:58:09/00:00:00:02:00/40 tag 13 ncq dma 45056 in Feb 2 15:33:51 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:51 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:51 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:51 Tower kernel: sd 4:0:0:0: [sdd] tag#13 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=6s Feb 2 15:33:51 Tower kernel: sd 4:0:0:0: [sdd] tag#13 Sense Key : 0x3 [current] Feb 2 15:33:51 Tower kernel: sd 4:0:0:0: [sdd] tag#13 ASC=0x11 ASCQ=0x4 Feb 2 15:33:51 Tower kernel: sd 4:0:0:0: [sdd] tag#13 CDB: opcode=0x88 88 00 00 00 00 02 00 09 58 98 00 00 00 58 00 00 Feb 2 15:33:51 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590547096 op 0x0:(READ) flags 0x0 phys_seg 11 prio class 0 Feb 2 15:33:51 Tower kernel: ata4: EH complete Feb 2 15:33:54 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x40100 SErr 0x0 action 0x0 Feb 2 15:33:54 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:54 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:54 Tower kernel: ata4.00: cmd 60/78:40:18:58:09/00:00:00:02:00/40 tag 8 ncq dma 61440 in Feb 2 15:33:54 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:54 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:55 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:55 Tower kernel: sd 4:0:0:0: [sdd] tag#8 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=10s Feb 2 15:33:55 Tower kernel: sd 4:0:0:0: [sdd] tag#8 Sense Key : 0x3 [current] Feb 2 15:33:55 Tower kernel: sd 4:0:0:0: [sdd] tag#8 ASC=0x11 ASCQ=0x4 Feb 2 15:33:55 Tower kernel: sd 4:0:0:0: [sdd] tag#8 CDB: opcode=0x88 88 00 00 00 00 02 00 09 58 18 00 00 00 78 00 00 Feb 2 15:33:55 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590546968 op 0x0:(READ) flags 0x0 phys_seg 15 prio class 0 Feb 2 15:33:55 Tower kernel: ata4: EH complete Feb 2 15:33:58 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x100000 SErr 0x0 action 0x0 Feb 2 15:33:58 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:33:58 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:33:58 Tower kernel: ata4.00: cmd 60/00:a0:f0:58:09/01:00:00:02:00/40 tag 20 ncq dma 131072 in Feb 2 15:33:58 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:33:58 Tower kernel: ata4.00: error: { UNC } Feb 2 15:33:58 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:33:58 Tower kernel: sd 4:0:0:0: [sdd] tag#20 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:33:58 Tower kernel: sd 4:0:0:0: [sdd] tag#20 Sense Key : 0x3 [current] Feb 2 15:33:58 Tower kernel: sd 4:0:0:0: [sdd] tag#20 ASC=0x11 ASCQ=0x4 Feb 2 15:33:58 Tower kernel: sd 4:0:0:0: [sdd] tag#20 CDB: opcode=0x88 88 00 00 00 00 02 00 09 58 f0 00 00 01 00 00 00 Feb 2 15:33:58 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590547184 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:33:58 Tower kernel: ata4: EH complete Feb 2 15:34:02 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x800002 SErr 0x0 action 0x0 Feb 2 15:34:02 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:02 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:02 Tower kernel: ata4.00: cmd 60/00:b8:f0:59:09/01:00:00:02:00/40 tag 23 ncq dma 131072 in Feb 2 15:34:02 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:02 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:02 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:02 Tower kernel: sd 4:0:0:0: [sdd] tag#23 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:02 Tower kernel: sd 4:0:0:0: [sdd] tag#23 Sense Key : 0x3 [current] Feb 2 15:34:02 Tower kernel: sd 4:0:0:0: [sdd] tag#23 ASC=0x11 ASCQ=0x4 Feb 2 15:34:02 Tower kernel: sd 4:0:0:0: [sdd] tag#23 CDB: opcode=0x88 88 00 00 00 00 02 00 09 59 f0 00 00 01 00 00 00 Feb 2 15:34:02 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590547440 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:02 Tower kernel: ata4: EH complete Feb 2 15:34:05 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x50000001 SErr 0x0 action 0x0 Feb 2 15:34:05 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:05 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:05 Tower kernel: ata4.00: cmd 60/00:e0:f0:5a:09/01:00:00:02:00/40 tag 28 ncq dma 131072 in Feb 2 15:34:05 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:05 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:05 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:05 Tower kernel: sd 4:0:0:0: [sdd] tag#28 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:05 Tower kernel: sd 4:0:0:0: [sdd] tag#28 Sense Key : 0x3 [current] Feb 2 15:34:05 Tower kernel: sd 4:0:0:0: [sdd] tag#28 ASC=0x11 ASCQ=0x4 Feb 2 15:34:05 Tower kernel: sd 4:0:0:0: [sdd] tag#28 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5a f0 00 00 01 00 00 00 Feb 2 15:34:05 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590547696 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:05 Tower kernel: ata4: EH complete Feb 2 15:34:08 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x1d SErr 0x0 action 0x0 Feb 2 15:34:08 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:08 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:08 Tower kernel: ata4.00: cmd 60/98:00:f0:5b:09/00:00:00:02:00/40 tag 0 ncq dma 77824 in Feb 2 15:34:08 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:08 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:08 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:08 Tower kernel: sd 4:0:0:0: [sdd] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:08 Tower kernel: sd 4:0:0:0: [sdd] tag#0 Sense Key : 0x3 [current] Feb 2 15:34:08 Tower kernel: sd 4:0:0:0: [sdd] tag#0 ASC=0x11 ASCQ=0x4 Feb 2 15:34:08 Tower kernel: sd 4:0:0:0: [sdd] tag#0 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5b f0 00 00 00 98 00 00 Feb 2 15:34:08 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590547952 op 0x0:(READ) flags 0x0 phys_seg 19 prio class 0 Feb 2 15:34:08 Tower kernel: ata4: EH complete Feb 2 15:34:12 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x240 SErr 0x0 action 0x0 Feb 2 15:34:12 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:12 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:12 Tower kernel: ata4.00: cmd 60/60:30:90:5c:09/00:00:00:02:00/40 tag 6 ncq dma 49152 in Feb 2 15:34:12 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:12 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:12 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:12 Tower kernel: sd 4:0:0:0: [sdd] tag#6 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=6s Feb 2 15:34:12 Tower kernel: sd 4:0:0:0: [sdd] tag#6 Sense Key : 0x3 [current] Feb 2 15:34:12 Tower kernel: sd 4:0:0:0: [sdd] tag#6 ASC=0x11 ASCQ=0x4 Feb 2 15:34:12 Tower kernel: sd 4:0:0:0: [sdd] tag#6 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5c 90 00 00 00 60 00 00 Feb 2 15:34:12 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590548112 op 0x0:(READ) flags 0x0 phys_seg 12 prio class 0 Feb 2 15:34:12 Tower kernel: ata4: EH complete Feb 2 15:34:15 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x2000 SErr 0x0 action 0x0 Feb 2 15:34:15 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:15 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:15 Tower kernel: ata4.00: cmd 60/00:68:f0:5c:09/01:00:00:02:00/40 tag 13 ncq dma 131072 in Feb 2 15:34:15 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:15 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:15 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:15 Tower kernel: sd 4:0:0:0: [sdd] tag#13 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:15 Tower kernel: sd 4:0:0:0: [sdd] tag#13 Sense Key : 0x3 [current] Feb 2 15:34:15 Tower kernel: sd 4:0:0:0: [sdd] tag#13 ASC=0x11 ASCQ=0x4 Feb 2 15:34:15 Tower kernel: sd 4:0:0:0: [sdd] tag#13 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5c f0 00 00 01 00 00 00 Feb 2 15:34:15 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590548208 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:15 Tower kernel: ata4: EH complete Feb 2 15:34:19 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x40 SErr 0x0 action 0x0 Feb 2 15:34:19 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:19 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:19 Tower kernel: ata4.00: cmd 60/00:30:f0:5d:09/01:00:00:02:00/40 tag 6 ncq dma 131072 in Feb 2 15:34:19 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:19 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:19 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:19 Tower kernel: sd 4:0:0:0: [sdd] tag#6 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:19 Tower kernel: sd 4:0:0:0: [sdd] tag#6 Sense Key : 0x3 [current] Feb 2 15:34:19 Tower kernel: sd 4:0:0:0: [sdd] tag#6 ASC=0x11 ASCQ=0x4 Feb 2 15:34:19 Tower kernel: sd 4:0:0:0: [sdd] tag#6 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5d f0 00 00 01 00 00 00 Feb 2 15:34:19 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590548464 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:19 Tower kernel: ata4: EH complete Feb 2 15:34:22 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x400 SErr 0x0 action 0x0 Feb 2 15:34:22 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:22 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:22 Tower kernel: ata4.00: cmd 60/00:50:f0:5e:09/01:00:00:02:00/40 tag 10 ncq dma 131072 in Feb 2 15:34:22 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:22 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:22 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:22 Tower kernel: sd 4:0:0:0: [sdd] tag#10 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:22 Tower kernel: sd 4:0:0:0: [sdd] tag#10 Sense Key : 0x3 [current] Feb 2 15:34:22 Tower kernel: sd 4:0:0:0: [sdd] tag#10 ASC=0x11 ASCQ=0x4 Feb 2 15:34:22 Tower kernel: sd 4:0:0:0: [sdd] tag#10 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5e f0 00 00 01 00 00 00 Feb 2 15:34:22 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590548720 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:22 Tower kernel: ata4: EH complete Feb 2 15:34:25 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x2000 SErr 0x0 action 0x0 Feb 2 15:34:25 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:25 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:25 Tower kernel: ata4.00: cmd 60/00:68:f0:5f:09/01:00:00:02:00/40 tag 13 ncq dma 131072 in Feb 2 15:34:25 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:25 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:25 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:25 Tower kernel: sd 4:0:0:0: [sdd] tag#13 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:25 Tower kernel: sd 4:0:0:0: [sdd] tag#13 Sense Key : 0x3 [current] Feb 2 15:34:25 Tower kernel: sd 4:0:0:0: [sdd] tag#13 ASC=0x11 ASCQ=0x4 Feb 2 15:34:25 Tower kernel: sd 4:0:0:0: [sdd] tag#13 CDB: opcode=0x88 88 00 00 00 00 02 00 09 5f f0 00 00 01 00 00 00 Feb 2 15:34:25 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590548976 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:25 Tower kernel: ata4: EH complete Feb 2 15:34:29 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x10000 SErr 0x0 action 0x0 Feb 2 15:34:29 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:29 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:29 Tower kernel: ata4.00: cmd 60/00:80:f0:60:09/01:00:00:02:00/40 tag 16 ncq dma 131072 in Feb 2 15:34:29 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:29 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:29 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:29 Tower kernel: sd 4:0:0:0: [sdd] tag#16 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:29 Tower kernel: sd 4:0:0:0: [sdd] tag#16 Sense Key : 0x3 [current] Feb 2 15:34:29 Tower kernel: sd 4:0:0:0: [sdd] tag#16 ASC=0x11 ASCQ=0x4 Feb 2 15:34:29 Tower kernel: sd 4:0:0:0: [sdd] tag#16 CDB: opcode=0x88 88 00 00 00 00 02 00 09 60 f0 00 00 01 00 00 00 Feb 2 15:34:29 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590549232 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:29 Tower kernel: ata4: EH complete Feb 2 15:34:32 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x80000 SErr 0x0 action 0x0 Feb 2 15:34:32 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:32 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:32 Tower kernel: ata4.00: cmd 60/00:98:f0:61:09/01:00:00:02:00/40 tag 19 ncq dma 131072 in Feb 2 15:34:32 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:32 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:32 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:32 Tower kernel: sd 4:0:0:0: [sdd] tag#19 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:32 Tower kernel: sd 4:0:0:0: [sdd] tag#19 Sense Key : 0x3 [current] Feb 2 15:34:32 Tower kernel: sd 4:0:0:0: [sdd] tag#19 ASC=0x11 ASCQ=0x4 Feb 2 15:34:32 Tower kernel: sd 4:0:0:0: [sdd] tag#19 CDB: opcode=0x88 88 00 00 00 00 02 00 09 61 f0 00 00 01 00 00 00 Feb 2 15:34:32 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590549488 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:32 Tower kernel: ata4: EH complete Feb 2 15:34:35 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x2000 SErr 0x0 action 0x0 Feb 2 15:34:35 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:35 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:35 Tower kernel: ata4.00: cmd 60/00:68:f0:62:09/01:00:00:02:00/40 tag 13 ncq dma 131072 in Feb 2 15:34:35 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:35 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:35 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:35 Tower kernel: sd 4:0:0:0: [sdd] tag#13 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:35 Tower kernel: sd 4:0:0:0: [sdd] tag#13 Sense Key : 0x3 [current] Feb 2 15:34:35 Tower kernel: sd 4:0:0:0: [sdd] tag#13 ASC=0x11 ASCQ=0x4 Feb 2 15:34:35 Tower kernel: sd 4:0:0:0: [sdd] tag#13 CDB: opcode=0x88 88 00 00 00 00 02 00 09 62 f0 00 00 01 00 00 00 Feb 2 15:34:35 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590549744 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:35 Tower kernel: ata4: EH complete Feb 2 15:34:39 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x10000 SErr 0x0 action 0x0 Feb 2 15:34:39 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:39 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:39 Tower kernel: ata4.00: cmd 60/00:80:f0:63:09/01:00:00:02:00/40 tag 16 ncq dma 131072 in Feb 2 15:34:39 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:39 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:39 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:39 Tower kernel: sd 4:0:0:0: [sdd] tag#16 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:39 Tower kernel: sd 4:0:0:0: [sdd] tag#16 Sense Key : 0x3 [current] Feb 2 15:34:39 Tower kernel: sd 4:0:0:0: [sdd] tag#16 ASC=0x11 ASCQ=0x4 Feb 2 15:34:39 Tower kernel: sd 4:0:0:0: [sdd] tag#16 CDB: opcode=0x88 88 00 00 00 00 02 00 09 63 f0 00 00 01 00 00 00 Feb 2 15:34:39 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590550000 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:39 Tower kernel: ata4: EH complete Feb 2 15:34:42 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x80000 SErr 0x0 action 0x0 Feb 2 15:34:42 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:42 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:42 Tower kernel: ata4.00: cmd 60/00:98:f0:64:09/01:00:00:02:00/40 tag 19 ncq dma 131072 in Feb 2 15:34:42 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:42 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:42 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:42 Tower kernel: sd 4:0:0:0: [sdd] tag#19 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:42 Tower kernel: sd 4:0:0:0: [sdd] tag#19 Sense Key : 0x3 [current] Feb 2 15:34:42 Tower kernel: sd 4:0:0:0: [sdd] tag#19 ASC=0x11 ASCQ=0x4 Feb 2 15:34:42 Tower kernel: sd 4:0:0:0: [sdd] tag#19 CDB: opcode=0x88 88 00 00 00 00 02 00 09 64 f0 00 00 01 00 00 00 Feb 2 15:34:42 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590550256 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:42 Tower kernel: ata4: EH complete Feb 2 15:34:45 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x400000 SErr 0x0 action 0x0 Feb 2 15:34:45 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:45 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:45 Tower kernel: ata4.00: cmd 60/00:b0:f0:65:09/01:00:00:02:00/40 tag 22 ncq dma 131072 in Feb 2 15:34:45 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:45 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:45 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:45 Tower kernel: sd 4:0:0:0: [sdd] tag#22 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:45 Tower kernel: sd 4:0:0:0: [sdd] tag#22 Sense Key : 0x3 [current] Feb 2 15:34:45 Tower kernel: sd 4:0:0:0: [sdd] tag#22 ASC=0x11 ASCQ=0x4 Feb 2 15:34:45 Tower kernel: sd 4:0:0:0: [sdd] tag#22 CDB: opcode=0x88 88 00 00 00 00 02 00 09 65 f0 00 00 01 00 00 00 Feb 2 15:34:45 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590550512 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:45 Tower kernel: ata4: EH complete Feb 2 15:34:49 Tower kernel: ata4.00: exception Emask 0x0 SAct 0x2000000 SErr 0x0 action 0x0 Feb 2 15:34:49 Tower kernel: ata4.00: irq_stat 0x40000008 Feb 2 15:34:49 Tower kernel: ata4.00: failed command: READ FPDMA QUEUED Feb 2 15:34:49 Tower kernel: ata4.00: cmd 60/00:c8:f0:66:09/01:00:00:02:00/40 tag 25 ncq dma 131072 in Feb 2 15:34:49 Tower kernel: ata4.00: status: { DRDY SENSE ERR } Feb 2 15:34:49 Tower kernel: ata4.00: error: { UNC } Feb 2 15:34:49 Tower kernel: ata4.00: configured for UDMA/133 Feb 2 15:34:49 Tower kernel: sd 4:0:0:0: [sdd] tag#25 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=3s Feb 2 15:34:49 Tower kernel: sd 4:0:0:0: [sdd] tag#25 Sense Key : 0x3 [current] Feb 2 15:34:49 Tower kernel: sd 4:0:0:0: [sdd] tag#25 ASC=0x11 ASCQ=0x4 Feb 2 15:34:49 Tower kernel: sd 4:0:0:0: [sdd] tag#25 CDB: opcode=0x88 88 00 00 00 00 02 00 09 66 f0 00 00 01 00 00 00 Feb 2 15:34:49 Tower kernel: blk_update_request: I/O error, dev sdd, sector 8590550768 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 Feb 2 15:34:49 Tower kernel: ata4: EH complete Feb 2 15:34:51 Tower wsdd2[4129]: 'Terminated' signal received. Feb 2 15:34:51 Tower wsdd2[4129]: terminating. Feb 2 15:34:53 Tower root: /usr/sbin/wsdd2 -d Feb 2 15:34:53 Tower wsdd2[5457]: starting. ** Press ANY KEY to close this window ** Fix Common Problems plugin also said | If the disk has not been disabled, then Unraid has successfully rewritten the contents of the offending sectors back to the hard drive. I'm about to try skimming through a bunch of media files on Disk 5 to see if any more errors happen.
-
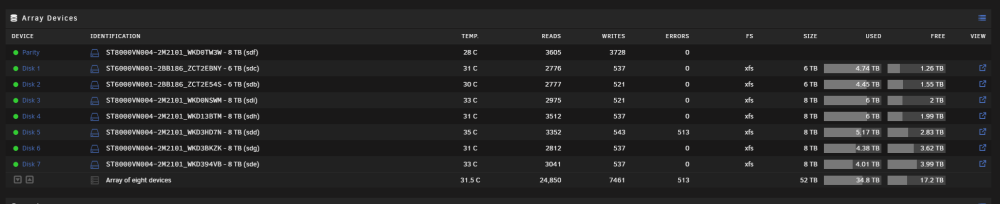
Turned off Server. Changed SATA cable. When I tried to start the array, this time it took far longer than normal and got stuck on starting up Disk 5 (the disk with errors). It did eventually start the array but now it's pumping out errors. tower-smart-20230202-1535.zip
-
Errors seem to be increasing. Also here is the latest smart report. Number of Reallocated Logical Sectors = 40 So gone from 8, to 16, to 32, to 40. Am I likely to be needing to replace this drive? I'll power off and try another SATA cable. tower-smart-20230202-1521.zip

-
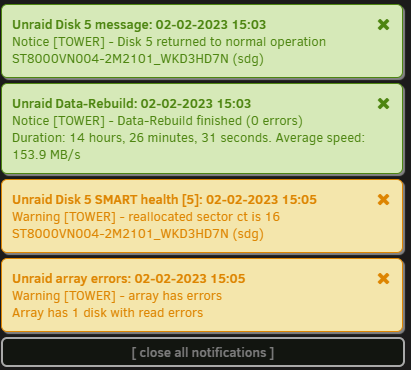
Rebuild finally finished. However the reallocated sector ct has seemingly gone up from 8 to 16. Attached latest diagnostics. Thoughts on what to do? Is this just the system "catching up" on errors after doing the rebuild or am I likely to see these errors continue to increase? Thanks tower-diagnostics-20230202-1507.zip

-
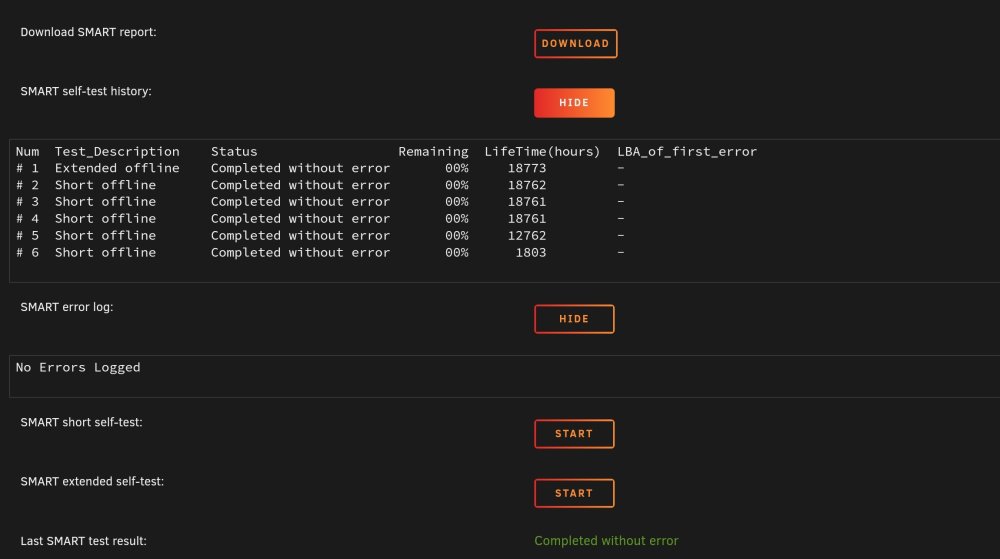
Well you were definitely right about that. It just finished without error. I don't know if I'm supposed to upload the smart report too or diagnostics log but I guess I'll do it just in case. Been a long while since I had to rebuild a drive. I think I put it in maintenance mode to do it. I'll figure it out. Will update thread tomorrow with results. tower-smart-20230202-0007.zip tower-diagnostics-20230202-0013.zip
-
That's fine, as long as it's not going to be more beneficial to run with the array off or on. I'll just do it with it off. I'll report back once it's complete.
-
Okay thanks. So I should run that before trying to start the array? Or would it be better to start the Array and then run the Extended test? And then after I run the extended test I should run a rebuild? how do I do that exactly? Do I start the array in maintenance mode or something
-
Just got another email (12:10PM) Event: Unraid Disk 5 SMART health [199] Subject: Warning [TOWER] - udma crc error count is 299 Description: ST8000VN004-2M2101_WKD3HD7N (sde) Importance: warning Server has now been turned off. I'm going to take it off the LSI card and move it back to a SATA cable from motherboard SATA ports, but now I'm hesitant to turn the server back on so I'll wait for some advice before turning it back on again.
-
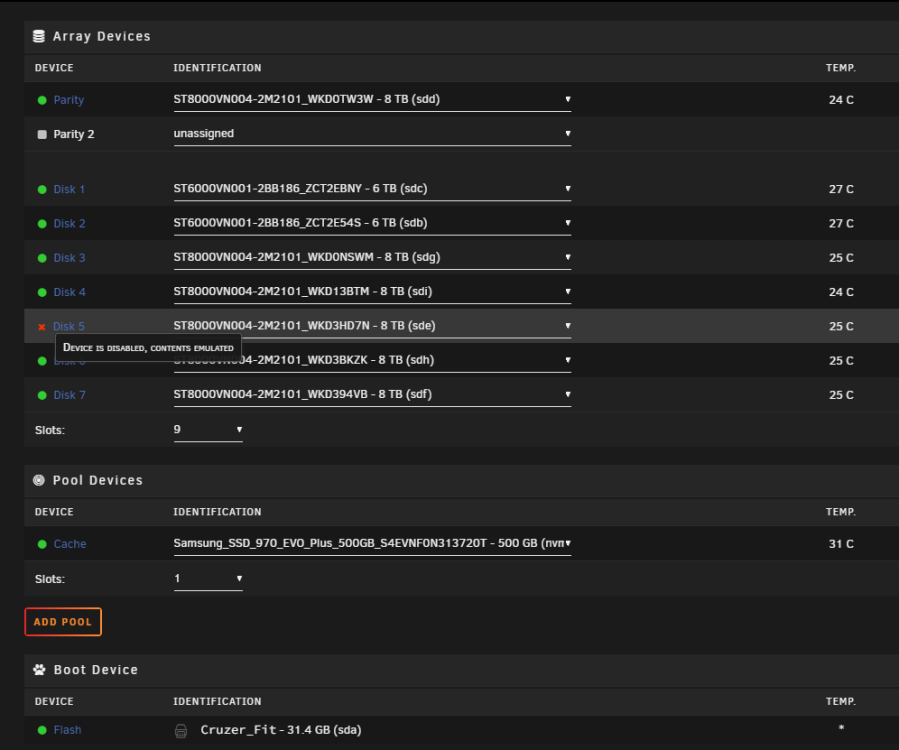
UnRAID 6.10.3 B550M Mortar Wifi Ryzen 3900X Hello, Got a couple of emails this morning from my server to say a Disk had errors. It's been quite a while since the last time I had any errors so I was a little unsure what to do and am looking for some guidance. Here is the first email around 5:30am (Mover starts at 5am) Event: Unraid array errors Subject: Warning [TOWER] - array has errors Description: Array has 1 disk with read errors Importance: warning Disk 5 - ST8000VN004-2M2101_WKD3HD7N (sde) (errors 2048) Then here is the second email around 10:00am Event: Unraid Disk 5 SMART health [5] Subject: Warning [TOWER] - reallocated sector ct is 8 Description: ST8000VN004-2M2101_WKD3HD7N (sde) Importance: warning I had downloaded a couple hundred GB of stuff yesterday and when the mover ran overnight, only this specific drive had any writes to it from mover, so I think the error count came from mover. Now this is where I potentially made a mistake that I will regret. I had noticed a whole bunch of my stuff I downloaded had not been properly moved across folders by Lidarr and were "stuck" in a completed downloads folder. I knew a bunch of the files were not very important to me and so I stupidly went into Windows explorer to my network share of unRAID and simply deleted the files from this completed downloads folder that were not being moved. It was probably around 300GB of files. I realised as soon as it started deleting the files that I probably should not have touched any data...but what's done is done I suppose. I have taken a diagnostics snapshot from before I restarted the server, then after. And also ran a SMART short test before and after, and also took SMART downloads. (I'm still not actually sure how I check a SMART short test. I run it and it says some % progress and then says done, but where do I find the test?) I turned the server off, changed the SATA cable over on the drive from my motherboard to my LSI SAS card, and when I turned the server back on the disk was disabled still but this time it now says udma CRC Error count 70. (which it also emailed me about) 3rd Email (11:40am) Event: Unraid Disk 5 SMART health [199] Subject: Warning [TOWER] - udma crc error count is 70 Description: ST8000VN004-2M2101_WKD3HD7N (sde) Importance: warning I'm going to turn the server off again now after posting this, and move the drive back to a new SATA cable via motherboard SATA port instead of the LSI card. But just after advice on what my next steps should be? tower-diagnostics-20230201-0958-Pre Restart.zip tower-diagnostics-20230201-1024-Post Restart.zip tower-smart-20230201-1019.zip tower-smart-20230201-1145 - Cable change mobo to SAS card.zip
-
I just want to say thank you very much for this guide. Made it very simple to fix. Hopefully this resolves my issue that I just ran into today!






