

Tomr
-
Posts
23 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Tomr
-
-
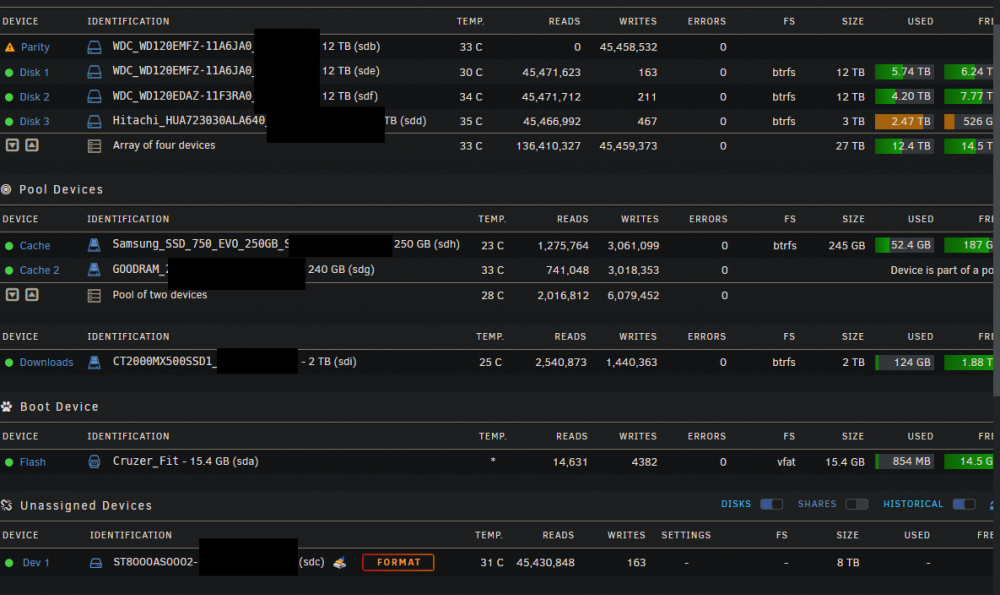
I removed one of the drives from the array, created new config and let it recreate parity. But it seems that it's using unassigned device (the one I removed) for some reason. You can see the reads amount on the screen, it's on par with the array disks and is growing with them. dstat shows 0MB/s read and write on it though, so it might be a visual bug. But on the other hand, it won't let me spin-down this drive, logs will show:
QuoteOct 16 11:10:40 Tower emhttpd: spinning down /dev/sdc
Oct 16 11:10:40 Tower emhttpd: read SMART /dev/sdcI don't know if it's UA's bug or Unraid one and I'm screwing up my parity.
I'm on 6.10.0 RC1
-
Could you update jdupes to newer version? Current version is bugged, see: https://github.com/jbruchon/jdupes/releases for 1.15 release. I personally would like/need at least 1.18.1 for the newer/older filter
-
1 hour ago, itimpi said:
Encryption is irrelevant to this as parity runs at the physical sector level. Unraid will go straight into clearing a disk when you add it any time it does not recognise a ‘clear’ signature as being present on the drive.
I wonder why it didn't recognize the correct signature then.
-
6 hours ago, itimpi said:
Unraid does not need to do anything to parity when you add a 'clear' disk as since it is all zeroes it does not affect parity. It is at this stage that you tell Unraid to format the disk (which only takes a few minutes) and as you format the disk (which is a form of write operation) then Unraid will be updating parity to reflect this format operation.
The thing is I didn't tell it to format anything. I just added new slot, started the array and it went up straight to cleaning it. Now that I think about it, it's prob because my array is encrypted.
-
3 hours ago, DougCube said:
Sounds like something went wrong with the preclear. Clicking the X should have no impact. Once the preclear is done, even before the post-read, there would be a signature written to the drive that Unraid picks up on when you later add it to the array so that it doesn't have to clear it again.
I've never heard of this happening.
Everything went fine, I received email saying so, and I also checked the logs.
Quote== invoked as: /usr/local/sbin/preclear_disk_ori.sh -M 1 -o 2 -c 1 -W -f -J /dev/sdf
== WDCWD120EDAZ-11F3RA0 XXXXXXXX
== Disk /dev/sdf has been successfully precleared
== with a starting sector of 64
== Ran 1 cycle
==
== Last Cycle`s Zeroing time : 20:27:01 (162 MB/s)
== Last Cycle`s Total Time : 43:37:02
==
== Total Elapsed Time 43:37:02
==
== Disk Start Temperature: 30C
==
== Current Disk Temperature: 30C,
2 hours ago, Zorlofe said:I wish I had noticed this post earlier, lol. Thank you for pointing this out. I had the same problem as the previous poster and that would have saved me some time on a 12TB drive.
That means preclear doesn't do anything when adding new drive? That's strange. I thought Unraid should pickup that the disk is precleared and go straight to syncing parity. I didn't format the disk as trurl wrote, just preclear.
-
In 6.9, I did a preclear on disk, using Joe-L, skip pre-read and selected fast post-read. It finished, I got notification on email so I added it to the array (new slot), and unraid clears the disk again ("Clearing in progress"). Is it normal? Or it happened because I didn't click the red "X" button after the preclear? I thought pre-clearing's purpose was to not have to clear it when adding to array.
-
Referring to this suggestion to invoke mover before changing cache settings I ask for a "Move Now" equivalent button in share settings so one could move just that share's cache, not the whole array.
-
 1
1
-
-
More reading about the differences with different schedules. I wont copy-paste the internet here:
Benchmarks on NVME SSD - https://www.phoronix.com/scan.php?page=article&item=linux-56-nvme&num=1
Benchmarks on HDD - https://www.phoronix.com/scan.php?page=article&item=linux-50hdd-io&num=1
YMMW, you can only be sure what is best for you if you do the benchmarks yourself. How to change your schedulers and auto-apply them on every reboot?
nano /etc/udev/rules.d/60-ioschedulers.rules
Paste the code:
# set scheduler for NVMe ACTION=="add|change", KERNEL=="nvme[0-9]*", ATTR{queue/scheduler}="none" # set scheduler for SSD and eMMC ACTION=="add|change", KERNEL=="sd[a-z]|mmcblk[0-9]*", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="mq-deadline" # set scheduler for rotating disks ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="bfq"
Apply the settings (can be done when array is started):
udevadm control --reload
udevadm triggerYou are done, the schedulers should be changed. you can verify it by typing: cat /sys/block/sdg/queue/scheduler (sdg is your device)
mq-deadline (default for everything in UnRAID) may be better for HDD's for high throughput, all depends on your use case.
-
2
-
 2
2
-
-
I'm evaluating UnRAID for my new NAS, I modified your script a bit. With it, one can create periodic snapshots with various retention policy (eg. keep hourly backups for a day, daily backups for a week etc). You just need to schedule more copy of the script. I think you can't pass arguments to scheduled script, so I deleted them.
(Optional) Add this to your Settings->SMB->SMB Extra. This enables file versioning for smb clients.
vfs objects = shadow_copy2
shadow:sort = desc
shadow:format = _UTC_%Y.%m.%d-%H.%M.%S
shadow:localtime = no
shadow:snapprefix = ^\(monthly\)\{0,1\}\(weekly\)\{0,1\}\(daily\)\{0,1\}\(hourly\)\{0,1\}$
shadow:delimiter = _UTC_Here's the code:
#!/bin/bash #description=This script implements incremental snapshots on btrfs array drives. Credits @catapultam_habeo #arrayStarted=true #If you change the type you'll have to delete the old snapshots manually #valid values are: hourly, daily, weekly, monthly SNAPSHOT_TYPE=daily #How many days should these snapshots last. RETENTION_MINUTES=$((7*60*24)) #7 days #RETENTION_MINUTES=5 #Name of the shares to snapshot, can be comma separated like "medias,valuables" INCLUDE=valuables #name of the snapshot folder and delimeter. Do not change. #https://www.samba.org/samba/docs/current/man-html/vfs_shadow_copy2.8.html SNAPSHOT_DELIMETER="_UTC_" SNAPSHOT_FORMAT="$(TZ=UTC date +${SNAPSHOT_TYPE}${SNAPSHOT_DELIMETER}%Y.%m.%d-%H.%M.%S)" shopt -s nullglob #make empty directories not freak out is_btrfs_subvolume() { local dir=$1 [ "$(stat -f --format="%T" "$dir")" == "btrfs" ] || return 1 inode="$(stat --format="%i" "$dir")" case "$inode" in 2|256) return 0;; *) return 1;; esac } #Tokenize include list declare -A includes for token in ${INCLUDE//,/ }; do includes[$token]=1 done echo "RETENTION_MINUTES: ${RETENTION_MINUTES}" #iterate over all disks on array for disk in /mnt/disk*[0-9]* ; do #examine disk for btrfs-formatting (MOSTLY UNTESTED) if is_btrfs_subvolume $disk ; then #iterate over shares present on disk for share in ${disk}/* ; do declare baseShare=$(basename $share) #test for exclusion if [ ! -n "${includes[$baseShare]}" ]; then echo "$share is not in the inclusion list. Skipping..." else #check for .snapshots directory prior to generating snapshot #only before we make the actual snapshot #so we don't create empty folders if [ -d "$disk" ]; then if [ ! -d "$disk/.snapshots/$SNAPSHOT_FORMAT/" ] ; then #echo "new" mkdir -v -p $disk/.snapshots/$SNAPSHOT_FORMAT fi fi #echo "Examining $share on $disk" is_btrfs_subvolume $share if [ ! "$?" -eq 0 ]; then echo "$share is likely not a subvolume" mv -v ${share} ${share}_TEMP btrfs subvolume create $share cp -avT --reflink=always ${share}_TEMP $share rm -vrf ${share}_TEMP fi #make new snap btrfs subvolume snap -r ${share} $disk/.snapshots/${SNAPSHOT_FORMAT}/$baseShare #find old snaps #echo "Found $(find ${disk}/.snapshots/${SNAPSHOT_TYPE}${SNAPSHOT_DELIMETER}*/${baseShare} -maxdepth 0 -mindepth 0 -type d -mmin +${RETENTION_MINUTES} | wc -l) old snaps" for snap in $(find ${disk}/.snapshots/${SNAPSHOT_TYPE}${SNAPSHOT_DELIMETER}*/ -maxdepth 0 -mindepth 0 -type d -mmin +${RETENTION_MINUTES}); do #echo "Deleting: ${snap}${baseShare}" [ -d ${snap}${baseShare} ] && btrfs subvolume delete ${snap}${baseShare} #this will only delete empty directory so it's safe to call #even if there are other backups there rmdir $snap --ignore-fail-on-non-empty done fi done fi done



Unassigned Devices - Managing Disk Drives and Remote Shares Outside of The Unraid Array
in Plugin Support
Posted
That didn't help, I've posted a report here