
wickedathletes
-
Posts
435 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by wickedathletes
-
-
bump... server appears to be hung up again and I know when I cmd line reboot it nothing will reboot. any thoughts?
-
So the GUI locks up on occasion for me. What I am wondering is why I can't reboot it from the command line anymore This isn't new to 6.3.5, this has been happening for a long time for me. I do have the powerdown plugin installed.
I try:
reboot
powerdown -r now
shutdown -r now
They all appear to "work" with the System restart now message, but do nothing.
-
2 hours ago, Squid said:
Personally I wouldn't exclude the drives from those shares. While the media within the share(s) isn't going to change, there is a possibility that you may update the meta data (eg: Kodi's .nfo files) associated with them. Excluding would mean that the .nfo files would be separated on a different disk than the media files (assuming of course you have split level's set to keep everything together)
so what is the best way to make it so the drives are ignored for adding new movies? Basically what happens is if I have a drive set to 10GB minimum it still tries to sometimes push files to it causing it to fail, or push a partial file (even worse). I just want the drive ignored unless manual intervention is used (like if I update my meta data with Ember Media Manager. The drive(s) wont change for a LONG time, they are 4TB full of only 1080p movies.
-
If I have some full drives of data that will not change, is it better to exclude them from a share, or better to set my share settings minimum allocation amount to a higher number than is available on the drive? I seem to remember the minimum did not do what I previously intended.
Currently, I have been keeping all drives distributed evenly (space-wise), but its a pain in the ass and probably the incorrect way to do things for drive health and usage. So I moved my data around and I have 6 of 8 drives that can be "locked" so to speak (data wont change). I still need my files from those drives accessible (Movies, TV Shows etc), but I don't want unRAID writing to them anymore.
-
19 minutes ago, johnnie.black said:
Errors on ATA1 look cable related, or less likely enclosure.
Are they throwing different errors? Sorry I'm not good at looking at the diagnostic logs.
-
4 minutes ago, johnnie.black said:
Diagnostics you posted only show issues on ata7, post the ones with errors on ata1.
thankfully ata1 just had the problem. Attached.
Last night I did replace the cable on ata7 hoping that fixed it, but it sometimes works for a week or two, sometimes a day. The thing that threw me was it seems to bounce between the two.
Definitely not the drives since putting a new drive there, the new drive got the error.
thank you again.
-
1 hour ago, johnnie.black said:
No, I mean the marvell controller, ata7/8/9 and 10
This is the one I have:
https://www.amazon.com/gp/product/B00AZ9T3OU/ref=oh_aui_search_detailpage?ie=UTF8&psc=1
Problem being though, serial ata1 did the same thing, which is on my MoBo. So what are the chances that my MoBo and my PCI card are having issues?
It is bouncing around between ata1 and ata7. Same errors on both.
-
8 hours ago, johnnie.black said:
Number 1 suspect is the Marvell controller where those disks are connected, they are known to have issues, expecially with vt-d enable.
I assume you mean on the MoBo? I forgot to mention I have a sata card as well, and of course one is plugged into that and one is plugged into the MoBo.
so that leaves me with:
Cable
Hot Swap Bay port
PSU?
-
So the error stayed at the ata location and didn't move with the drive when I moved the two drives to other spots. If that's the case what would I want to look at?
PSU?
Cable?
HotSwap Bay?
Sata port on MoBo?
obviously it isn't the drive, although with 2 having issues I'm still unclear. I have once seen both drives acting up, however most of the time it's just one location.
-
So is there a way to test if this could possibly be a PSU issue? Have I reached my max finally? Could I be overloading a source because of the hot swap bay powering 5 drives at once?
PSU: Antec NEO ECO 520C (520W)
+3.3V@24A, +5V@24A, +12V@40A, [email protected], [email protected]MoBo: ASRock Z68 Extreme4 LGA 1155 Intel Z68 HDMI SATA 6Gb/s USB 3.0 ATX Intel Motherboard
CPU: Intel Core i7-2600K Sandy Bridge Quad-Core 3.4GHz (3.8GHz Turbo Boost) LGA 1155 95W BX80623I72600K Desktop Processor Intel HD Graphics 3000
Memory: G.SKILL Ripjaws X Series 16GB (4 x 4GB) 240-Pin DDR3 SDRAM DDR3 1866 (PC3 14900) Desktop Memory Model F3-14900CL9Q-16GBXL
Hot Swap: SUPERMICRO CSE-M35T-1B 3 x 5.25" to 5 x 3.5" Hot-swap SATA HDD Trays
SATA PCI Controller:
IO Crest 4 Port SATA III PCI-e 2.0 x1 Controller Card Marvell Non-Raid with Low Profile Bracket SI-PEX4006
HDs:
WDC WD20EZRX-00D8PB0
Hitachi HDS5C4040ALE630 (parity)
WDC WD20EARS-00MVWB0
WDC WD40EFRX-68WT0N0 (throwing errors)
TOSHIBA MD04ACA400
WDC WD40EFRX-68WT0N0 (throwing errors)
WDC WD40EZRZ-00WN9B0
TOSHIBA MD04ACA400HGST HDS5C4040ALE630
Crucial_CT750MX300SSD1 (cache)I do have a backup PSU from my old gaming PC that I could test but don't want to waste my time if it wouldn't be the issue:
SeaSonic X Series X-850 (SS-850KM3 Active PFC F3) 850W ATX12V v2.3 / EPS 12V v2.91 SLI Ready CrossFire Ready 80 PLUS GOLD Certified Full Modular Active PFC Power Supply New 4th Gen CPU Certified Haswell Ready -
I have 2 drive periodically giving me following error:
ata7.00: exception Emask 0x0 SAct 0x0 SErr 0x400000 action 0x6 frozen
The two drives doing this are my two newest drives (ordered about 3 months apart so not a batch issue, WD Reds). These replaced drives doing the same thing as far as I remember...its been a few months. That said, could other things cause this? Like bad cables, connectors etc etc?
edit: added diagnostics.
-
12 hours ago, Squid said:
Not related....
ya i saw that note but it appeared when I tried to spin up a drive to run a smart scan, so maybe a bug in the unraid UI itself?
-
not sure if related but this is in my logs now:
error: webGui/include/ProcessStatus.php: wrong csrf_token `
-
First time I have ever seen this, so just asking for some help because I got no idea...
Your server has issued one or more call traces. This could be caused by a Kernel Issue, Bad Memory, etc. You should post your diagnostics and ask for assistance on the unRaid forums
hades-diagnostics-20170319-0918.zip
would this type of error occur because of the issue with Disk 1 I see in the log?
-
25 minutes ago, Squid said:
Generally its because you don't have the host and container path within the dl client matching exactly the host and container path on radarr
Also are you sure you don't have a typo or something that's causing radarr to move the completes to inside the container?
it has worked on about 50 files, just randomly failed on 2 other ones. So path should be ok (obviously might not be). But in Radarr I have 0 paths set anyways. I am sure I a doing something wrong, I just can't seem to find it that is for sure.
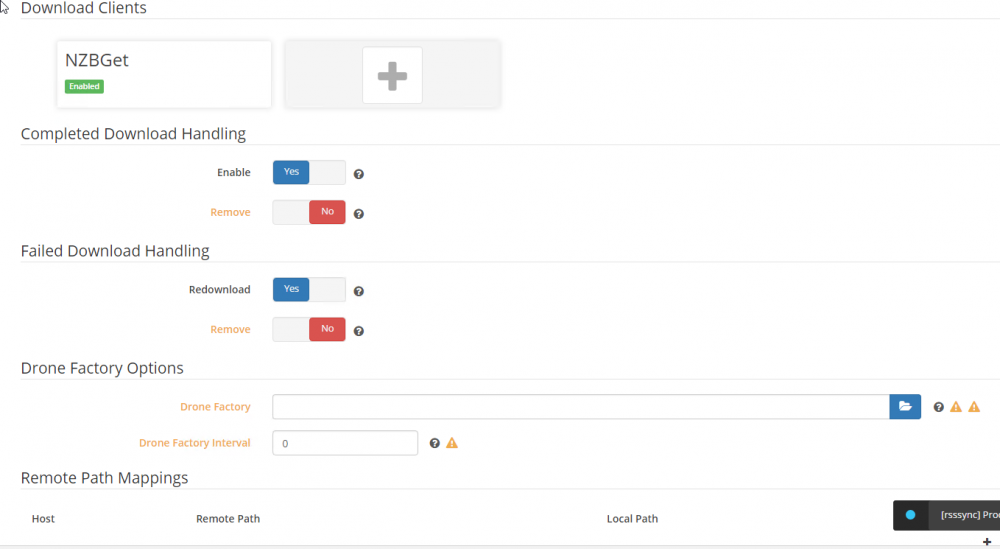
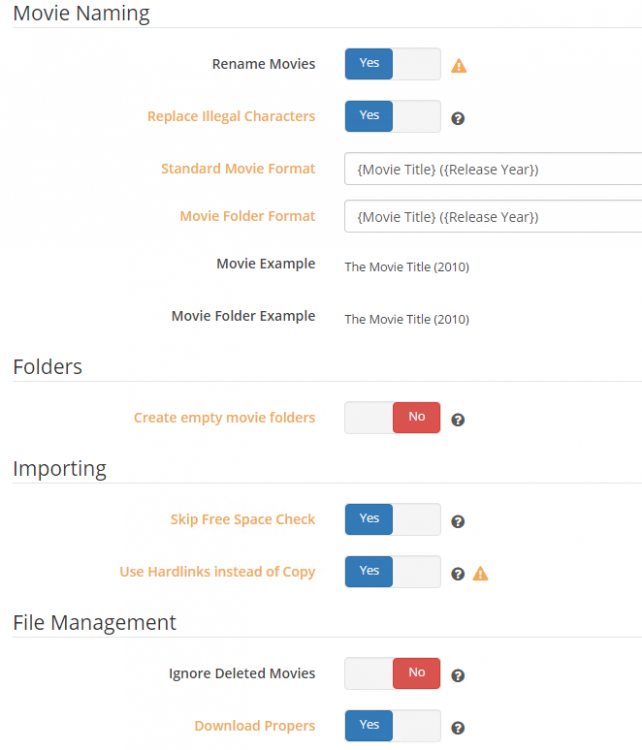
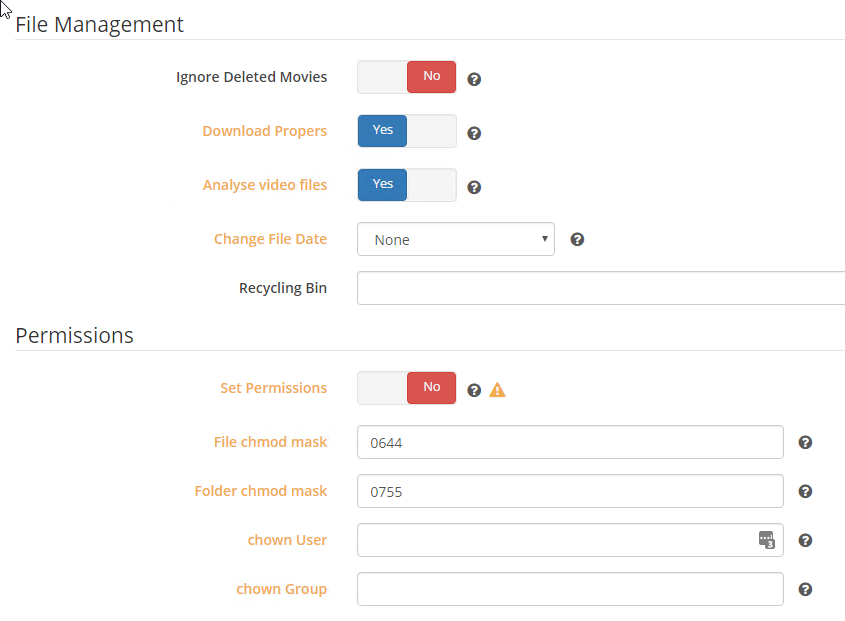
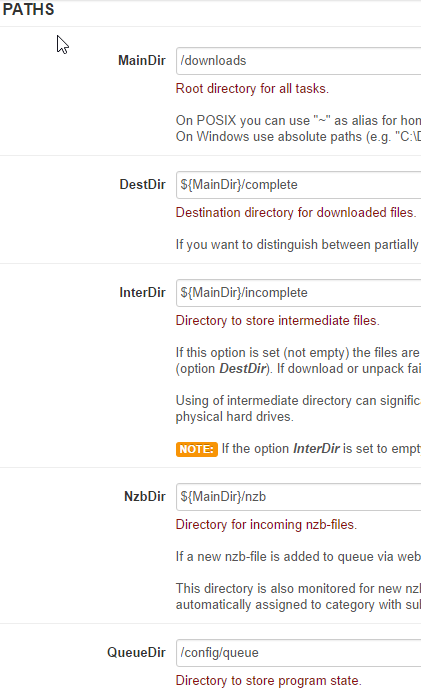
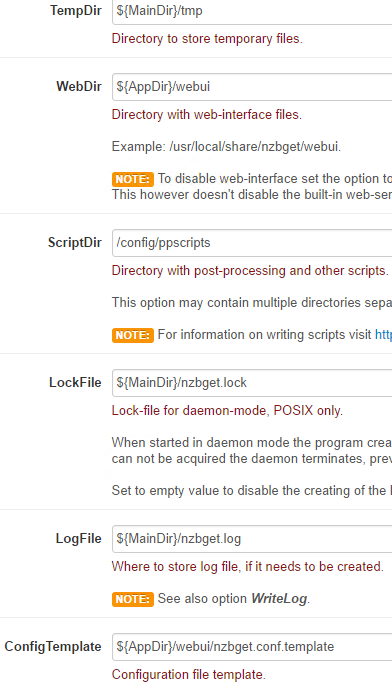
-
3 hours ago, Squid said:
First and easiest thing to do is to look at whatever logging level you are able to set within radar and lower it. Since its in development, it might be actively logging "Wow it's a new second and I'm still alive, let's log that"
Logging is set to INFO (their lowest level). That said I did notice something and hopefully Radarr will have some more info (on their reddit).
This has happened to me twice and both times (whether related or not) I am getting heavy errors in my logs after moving a movie (and radarr thinking it didnt). So over and over I get this:
Import failed, path does not exist or is not accessible by Radarr: /downloads/complete/movies/BLAH.BLAHor this
Couldn't process tracked download Killing.Fields.2011.REPACK.MULTi.LiMiTED.1080p.BluRay.x264-ZEST: Movie with ID 1500 does not exist
That said, clearing the log doesn't release the space.
-
3 hours ago, trurl said:
And as with everything Linux, it is critical that you get upper/lower case exactly right. If you did have /mnt/User/downloads instead of /mnt/user/downloads, that was your problem.
ya i wish that catch was it but its still happening.
Istheira way to see what container is taking the space so I know what to narrow down onto?I am just assuming its Radarr since it was the newest container added.figured out how:
docker ps -s
and its Radarr... still have no idea how though:
7cd26415cdaf linuxserver/radarr "/init" 11 hours ago Up 3 hours 0.0.0.0:7878->7878/tcp radarr 24.9 GB (virtual 25.25 GB)
-
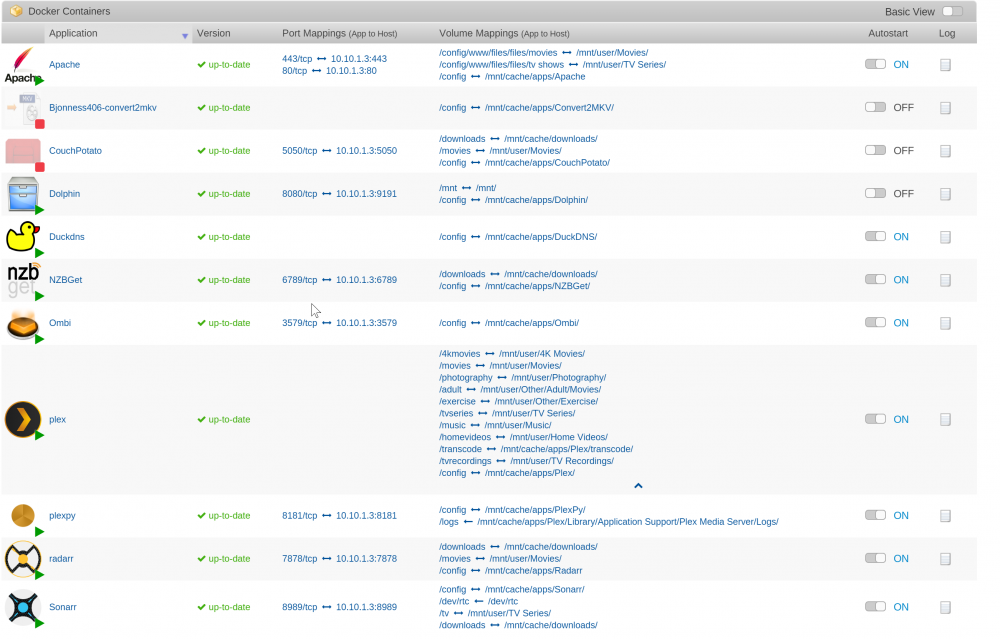
Just looking for a second pair of eyes. I thought originally it was Radarr causing an issue because I had my /downloads path set to /mnt/User/downloads instead of /mnt/cache/downloads. When I switched it and restarted Radarr my image dropped 20GB, however it just filled up again, about 6 hours later. Not really sure what could be causing it, and I am sure I am missing something but did go through the faq on space issues.
-
3 minutes ago, saarg said:
I don't use radarr so don't know how much space it needs, but turn it off to check.
Also post the settings for folders.
thanks, I think I figured it out. Not really sure why (probably my lack of understanding), but it was the container mapping on radarr.
NZBGet was pointing to /mnt/cache/downloads and Radarr was pointing to /mnt/user/downloads. Despite that just being the shared version of the cache drive (to my understanding at least), I switched it over and my img file immediately went down 20 GB. Weirdly enough, CP is pointing to the User share and never caused an issue for me.
-
ya no idea.. unless Radarr does something weird in a temp folder when it renames a file? No settings in Radarr are doing anything. Its handing off to NZBGet without issue and its definitely Radarr filling it, because i disabled radarr while NZBGet was still running and it stopped filling up.
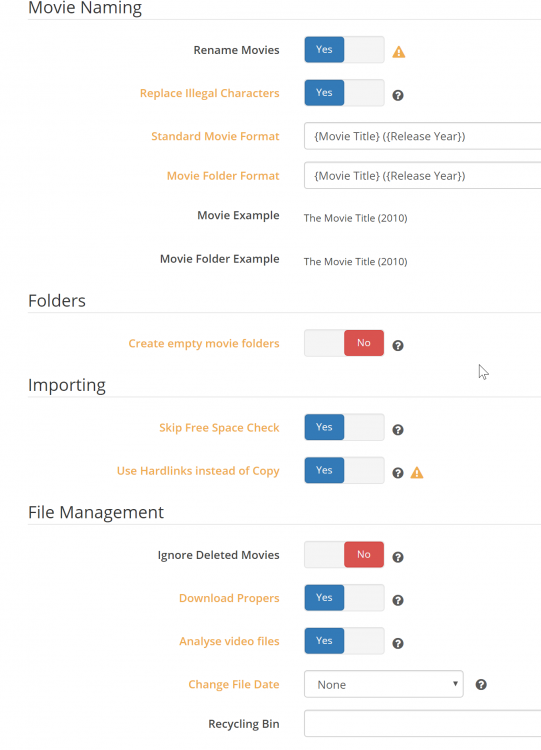
This is the only setting that maybe could do something? not really sure. Also, below are all my other file management settings
-
Just now, saarg said:
Then its the folder settings in radarr that is the problem I guess.
ya after you said i might have something wrong I thought about that too, I am checking but so far not sure. The downloads are going to the correct location so I am not sure what would fill it.
-
2 minutes ago, saarg said:
It's most likely you that configured mappings wrong or the folders in the app wrong. When the docker image fills, something is stored in the container instead of the folder mappings.
You should have a look in the docker FAQ to better understand how docker works.
anything out of the ordinary on this? This setup works 100% fine on my other 10 or so apps for the last 1 or so years.

-
anyone having docker container size issues using this container? I have a 30gb container and within about 20 minutes of rebuilding it and turning radarr on it filled 100% from about 5gb.
Radarr is indexing about 2200 movies for me, so maybe that is why? Should I just grown my docker image or is this a bug of sorts?
-
And if you have to deal with WAF then that consideration trumps all others.
*But* if you're not using the dated backup feature of CA, then I'd disable the backup schedule just so you don't wind up trashing the backup set from a couple of days ago until you get around to restoring again.
Worse than WAF, I have my parents breathing down my neck because they are 3 episodes left of breaking bad and my server has been down 2 days. damn you remote access plex. hahaha









GUI Locks Up, Best way to debug why reboots dont work
in General Support
Posted
unfortunately this time it was completely locked out.
any reason why shutdown -r now or reboot wouldn't work then? And if their is a better way when the UI locks up to reboot the server, I would love to know