




Simom
Members
-
Joined
-
Last visited
Everything posted by Simom
-
In theory yes, you should also make sure that no one else is accessing the files over smb, nfs or whatever before starting to move the files. But I would highly advise to check if the files system runs as expected before moving important data back to the cache.
-
Just realized, that I never followed up to this: I switched from macvlan to ipvlan for my docker containers and that seems to have fixed it. No crashing, no corrupting since that. (I guess the macvlan stuff lead to kernel panics, that lead to the corruption of the files; but I am no expert). p.s. I also read that there have been changes to macvlan.
-
Thanks for the quick response! I will try that and see how it goes.
-
just wanted to get back to this: memtest has been running for over 72hours without finding anything. are there any other trouble shooting that steps I can try?
-
I think I didn't clearly state my previous trouble shooting steps and this is leading me to some confussion. So all in order: I had some csum erros like the one in my first comment I swapped systems with new CPU, MoBo and RAM unassigned both drives, formatted them and created a new pool not even 48h later I get a new csum error As I created a new pool, this still might be a problem with my current RAM, but not with my old one, or am I missing something? Memtest is running, nothing found this far. Any advice on how long I should leave this running (I read 24-48 hours somewhere)?
-
Alright I will try that! As I said I had a similiiar issue to this one some time ago but swapped CPU, MoBo and RAM since then. Nevertheless thanks for the help!
-
Hey, thanks for the response. You are kinda right. but that error is from another cache pool (my nvme one) (I am currently working on clearing the pool you mentioned, so I can scrub and format it). As far as I understand the error you mentioned shouldn't be connected to the one I posted about because the devices are part of different pools or am I missing something?
-
Hello! I am running a RAID1 SATA SSD Cache pool and I am getting some BTRFS errors: Jan 29 23:57:12 Turing kernel: BTRFS warning (device sdd1): csum failed root 5 ino 3599 off 2499960832 csum 0x60341ddd expected csum 0x88e58ce3 mirror 2 Jan 29 23:57:12 Turing kernel: BTRFS error (device sdd1): bdev /dev/sdd1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Jan 29 23:57:12 Turing kernel: BTRFS warning (device sdd1): csum failed root 5 ino 3599 off 2499964928 csum 0x1470dccc expected csum 0x8188ffff mirror 2 Jan 29 23:57:12 Turing kernel: BTRFS error (device sdd1): bdev /dev/sdd1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Jan 29 23:57:12 Turing kernel: BTRFS warning (device sdd1): csum failed root 5 ino 3599 off 2499960832 csum 0x60341ddd expected csum 0x88e58ce3 mirror 1 Jan 29 23:57:12 Turing kernel: BTRFS error (device sdd1): bdev /dev/sde1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Jan 29 23:57:12 Turing kernel: BTRFS warning (device sdd1): csum failed root 5 ino 3599 off 2499964928 csum 0x1470dccc expected csum 0x8188ffff mirror 1 Jan 29 23:57:12 Turing kernel: BTRFS error (device sdd1): bdev /dev/sde1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Jan 29 23:57:12 Turing kernel: BTRFS warning (device sdd1): csum failed root 5 ino 3599 off 2499960832 csum 0x60341ddd expected csum 0x88e58ce3 mirror 2 Jan 29 23:57:12 Turing kernel: BTRFS error (device sdd1): bdev /dev/sdd1 errs: wr 0, rd 0, flush 0, corrupt 3, gen 0 Jan 29 23:57:12 Turing kernel: BTRFS warning (device sdd1): csum failed root 5 ino 3599 off 2499964928 csum 0x1470dccc expected csum 0x8188ffff mirror 2 Jan 29 23:57:12 Turing kernel: BTRFS error (device sdd1): bdev /dev/sdd1 errs: wr 0, rd 0, flush 0, corrupt 4, gen 0 As I had some issues with this pool (and another one) some time ago with similiar looking logs, I decided to fromat both drives about 2 days ago. I recreated the cache pool and moved the data back and not even after 48h I got the error above. I would be thankful if someone has an idea or can point me into a direction! (Diagnostics are attached) turing-diagnostics-20230130-0205.zip
-
Thanks for the help, I really appreciate it!
-
Thank you for the reply! I rebooted and dropped down to the default DDR4 speeds and the scrub finished with some errors that were corrected. I was thinking of switching to an Intel-based system, is there a similar list for supported RAM configurations or is it mainly a Ryzen issue?
-
Hey, I have a BTRFS related problem and I am unsure what to do, so any help is appreciated! I realized some of my dockers weren't running properly, so I took a look into the log and found these lines created about every five seconds BTRFS error (device loop2): bdev /dev/loop2 errs: wr 39, rd 0, flush 0, corrupt 20124274, gen 0 Oct 26 03:10:23 Turing kernel: BTRFS warning (device loop2): csum hole found for disk bytenr range [412303360, 412307456) Oct 26 03:10:23 Turing kernel: BTRFS warning (device loop2): csum failed root 1370 ino 1038 off 0 csum 0x42b31ff3 expected csum 0x00000000 mirror 1 Because my docker image is stored on a BTRFS RAID1 (2 1TB NVMEs) cache pool called "cache" I am guessing that this is somewhat of the root of the problem. I also ran "btrfs dev stats /mnt/cache" resulting in the following: root@Turing:~# btrfs dev stats /mnt/cache [/dev/nvme1n1p1].write_io_errs 364810 [/dev/nvme1n1p1].read_io_errs 272 [/dev/nvme1n1p1].flush_io_errs 32498 [/dev/nvme1n1p1].corruption_errs 115 [/dev/nvme1n1p1].generation_errs 0 [/dev/nvme0n1p1].write_io_errs 0 [/dev/nvme0n1p1].read_io_errs 0 [/dev/nvme0n1p1].flush_io_errs 0 [/dev/nvme0n1p1].corruption_errs 0 [/dev/nvme0n1p1].generation_errs 0 I read in the FAQ that everything should be zero. As these are NVME drives I put cables out of the equation and just tried to start a scrub, which is directly aborted and the following lines can be seen in the log: Oct 26 03:45:18 Turing ool www[20751]: /usr/local/emhttp/plugins/dynamix/scripts/btrfs_scrub 'start' '/mnt/cache' '-r' Oct 26 03:45:18 Turing kernel: BTRFS info (device nvme1n1p1): scrub: started on devid 2 Oct 26 03:45:18 Turing kernel: BTRFS info (device nvme1n1p1): scrub: not finished on devid 2 with status: -30 Oct 26 03:45:18 Turing kernel: BTRFS info (device nvme1n1p1): scrub: started on devid 3 Oct 26 03:45:18 Turing kernel: BTRFS info (device nvme1n1p1): scrub: not finished on devid 3 with status: -30 Unfortunately, I am at a dead end with my ideas; if you have any: please let me know! (I also have attached the diagnostics) turing-diagnostics-20221026-0310.zip
-
I tested a little more and found that I can create (and run) remote tasks if I create a regular task first and then modify it to a remote one. (I am also running as root user, have not tested without it yet) I will try to narrow down the problem I am facing a little more and post an update in the next week. Thanks for the help!
-
Just tested and I can create and also run local tasks without any problems.
-
Yes, whenever I set up a remote task and click "validate" or "okay", the container restarts, and I can find a segmentation fault in the logs. I am pretty sure that I didn't push it to the background; to be honest I would not know how to do it.
-
Yes, I restarted the Pi after copying. Also set up a ubuntu VM to test and I am having the same issues. Just ran it as root user and sadly it did not help
-
Thanks for the quick reply! I was using the ssh_host_rsa_key and want to have the Pi as my destination. I opened the lucky backup terminal and copied the key using "scp ssh_host_rsa_key.pub [email protected]:/tmp" and then ran "cat /tmp/ssh_host_rsa_key.pub >> /home/pi/.ssh/authorized_keys" on the Pi. My luckyBackup task looks like this. After clicking validate, I got a Segmentation fault ("/opt/scripts/start-server.sh: line 82: 113 Segmentation fault /usr/bin/luckybackup") and the container restarted.
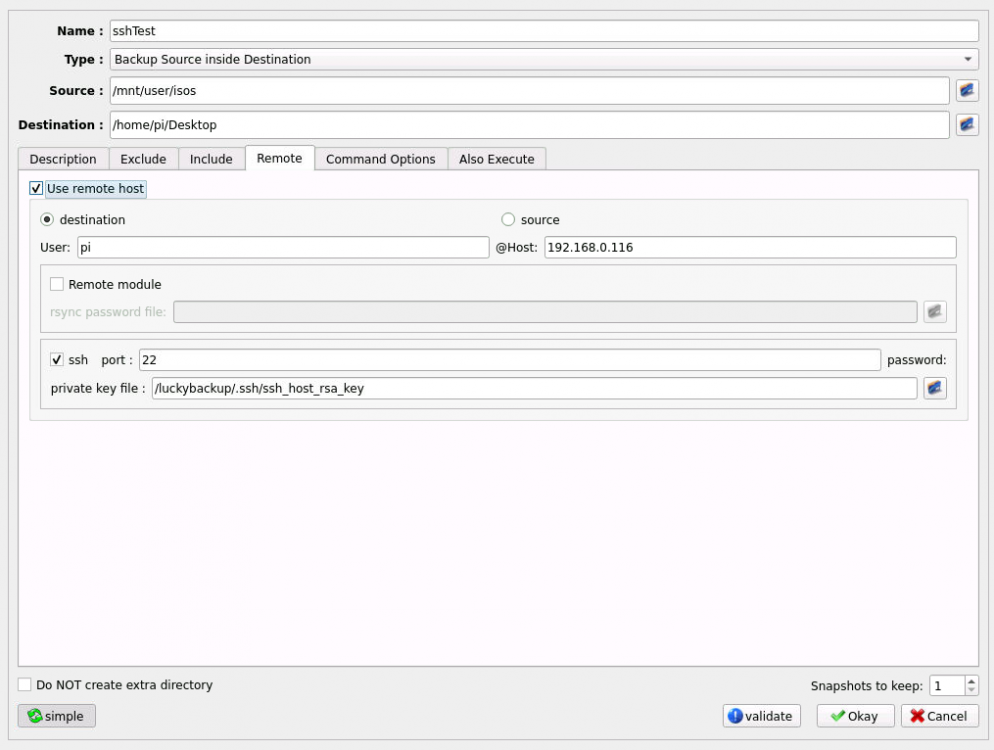
-
Hello First of all, thanks for creating so many useful dockers! I want to create an offsite backup using the luckyBackup docker and connect to a raspberry (running raspian) using ssh. I read (in a german thread) that I should be able to use the ssh keys within the docker itself (/luckybackup/.ssh) and copy them using scp or ssh-copy-id. My first problem is that even after copying the public keys onto the pi, I am still prompted to enter the password when ssh-ing into the pi from the luckyBackup console. My more important problem: when I create a task and check the boxes for "Use remote host" and "ssh", enter the port and the private key location and click "validate" or "okay", the docker crashes with a segmentation fault, e.g.: "/opt/scripts/start-server.sh: line 82: 107 Segmentation fault /usr/bin/luckybackup" And the container restarts automatically. Any help would be appreciated!
-
I reinstalled the mariadb, swag and nextcloud dockers and nothing changed. I don't really know what to try now. I will keep you posted if I can up the speed somehow. EDIT: I tested around somemore and found out that I get the expected connection speed from outside my local network (e.g. connecting to a VPN and then to my nextcloud over its duckdns IP)
-
Okay, thanks for the info. In this case, I am just going to try a fresh install of the dockers and see if that changes anything.
-
Hey Guys, I installed nextcloud following the instructions of spaceinvader one with MariaDB and SWAG (using a duckdns IP). My problem is that when using the duckdns IP, my connection speed to my nextcloud is averaging at about 100 Kbyte/s. When connecting locally, my connection speed is higher and what I would I expect from a gigabit ethernet cable. My ISP up/down speed is 200/20 Mbit/s (which do reach the server), so from my understanding I would expect a connection speed of around 2.5 Mbyte/s (minus some tolerance). Do you guys have any ideas on how I can improve my connection speed? I guess that it is related to SWAG?

