

REllU
-
Posts
88 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by REllU
-
-
On 6/19/2022 at 2:05 AM, TheIronAngel said:
I have managed to resolve this issue on my system.
My resolution was:
1: Edit VM, set to VNC only, verify normal operation, shut down VM - Do not edit config back to GPU passthrough.
2: Navigate to: Tools -> System Devices
3: In the "PCI Devices and IOMMU Groups" section find the IOMMU group that contains the video card and select the check box next the IOMMU Group number, scrool down and click 'Bind Selected to VFIO At Boot'

4: Restart Unraid, after restart, edit VM to have the GPU that was just bound on startup.
Just dropping a comment here, thank you!
I've had plenty of issues with the VM's not wanting to restart properly unless I restart the entire server.
Symptoms (for whoever is currently googling them and pulling their hair) are that, once the VM is restarted (or shut down, and then booting it up, for example when trying to update Windows), the first CPU that's allocated to the VM is stuck at 100%, and there's no signal through a monitor, and I was also unable to ping the VM.
-
34 minutes ago, alturismo said:
may try chmod or chown the file from the terminal ?
chown 99:100 /mnt/user/appdata/Filebrowser/database.db <- change this to the path on your mashine
or
chmod 777 /mnt/user/appdata/Filebrowser/database.db <- change this to the path on your mashine
as note, working fine here ...
Thank you so much! You just saved my hair, and my weekend!
")
I'm not quite sure what happened here, as our backup server went through the same update just a week ago, and FileBrowser seemed to work just fine there. Whatever the case may be, chown seemed to be the answer here. Thank you for the quick answer!
-
 1
1
-
-
After updating my UnRaid server from 6.9.2 to 6.11.0, the FileBrowser docker seems to have stopped working.
The issue is that FileBrowser cannot access the database file:
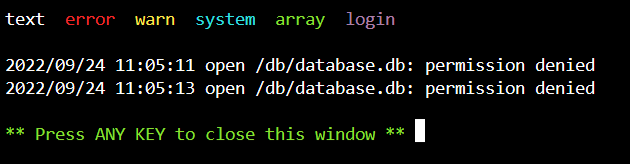
To confirm this, I changed the path to the database.db file from the container settings, which resulted in a new database file to be created, and the FileBrowser docker to be fully functional again. Though, without any of my settings and user data etc.
Is there a way to grant permission to the FileBrowser to it's original database.db file?
Worst case scenario, I can always manually set up the docker again, but that's a bit of a pain in the butt.
-
Just dropping a message here, in case someone needs to see it.
I recently lost access to FileBrowser through the net. This was because of an expired SSL certificate.
I wasn't able to renew the certificate within Nginx Proxy Manager either.
To fix this, I changed the scheme within Nginx Proxy Manager to HTTP instead of HTTPS (which previously worked fine, for whatever reason)
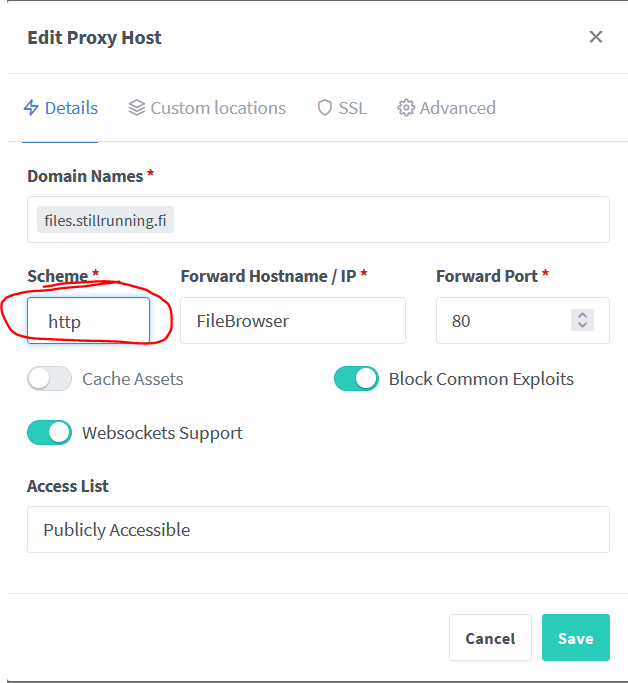
Maybe this'll save a few hours of hair pulling from someone
")
-
1 minute ago, mgutt said:
It's simple. If you open the GUI of the Container directly, does it use http, then use http in NPM. Finally it's absolutely nonsense to use https between NPM an the target container.
Opening the container's ip:port on Firefox doesn't show https on the front of the address (which it does for containers like UniFi), and really, from the testings I've done now, it's probably safe to say that FileBrowser uses HTTP.
As for the nonsense, good to know!
 3 minutes ago, mgutt said:
3 minutes ago, mgutt said:I'd say Filebrowser had an update which removed access through https/443.
Definitely a possibility. However, access to my FileBrowser was disabled due to expired certificate? It makes sense, that the Nginx wasn't able to renew the certificate, because it couldn't access the FileBrowser container, but such an update _should've_ disabled the access to FileBrowser (through the net) all together? 🤔
5 minutes ago, mgutt said:This is not a good idea as Let's Encrypt needs http/80 to validate certificates.
Just tested this before I read your message. For whatever reason, renewing the certificate seemed to work just fine?
Port 80 isn't disabled all together btw, what I meant was that I disabled the port-forward rule for port 80, as that was previously pointing to FileBrowser.
From really quick testing, everything _seems_ to be working just fine right now. Seems that all of this was simply caused by the wrong protocol. 🥴
-
30 minutes ago, mgutt said:
That's really strange as http is working. Do you have any advanced rules which cover https/443 traffic?
What happens if you open https://your.public.ip ? It should return "ERR_HTTP2_PROTOCOL_ERROR" as no SSL certificate is provided by NPM.
SpoilerThe only rule I have for 443 port in Ubiquiti, is this:

Just tried to shut down Nginx completely, and even then http:// mydomain . com - works fine, so it seems to skip Nginx entirely.
I do have a rule for port 80 within my router, currently pointing to FileBrowser, so that makes sense.
Trying to open https:// public_ip - Just results in a timeout. If there's a log file somewhere that you'd like to see about this, just point me into the right direction, and I'll dig it up for you (apologies, networking isn't my strongest suit)
EDIT:
I had Nginx stopped when I tried to access https:// public_ip
With Nginx running, I'm getting the (original issue from yesterday) potential security risk, which would point out for an invalid certificate.
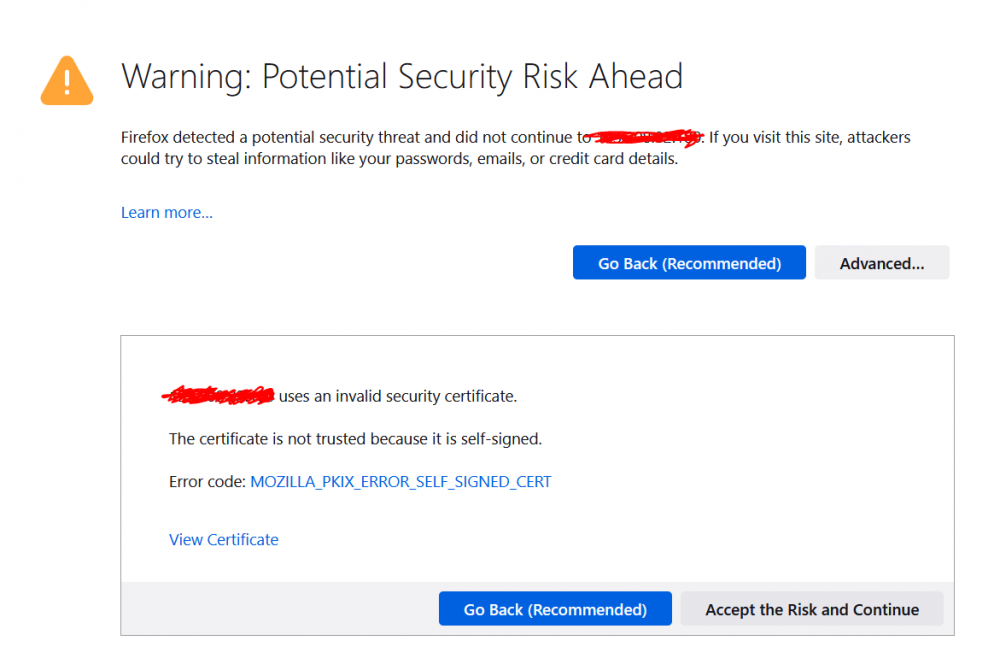
Trying to continue from here gives me an "Secure connection failed"
Apologies for the amount of edits. There's so many variables with testing these things.
Edit 3:
I've now tried to change the protocol to HTTP instead of HTTPS within Nginx, as I'm not really sure what protocol FileBrowser want's to use.
Turns out, this seems to work from quick on/off testing. I'm a bit confused as to why HTTPS worked just fine with the last Nginx container I had, but not here?
Going to the certificates tab within Nginx, and testing the reachability of the server seems to still give me the same error as before. So I'm guessing renewing the certificates will still be an issue.
Edit 4:
Disabling the port-forward rule for port 80 within my router seems to still work.
Doing this however, does give me a different result in reachability test, which is now stating that there is no server.
-
13 hours ago, mgutt said:
First page, read the 5xx error paragraph.
Rightyo! Let's see..
4.) Does NPM reach your target container?
Nope. Nginx container is in br0, and wasn't able to connect to FileBrowser, since that was in Bridge mode.
Changing FileBrowser into br0 as well, allows Nginx to connect to it succesfully.
I've then changed the port forward rule to reflect this change, which seems to work fine.
However, the situation is still very much the same:
✔️ http://[my-public-ip] (Skipping Nginx entirely)
✔️[FileBrowser_ip]:[FileBrowser_port] (Skipping Nginx entirely)
✔️Connection between Nginx and FileBrowser (with br0 network)
✔️http:// domain . com
❌https:// domain . com (results in bad gateway)
❌Server reachability test (Within Nginx)
I've only now jumped to the official docker image of the Nginx Proxy Manager, previously, I was rocking the jlesage's docker image, which has server me well up until the issue yesterday with renewing certificates. It was also using Bridge-network mode.
I read somewhere about potential issues with that particular docker image, and I figured I'd try this one out, just in case 🤷♂️
I feel like I'm just missing something obvious here.
-
45 minutes ago, mgutt said:
Open the containers console and check the last entries:
tail -n200 /var/log/letsencrypt/letsencrypt.log
Here's what I've got:Spoiler# tail -n200 /var/log/letsencrypt/letsencrypt.log 2022-02-11 19:02:40,778:DEBUG:certbot._internal.main:certbot version: 1.22.0 2022-02-11 19:02:40,779:DEBUG:certbot._internal.main:Location of certbot entry point: /usr/bin/certbot 2022-02-11 19:02:40,779:DEBUG:certbot._internal.main:Arguments: ['--non-interactive', '--quiet', '--config', '/etc/letsencrypt.ini', '--preferred-challenges', 'dns,http', '--disable-hook-validation'] 2022-02-11 19:02:40,779:DEBUG:certbot._internal.main:Discovered plugins: PluginsRegistry(PluginEntryPoint#manual,PluginEntryPoint#null,PluginEntryPoint#standalone,PluginEntryPoint#webroot) 2022-02-11 19:02:40,789:DEBUG:certbot._internal.log:Root logging level set at 40 2022-02-11 19:02:40,791:DEBUG:certbot._internal.display.obj:Notifying user: Processing /etc/letsencrypt/renewal/npm-8.conf 2022-02-11 19:02:40,804:DEBUG:certbot._internal.plugins.selection:Requested authenticator <certbot._internal.cli.cli_utils._Default object at 0x14e5136e0b38> and installer <certbot._internal.cli.cli_utils._Default object at 0x14e5136e0b38> 2022-02-11 19:02:40,804:DEBUG:certbot._internal.cli:Var pref_challs=dns,http (set by user). 2022-02-11 19:02:40,804:DEBUG:certbot._internal.cli:Var preferred_chain=ISRG Root X1 (set by user). 2022-02-11 19:02:40,804:DEBUG:certbot._internal.cli:Var key_type=ecdsa (set by user). 2022-02-11 19:02:40,804:DEBUG:certbot._internal.cli:Var elliptic_curve=secp384r1 (set by user). 2022-02-11 19:02:40,805:DEBUG:certbot._internal.cli:Var webroot_path=/data/letsencrypt-acme-challenge (set by user). 2022-02-11 19:02:40,805:DEBUG:certbot._internal.cli:Var webroot_map={'webroot_path'} (set by user). 2022-02-11 19:02:40,805:DEBUG:certbot._internal.cli:Var webroot_path=/data/letsencrypt-acme-challenge (set by user). 2022-02-11 19:02:40,823:DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): r3.o.lencr.org:80 2022-02-11 19:02:40,890:DEBUG:urllib3.connectionpool:http://r3.o.lencr.org:80 "POST / HTTP/1.1" 200 503 2022-02-11 19:02:40,892:DEBUG:certbot.ocsp:OCSP response for certificate /etc/letsencrypt/archive/npm-8/cert1.pem is signed by the certificate's issuer. 2022-02-11 19:02:40,893:DEBUG:certbot.ocsp:OCSP certificate status for /etc/letsencrypt/archive/npm-8/cert1.pem is: OCSPCertStatus.GOOD 2022-02-11 19:02:40,897:DEBUG:certbot._internal.display.obj:Notifying user: Certificate not yet due for renewal 2022-02-11 19:02:40,898:DEBUG:certbot._internal.plugins.selection:Requested authenticator webroot and installer None 2022-02-11 19:02:40,898:DEBUG:certbot._internal.display.obj:Notifying user: - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 2022-02-11 19:02:40,898:DEBUG:certbot._internal.display.obj:Notifying user: The following certificates are not due for renewal yet: 2022-02-11 19:02:40,898:DEBUG:certbot._internal.display.obj:Notifying user: /etc/letsencrypt/live/npm-8/fullchain.pem expires on 2022-05-12 (skipped) 2022-02-11 19:02:40,898:DEBUG:certbot._internal.display.obj:Notifying user: No renewals were attempted. 2022-02-11 19:02:40,898:DEBUG:certbot._internal.display.obj:Notifying user: - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 2022-02-11 19:02:40,899:DEBUG:certbot._internal.renewal:no renewal failures
However, I'm not exactly in the same spot anymore, as I was with the previous message.
I got the certificate to renew itself by changing the port-forward rules, so that from port 80, instead of it being directed to FileBrowser, it was instead directed at Nginx docker.
This, however, created a "Bad gateway" error, which I'm now struggling with.

I've since changed the port forward rules back to what they were, so port 80 is now directed to FileBrowser again. But the result is the same.
I'm also getting the same result with the reachability test.
Thank you for the quick response! Appreciate it
-
Hey there,
I've set up an Nginx proxy to an FileBrowser docker (and previously NextCloud) about a year ago, and so far everything has been working like a dream.
Until yesterday >.<
Not sure what happened, and when, but Nginx wasn't able to auto-renew the SSL certificate for my domain. I only noticed this yesterday, when I wasn't able to connect to the FileBrowser from the net anymore.
I've tried to "manually" (as in, from the Nginx GUI) renew the certificate, but it keeps failing.
On certain browsers (like Samsung's own web app, which doesn't seem to give two hoots about secure connections) I can connect to the FileBrowser docker just fine.
I also created a new domain, and new Nginx proxy host to my FileBrowser docker, without the SSL certificates, just to test if the connection is good. It is.
This is what I'm getting from the Docker log (inside of UnRaid) when I try to renew the certificate:
Internal Error Error: Command failed: certbot certonly --config "/etc/letsencrypt.ini" --cert-name "npm-6" --agree-tos --authenticator webroot --email "[EMAIL HERE]" --preferred-challenges "dns,http" --domains "[EMAIL HERE]" Saving debug log to /var/log/letsencrypt/letsencrypt.log Some challenges have failed. Ask for help or search for solutions at https://community.letsencrypt.org. See the logfile /var/log/letsencrypt/letsencrypt.log or re-run Certbot with -v for more details. at ChildProcess.exithandler (node:child_process:397:12) at ChildProcess.emit (node:events:390:28) at maybeClose (node:internal/child_process:1064:16) at Process.ChildProcess._handle.onexit (node:internal/child_process:301:5)The external log files I can't seem to find anywhere 🤔
Trying to test the server reachability, I get:
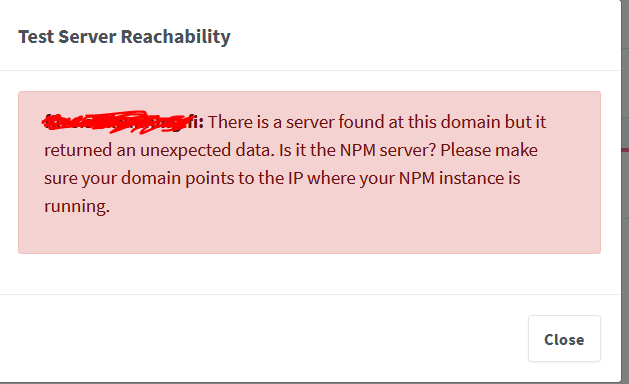
Any help would be appreciated!
-
On 12/12/2021 at 9:14 PM, Ntouchable said:
I have had this same issue with "files_external" since upgrading past Nextcloud 21 and have been using the same fix quoted above each time I upgrade to a new version.
I have since updated to Nextcloud 23.0.0 and this fix still works to get the system out of maintenance mode, such that I can access the web interface.
However, "External storages" now can no longer connect to my Unraid shares and Nextcloud shows the following error.
Has anyone else had this issue?
{"reqId":"wOPQlpFXU3Kh1M7Ok3YO","level":3,"time":"2021-12-12T19:10:00+00:00","remoteAddr":"172.18.0.4","user":"admin","app":"index","method":"GET","url":"/apps/files_external/globalstorages/11?testOnly=true","message":"Class 'Icewind\\SMB\\BasicAuth' not found in file '/config/www/nextcloud/apps/files_external/lib/Lib/Backend/SMB.php' line 79","userAgent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36","version":"23.0.0.10","exception":{"Exception":"Exception","Message":"Class 'Icewind\\SMB\\BasicAuth' not found in file '/config/www/nextcloud/apps/files_external/lib/Lib/Backend/SMB.php' line 79","Code":0,"Trace":[{"file":"/config/www/nextcloud/lib/private/AppFramework/App.php","line":157,"function":"dispatch","class":"OC\\AppFramework\\Http\\Dispatcher","type":"->"},{"file":"/config/www/nextcloud/lib/private/Route/Router.php","line":302,"function":"main","class":"OC\\AppFramework\\App","type":"::"},{"file":"/config/www/nextcloud/lib/base.php","line":1006,"function":"match","class":"OC\\Route\\Router","type":"->"},{"file":"/config/www/nextcloud/index.php","line":36,"function":"handleRequest","class":"OC","type":"::"}],"File":"/config/www/nextcloud/lib/private/AppFramework/Http/Dispatcher.php","Line":158,"Previous":{"Exception":"Error","Message":"Class 'Icewind\\SMB\\BasicAuth' not found","Code":0,"Trace":[{"file":"/config/www/nextcloud/apps/files_external/lib/Controller/StoragesController.php","line":250,"function":"manipulateStorageConfig","class":"OCA\\Files_External\\Lib\\Backend\\SMB","type":"->"},{"file":"/config/www/nextcloud/apps/files_external/lib/Controller/StoragesController.php","line":264,"function":"manipulateStorageConfig","class":"OCA\\Files_External\\Controller\\StoragesController","type":"->"},{"file":"/config/www/nextcloud/apps/files_external/lib/Controller/StoragesController.php","line":346,"function":"updateStorageStatus","class":"OCA\\Files_External\\Controller\\StoragesController","type":"->","args":["*** sensitive parameters replaced ***"]},{"file":"/config/www/nextcloud/lib/private/AppFramework/Http/Dispatcher.php","line":217,"function":"show","class":"OCA\\Files_External\\Controller\\StoragesController","type":"->"},{"file":"/config/www/nextcloud/lib/private/AppFramework/Http/Dispatcher.php","line":126,"function":"executeController","class":"OC\\AppFramework\\Http\\Dispatcher","type":"->"},{"file":"/config/www/nextcloud/lib/private/AppFramework/App.php","line":157,"function":"dispatch","class":"OC\\AppFramework\\Http\\Dispatcher","type":"->"},{"file":"/config/www/nextcloud/lib/private/Route/Router.php","line":302,"function":"main","class":"OC\\AppFramework\\App","type":"::"},{"file":"/config/www/nextcloud/lib/base.php","line":1006,"function":"match","class":"OC\\Route\\Router","type":"->"},{"file":"/config/www/nextcloud/index.php","line":36,"function":"handleRequest","class":"OC","type":"::"}],"File":"/config/www/nextcloud/apps/files_external/lib/Lib/Backend/SMB.php","Line":79},"CustomMessage":"--"}}Exception: Class 'Icewind\SMB\BasicAuth' not found in file '/config/www/nextcloud/apps/files_external/lib/Lib/Backend/SMB.php' line 79 /config/www/nextcloud/lib/private/AppFramework/App.php - line 157: OC\AppFramework\Http\Dispatcher->dispatch() /config/www/nextcloud/lib/private/Route/Router.php - line 302: OC\AppFramework\App::main() /config/www/nextcloud/lib/base.php - line 1006: OC\Route\Router->match() /config/www/nextcloud/index.php - line 36: OC::handleRequest() Caused by Error: Class 'Icewind\SMB\BasicAuth' not found /config/www/nextcloud/apps/files_external/lib/Controller/StoragesController.php - line 250: OCA\Files_External\Lib\Backend\SMB->manipulateStorageConfig() /config/www/nextcloud/apps/files_external/lib/Controller/StoragesController.php - line 264: OCA\Files_External\Controller\StoragesController->manipulateStorageConfig() /config/www/nextcloud/apps/files_external/lib/Controller/StoragesController.php - line 346: OCA\Files_External\Controller\StoragesController->updateStorageStatus("*** sensiti ... *") /config/www/nextcloud/lib/private/AppFramework/Http/Dispatcher.php - line 217: OCA\Files_External\Controller\StoragesController->show() /config/www/nextcloud/lib/private/AppFramework/Http/Dispatcher.php - line 126: OC\AppFramework\Http\Dispatcher->executeController() /config/www/nextcloud/lib/private/AppFramework/App.php - line 157: OC\AppFramework\Http\Dispatcher->dispatch() /config/www/nextcloud/lib/private/Route/Router.php - line 302: OC\AppFramework\App::main() /config/www/nextcloud/lib/base.php - line 1006: OC\Route\Router->match() /config/www/nextcloud/index.php - line 36: OC::handleRequest()I got the same issue, and asked for help quite a while ago.
Long story short, I decided to move to a docker called "FileBrowser"
It was rather easy to setup, with a little help from a chinese video, and it's been working flawlessly ever since I set it up! As an added bonus, downloading files bigger than 1gb is actually possible straight out of the box with FileBrowser (I never got that to work with NextCloud)
-
23 hours ago, alturismo said:
may try this

should solve the most issues ...
This seems to have done the trick for me, thanks!
-
On 10/13/2021 at 11:35 AM, PicPoc said:
Hi !! How did you fixed the problem ? If it's fixed...
Thanks !
On 10/4/2021 at 7:42 PM, knex666 said:Yep thats very weak. I am running a cron script that edits my filerights every some minutes. Thats not good but good enough
I don't know what the script is though, but probably shouldn't be too hard to create one on your own 🤷♂️
-
15 hours ago, knex666 said:
Yep thats very weak. I am running a chron script that edits my filerights every some minutes. Thats not good but good enough
Hah, that would actually be good enough for our use, as 95% of the time we're using the files through SMB, and only 5% (whenever someone is working from home, and they're creating new folders) is used with FileBrowser.
Mind sharing the script you did?
-
On 5/16/2021 at 11:16 AM, gafka said:
Hi! I'm using this FileBrowser docker image. I've used the flag --user 99:100 but since umask is 0022 instead of unraid's default 0000, any file/folder created using FileBrowser can only be written by user "nobody".
This means that when accessing my shares via SMB I cannot edit the files or directories created in FileBrowser.
Is there any way to change the default umask value in the container? I know some images have this option built in, but it is not the case with this one.
Did you find a way to get this working?
-
25 minutes ago, ich777 said:
Not really I think, I have to pull up the issue that you've created over on SourceForge but the developer doesn't answered yet to my last question, maybe he was affected by the fires over in Greece.
Either that, or he's just not too concerned about a free piece of software he created a long time ago

I tried the "refresh" button just now, and unfortunately, no dice

First, I ran the job through user-scripts, and opened the "manage backups" button, to see if the issue was still there (just in case)
It was, so now I pressed the "refresh" button. That didn't work, and the backup wasn't updated.
Then, I tried to run the cron-job again, and now, I tried to click on the "refresh" before opening the "manage backups" (since this is how it works with changing the profiles as well) and nothing.
Just to check I wasn't crazy, I tried it my way, running the cron-job, and then switching between two profiles, and checking the "manage backups", and it worked just fine.
-
 1
1
-
-
4 minutes ago, ich777 said:
Doesn't this do the same or better speaking update the backups?
It does sound like it, since it would refresh the profiles 🤔
Would there be a command that could be ran after the profile, to refresh the profiles automatically? 🤔
-
17 hours ago, shinfo44 said:
Deleting the log files, changing the docker image, etc. in the above posts do not work for me. Would be really great if someone can help me out. I got the ".ocdata" error, but I am also just not able to access the webUI at all. I use NextCloud as a backup solution for my households phones, so it would be great to get this running again...
I don't have the answer for your issue, but I'm using an app called "AutoSync" on our household phones. Cost's like 7eur to get the license to use it with an SMB share, and you can set it to sync automatically any folders you want when you're connected to a specific wifi. Has been working nicely for our needs atleast.
-
1
-
-
(Old issue, before updating)
SpoilerUpgraded my UnRaid hardware over the weekend, and noticed that now NextCloud is unable to access SMB shares.
Anyone have any ideas what's up with that?
The shares themselves seem to be fine, as I can access them through network.
I upgraded the motherboard, RAM, and CPU.
With SMB test- app, I'm getting the following errors:
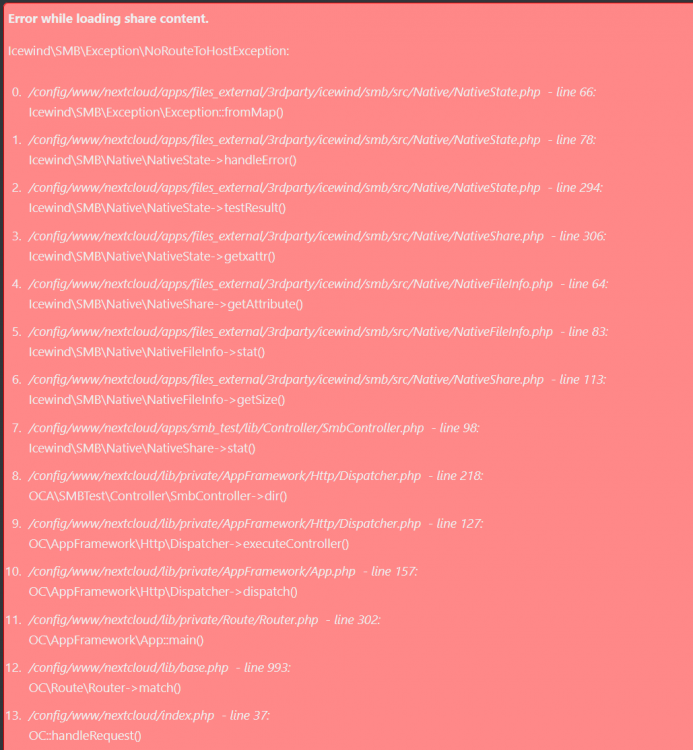
I updated the docker image, but I haven't updated NextCloud itself in a while. The last update broke the SMB shares in such a way, that I had to download the previous version of NextCloud, and import the "icewind" from the older version to the new one, to get it to work again.
EDIT: (Internal server error, fixed in the next edit)
SpoilerSo, I figured I have not much to lose, and tried to update NextCloud, and I'm having the same issue as many others in here.
Internal Server Error.
I've tried to update MariaDB, and tried to delete the ib_logfile0, and tried to change the repository of MariaDB, but nothing seems to work there.
Again, any help would be appreciated.
EDIT2: (Fixing the internal server error, and back to square one)
SpoilerReading through the log-file, I noticed something familiar. The files_external was giving me issues again, so I tried to remove the app folder, and ta-dah! I was able to access my NextCloud yet again.
I then tried to do the same trick I did the last time around:
And.. I'm back to square one.
So, I can access the NextCloud, but NextCloud cannot access the SMB shares.
EDIT3:
NextCloud is amazing for what it's trying to achieve, when it works. But it has just given me way too many headaches, and it's pretty much overkill for what I want to do with it (accessing files through the internet) that I've now decided to move to "FileBrowser" docker instead. Setting that up took me 10 minutes without really knowing what to do, and it's been working nicely (knock on wood), and even issues that we previously had (not being able to download files over 1gb) are now gone.
Good luck all of you UnRaider's, who're battling with NextCloud!
-
1 minute ago, ich777 said:
The reboot switch doesn't work, that I can tell for sure but if you run it through user scripts you can simply do: 'docker luckyBackup restart'
Right, in that case, I could just have a restart every day through the user scripts, after the backup work is done :thinking:
Thanks!-
1
-
-
4 minutes ago, ich777 said:
A simple restart from the container after a backup should do the jop too from what I know.
I'm in a middle of a backup right now (doing a server upgrade), but yeah. I realized after posting, that there's an option to reboot the LuckyBackup after it's done it's cron-job, which should do the same effect. I'll try that later.
-
Hey, again!
I think I stumbled upon a solution by accident for the (LuckyBackup) cron-job not working with the snapshot files!
I created a new profile, that I wanted to run every hour or so (for our security cameras, to backup their video footage remotely)
While I was doing this, I noticed that the snapshot files were updated successfully!
Here's basically the step-by-step on how to get it to work:
1. You need another profile.
2. Set up your cron-jobs the way you want (either within the LuckyBackup itself, or with User Scripts.)
3. Let the cron-job run as it should.
4. Before checking the "manage backup" button within LB, change the profile, and then go back to the profile you're using
5. Check the "manage backup" button, and ta-dah! The snapshot should be updated correctly!
Somewhat useless rambling.
SpoilerI'm probably going to try to create a useless-profile now, and just keep the GUI "locked" on to that profile. Hopefully, this'll allow LuckyBackup to manage multiple snapshots correctly, without me switching between the profiles daily.
This would also explain why for some users the cron-jobs are working exactly as intended, and for some (me included) were having issues with it. I never had another profile until now, so I wasn't swapping between them!
EDIT: I just tested this with a "useless" profile.
So I set the GUI to be on this other profile, then I ran the user-script within UnRaid to run the cron-job every minute for three times. And yes! It did work! Every one of those three snapshots were saved successfully within the LuckyBackup, and were shown in the GUI!
-
On 8/17/2021 at 4:20 PM, REllU said:
Downloading files larger than around 1gb always seem to fail from my NextCloud.
I'm using a Ubiquiti USG as my router, I have NextCloud 21.0.1 up and running on UnRaid 6.9.2. PHP Version is currently 7.4.15
Everything else (from what I can tell) is working just fine, and has been for months.
To me, this seems like some sort of a setting / limitation somewhere, since the download always seems to stop at that 1gb mark.
Any help would be appreciated!
This one slipped through the cracks, just bumping it up
EDIT: I think I found the solution, but unsure on how to apply it..
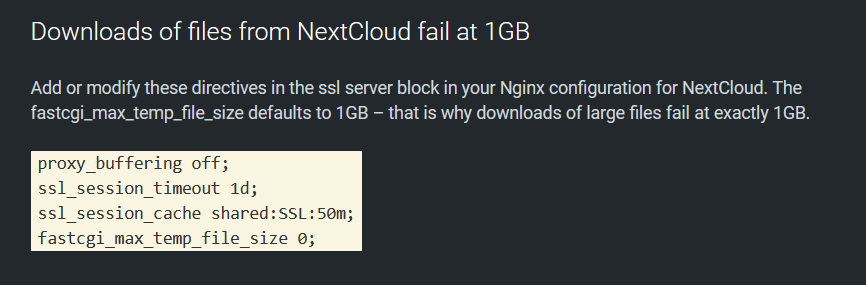
I'm using Nginx Proxy Manager on UnRaid, if that makes any difference.
The solution I was able to find from here:
https://autoize.com/nextcloud-performance-troubleshooting/
If someone could point me into the right direction, that'd be great!
-
39 minutes ago, ich777 said:
Please check if the 7th profile has anything in it that crashes luckyBackup.
Maybe try deleting the 7th and 8th task and after that try it again with anythin on your server just for testing purpouses.
As said above I have abou 15tl tasks in the default profile with no issue whatsoever.
I did try deleting some task's, and creating new ones, resulting in same behavior. Don't know if it's related, and I couldn't really test it, but with previous versions creating new task's wasn't an issue.
Could you try creating a 16th task, and see if that works for you or not?
-
49 minutes ago, ich777 said:
Does the Validation and Okay button always crash luckyBackup or do I get this wrong?
Also do you mean 7 tasks or profiles, only asking because I have luckyBackup on my Backup server with about 15 tasks each one of the 15 tasks over SSH.
I originally had only one profile, and I had 7 task's on it. I tried to add a new one, and the app crashed.
I then duplicated the default profile, to try this on another profile, and the crash happened again.
On this duplicate profile, I then tried to remove one of the task's, and add a new one. Adding the 7th task went OK (though, once I saved the profile, the app crashed) After this, I tried to add an 8th task into the new profile, and a crash happened again.













[Support] Rocket.Chat
in Docker Containers
Posted · Edited by REllU
Added a GitHub link
EDIT:
Seems that this is my issue. Or atleast part of it:
https://github.com/RocketChat/Rocket.Chat/issues/29382
Original message below:
Here to see if anyone else is experiencing similar oddities..
I seem to have a-lot of issues with files currently. I'm using File System as my storage type, which has been working just fine the past few months.
However, now I'm getting "ENOENT: no such file or directory, stat '/app/uploads//647df273c68d8a46579c7e20'"
Uploading files seems to be working fine. Issue comes when someone is trying to view the file, or delete the file.
A bit of backstory
It started from trying to create a new Team inside the Rocket.Chat, uploading an avatar to said Team, and then removing the avatar in order to replace it with something else.
I noticed that I wasn't able to upload another avatar anymore, so I figured I'd just delete the Team, and start again.
However, now the Team was "gone", but I wasn't able to create another one, since Rocket.Chat was determined that there was already a Team with the same name. I was unable to access it anywhere else, except in the settings menu, where I saw the Team. When trying to remove the Team there, it only resulted in more errors.
Now however, everything related to files uploaded to Rocket.Chat, are behaving.. oddly.
I haven't been able to really pinpoint the issue yet, but basically, only some of my files are loaded, in some client applications. This is very weird, as some files can be loaded on one Client app (such as Windows app, web-app, or mobile app) but for example a file that was uploaded through Android app, was only being displayed on the Web version.
I've recently updated our Rocket.Chat to 6.2, which could be the culprit. But very un-sure.
I've now been googling and banging my head against the wall for half of today, and I haven't really been finding anything.
If anyone's interested, here's the whole error from trying to delete a file:
{"level":50,"time":"2023-06-05T17:23:47.195Z","pid":1,"hostname":"b1850019346f","name":"System","msg":"Exception while invoking method deleteMessage","err":{"type":"Error","message":"ENOENT: no such file or directory, stat '/app/uploads//647df273c68d8a46579c7e20'","stack":"Error: ENOENT: no such file or directory, stat '/app/uploads//647df273c68d8a46579c7e20'\n => awaited here:\n at Function.Promise.await (/app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/promise_server.js:56:12)\n at server/ufs/ufs-local.ts:72:20\n at /app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/fiber_pool.js:43:40\n => awaited here:\n at Function.Promise.await (/app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/promise_server.js:56:12)\n at server/ufs/ufs-store.ts:230:3\n at /app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/fiber_pool.js:43:40\n => awaited here:\n at Function.Promise.await (/app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/promise_server.js:56:12)\n at server/ufs/ufs-local.ts:76:5\n at /app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/fiber_pool.js:43:40\n => awaited here:\n at Function.Promise.await (/app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/promise_server.js:56:12)\n at app/file-upload/server/lib/FileUpload.ts:677:4\n at /app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/fiber_pool.js:43:40\n => awaited here:\n at Function.Promise.await (/app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/promise_server.js:56:12)\n at app/lib/server/functions/deleteMessage.ts:48:13\n at /app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/fiber_pool.js:43:40\n => awaited here:\n at Function.Promise.await (/app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/promise_server.js:56:12)\n at app/api/server/v1/misc.ts:557:17\n at /app/bundle/programs/server/npm/node_modules/meteor/promise/node_modules/meteor-promise/fiber_pool.js:43:40","errno":-2,"code":"ENOENT","syscall":"stat","path":"/app/uploads//647df273c68d8a46579c7e20"},"msg":"ENOENT: no such file or directory, stat '/app/uploads//647df273c68d8a46579c7e20'"}