




REllU
Members
-
Joined
-
Last visited
Everything posted by REllU
-
For me, the issue was actually in the advanced view settings. To fix a similar issue in the past, I had added " -- user 99:100" string to the Extra Parameters , but this time the fix was other way around. For whatever reason, the container did not want to start unless I actually emptied the "Extra Parameters" section, like so: After this, worked like before. Also I'd like to note, that running "New Permissions" as suggested above, could break permissions for other Docker containers. So use with care, or even better, go through the "shares" tab, navigate to AppData, and then change the permissions and owner for only the FileBrowser folder through there to not mess anything else up.

-
I was actually unaware that different networks conflict with each others' ports! Appreciate the help btw, thank you. docker network inspect br0 [ { "Name": "br0", "Id": "3b46963ae1a3fea1cbc75b8b845d904730c98d7cd133c6dec35e71fc27b81f86", "Created": "2025-06-23T15:20:59.682209732+03:00", "Scope": "local", "Driver": "ipvlan", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "192.168.1.0/24", "Gateway": "192.168.1.1", "AuxiliaryAddresses": { "server": "192.168.1.198" } } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "18fb80f6b1e3307e4b181186987c95afc1f61f476daa0bd69036ccf61fd86ca9": { "Name": "GiteaSQL", "EndpointID": "cc55edf9dea1f0483ab1e36c1c55c6936699b4e1195d948587f7e3304bdddec7", "MacAddress": "", "IPv4Address": "192.168.1.250/24", "IPv6Address": "" }, "268d078be482c4d8b1f393063a826c47faaa2489a0fec97380aad333b100a2fd": { "Name": "LeantimeSQL", "EndpointID": "7cf263ee21e2779f24f6ec4d5869cd0b96cf5e82d2f10b6a515da85fda7a4f0e", "MacAddress": "", "IPv4Address": "192.168.1.6/24", "IPv6Address": "" }, "3f44a8664e40b363aae874512a18e3add7cbe2820e3a40df32d37dd82132367c": { "Name": "FileBrowser", "EndpointID": "367f7ab3143b3785bf767f82f9ed739799c0e74a588361a7d50119de0b204b64", "MacAddress": "", "IPv4Address": "192.168.1.5/24", "IPv6Address": "" }, "523f2300e564cb373fb50a385077b5f11494f1177de144e0cae928e5019904b3": { "Name": "Gitea", "EndpointID": "2f34f6cb1cee700b036cea1aa05c1dd77c874749ab3b7795130faabc05df7977", "MacAddress": "", "IPv4Address": "192.168.1.251/24", "IPv6Address": "" }, "6ae369e3b771aaa4d3f32f2f3babccb577dbf84e0ade689b2b041e95dc93a680": { "Name": "Rocket.Chat", "EndpointID": "b9b1e7406f35a660acdac22c69bc446dd194ced3984841a3535494213bd3b26c", "MacAddress": "", "IPv4Address": "192.168.1.4/24", "IPv6Address": "" }, "8dbbe6d65a3660d79eca7e34abe53c328c248d50cdc4bd42a024d4cb654f14c1": { "Name": "leantime", "EndpointID": "a67f2ef552986bcfac4165789d0e9c7c0f3ae2ce9878bddb8407617ff9667655", "MacAddress": "", "IPv4Address": "192.168.1.7/24", "IPv6Address": "" }, "b15e6d4f2f8acf09ef02537babd4f366c9564c34e8539e7fe77370e4dfe7f333": { "Name": "MongoDB", "EndpointID": "5d63d3c21a2816c34d033d78536cdf715d3f63cd659e7c6a9bfa53966cb23de2", "MacAddress": "", "IPv4Address": "192.168.1.3/24", "IPv6Address": "" }, "b6b0ff486ce657c85193ad5cf7e07cb5cb7cf5426320a719ae4524090019e4a7": { "Name": "adminer", "EndpointID": "416dcece7e35b079dc6d2f4aab69625466231d1d32788b81d109a8b13556fa44", "MacAddress": "", "IPv4Address": "192.168.1.9/24", "IPv6Address": "" }, "cefd02bd9de8ff9bb357671d8a70c1713a3deec44fe283be0a3149e49a289c4c": { "Name": "Nginx", "EndpointID": "dd8f7e2f4d5d14ad39ad627677a5306d9a49d36d3e2e1b7aaa07b637fe8baf23", "MacAddress": "", "IPv4Address": "192.168.1.2/24", "IPv6Address": "" } }, "Options": { "parent": "br0" }, "Labels": {} } ] docker network inspect bridge [ { "Name": "bridge", "Id": "40c7dda0e142f389d8aaee05866e305c6903caba514df142c2186f9b9f1926f8", "Created": "2025-06-23T15:20:58.90293917+03:00", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": null, "Config": [ { "Subnet": "172.17.0.0/16", "Gateway": "172.17.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "4d0ae86f2752deafd64df9d2ac8dd540b2ef7d25b895e2e1abb01844d5ee755f": { "Name": "unifi-controller", "EndpointID": "6a550dde15e968d3410c243ed0ea98e1ec523f27909c9df39ffc9f32ba8f4a98", "MacAddress": "02:42:ac:11:00:03", "IPv4Address": "172.17.0.3/16", "IPv6Address": "" }, "a43140e66d055b33aad1a2a4db2e7c149f74fecca2a398ed028a676cd17b13b2": { "Name": "binhex-syncthing", "EndpointID": "ee1b090ea2314f1562786103137a07efbc4f80a72e0eddb5304c75b73f90f146", "MacAddress": "02:42:ac:11:00:02", "IPv4Address": "172.17.0.2/16", "IPv6Address": "" }, "c4ade02fb0bba273c5aa2ed683dfd02508452dbf63cc762ae3cb0df9dc272d41": { "Name": "luckyBackup", "EndpointID": "166558bfda1e188a93d4dbcb17dd36fe283a95065bc47e44c6dc6b494d7092e8", "MacAddress": "02:42:ac:11:00:04", "IPv4Address": "172.17.0.4/16", "IPv6Address": "" } }, "Options": { "com.docker.network.bridge.default_bridge": "true", "com.docker.network.bridge.enable_icc": "true", "com.docker.network.bridge.enable_ip_masquerade": "true", "com.docker.network.bridge.host_binding_ipv4": "0.0.0.0", "com.docker.network.bridge.name": "docker0", "com.docker.network.driver.mtu": "1500" }, "Labels": {} } ]
-
After the weekend, the earlier behaviour had returned. Connection to the (now) MariaDB database worked once, and then stopped working completely, once again stating "Connection refused" when trying to connect with Adminer. The original installation of MySQL (that was installed for another Docker container to use) works fine. Any help with this? The odd part is, if I re-install MySQL / MariaDB, it always works once. But after that, the connection refuses, which feels like the ports are fighting each other, which shouldn't be possible when using a custom network? EDIT: The plot thickens. If I restart Adminer with a different IP, it'll connect to the MariaDB database just fine. Once. After that, it'll get locked out with "Connection refused" So something allows a "new" app to connect to the database, but it'll somewhy get refused after it tries to connect again? :thinking: EDIT2: (the solution. But why?) This very clearly goes over my understanding, but I've (once again) seemingly fixed the issue. While trying to figure this out, I (for some reason) wanted to try and bring in a third installation of MySQL into the mix. Just to see what would happen. This installation worked just fine from the get go, and I was able to connect to the first and third installation through Adminer. This is where I had to bring in ChatGPT to make any sense of the situation, and after quite a bit of back-and-forth, it asked me to change the IP address of the second (broken) installation to something completely different, while keeping the same subnet. This worked, and it survived a full server restart. I asked ChatGPT as to why this is, and the answer it spit out was: That’s the strongest confirmation yet that this was, in fact, an ARP/MAC-level caching issue, and not a misconfiguration or database bug. Could someone smarter than me explain if this is the case, and how could I avoid this in the future? Will the change of the IP address fix this for me long term? (instead of .1-10 it's now .250)
-
@bmartino1 Thanks for the emotional support, and the help! I managed to fix the issue. I'm not even going to go through all the steps I did to get here, but deep down, I felt like something was really off somewhere deep, because I couldn't find anyone who had same issues than I, and everyone who asked "how to run multiple instances of MySQL / MariaDB" were given an answer of "just rename it" basically. Either way, as a last resort, I checked UnRaid's patch notes. And long behold, there were updates about Docker and networking. Not strictly about the issues I had, but close enough. So I made a backup, and updated to 7.1.4 and.. It now works :')

-
I'm trying to set up multiple MySQL Docker Containers. Problem is, I'm getting a "Connection refused" whenever I'm trying to connect to the MySQL Docker that I started after the first one. It feels like there's an issue with ports, but that shouldn't be the case, as I'm using a custom network, not Bridge. So here's a few details: I use a custom network (br0) for these Docker Containers The first MySQL container I start, works fine Second MySQL container cannot be connected, and results in "Connection Refused" I've tried to change the ports Both MySQL Containers have separate AppData folders for data I've tried to re-install the newer MySQL container several times. Always resulting in it working for a couple of seconds, and then returning to "Connection Refused" I'm connecting with the Container name, instead of direct IP (tried the IP way as well however) - This shows the Container IP correctly when trying to connect I've tried to change the permissions of the AppData folders, just to see if that makes any difference Using the latest MySQL (also tried with 5.7) UnRaid version is 7.1.2 I'm sure this is the wrong place to be asking about this, apologies for that, but as per usual with these things, I've been banging my head against the wall for the last 8 or so hours, and I'm about done ☠️ EDIT! For the three of you who might have the same issue.. This was fixed by updating UnRaid to 7.1.4 EDIT2: We're back at "Connection refused" after the weekend. Everything stated above still holds true :( EDIT3: (This seems to be the fix) ARP/MAC-level caching issue, and not a misconfiguration or database bug. To fix this, I added a fixed IP address to the broken container, giving it enough distance between the rest of the containers (instead of having xxx.xxx.x.5 it's now xxx.xxx.x.250)
-
EDIT: Seems that this is my issue. Or atleast part of it: https://github.com/RocketChat/Rocket.Chat/issues/29382 Original message below: Here to see if anyone else is experiencing similar oddities.. I seem to have a-lot of issues with files currently. I'm using File System as my storage type, which has been working just fine the past few months. However, now I'm getting "ENOENT: no such file or directory, stat '/app/uploads//647df273c68d8a46579c7e20'" Uploading files seems to be working fine. Issue comes when someone is trying to view the file, or delete the file. A bit of backstory It started from trying to create a new Team inside the Rocket.Chat, uploading an avatar to said Team, and then removing the avatar in order to replace it with something else. I noticed that I wasn't able to upload another avatar anymore, so I figured I'd just delete the Team, and start again. However, now the Team was "gone", but I wasn't able to create another one, since Rocket.Chat was determined that there was already a Team with the same name. I was unable to access it anywhere else, except in the settings menu, where I saw the Team. When trying to remove the Team there, it only resulted in more errors. Now however, everything related to files uploaded to Rocket.Chat, are behaving.. oddly. I haven't been able to really pinpoint the issue yet, but basically, only some of my files are loaded, in some client applications. This is very weird, as some files can be loaded on one Client app (such as Windows app, web-app, or mobile app) but for example a file that was uploaded through Android app, was only being displayed on the Web version. I've recently updated our Rocket.Chat to 6.2, which could be the culprit. But very un-sure. I've now been googling and banging my head against the wall for half of today, and I haven't really been finding anything. If anyone's interested, here's the whole error from trying to delete a file:
-
Just dropping a comment here, thank you! I've had plenty of issues with the VM's not wanting to restart properly unless I restart the entire server. Symptoms (for whoever is currently googling them and pulling their hair) are that, once the VM is restarted (or shut down, and then booting it up, for example when trying to update Windows), the first CPU that's allocated to the VM is stuck at 100%, and there's no signal through a monitor, and I was also unable to ping the VM.
-
Thank you so much! You just saved my hair, and my weekend! I'm not quite sure what happened here, as our backup server went through the same update just a week ago, and FileBrowser seemed to work just fine there. Whatever the case may be, chown seemed to be the answer here. Thank you for the quick answer!
-
After updating my UnRaid server from 6.9.2 to 6.11.0, the FileBrowser docker seems to have stopped working. The issue is that FileBrowser cannot access the database file: To confirm this, I changed the path to the database.db file from the container settings, which resulted in a new database file to be created, and the FileBrowser docker to be fully functional again. Though, without any of my settings and user data etc. Is there a way to grant permission to the FileBrowser to it's original database.db file? Worst case scenario, I can always manually set up the docker again, but that's a bit of a pain in the butt.
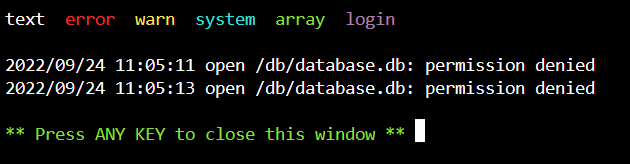
-
Just dropping a message here, in case someone needs to see it. I recently lost access to FileBrowser through the net. This was because of an expired SSL certificate. I wasn't able to renew the certificate within Nginx Proxy Manager either. To fix this, I changed the scheme within Nginx Proxy Manager to HTTP instead of HTTPS (which previously worked fine, for whatever reason) Maybe this'll save a few hours of hair pulling from someone
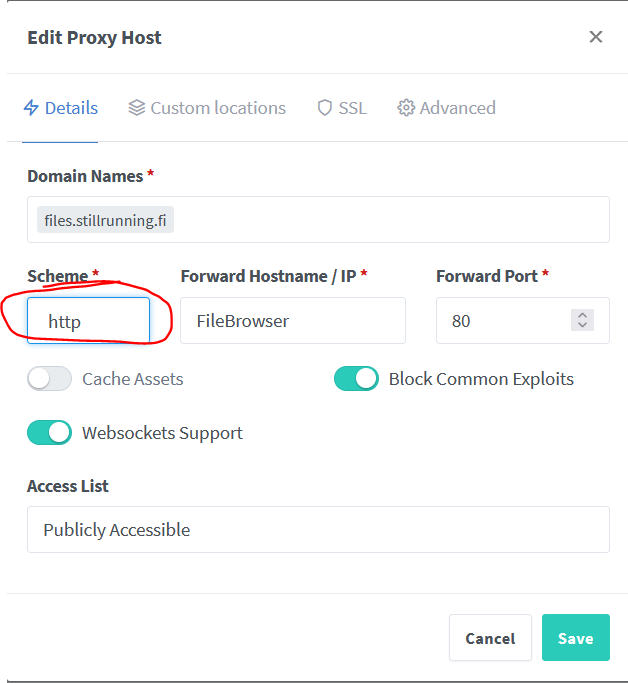
-
Opening the container's ip:port on Firefox doesn't show https on the front of the address (which it does for containers like UniFi), and really, from the testings I've done now, it's probably safe to say that FileBrowser uses HTTP. As for the nonsense, good to know! Definitely a possibility. However, access to my FileBrowser was disabled due to expired certificate? It makes sense, that the Nginx wasn't able to renew the certificate, because it couldn't access the FileBrowser container, but such an update _should've_ disabled the access to FileBrowser (through the net) all together? 🤔 Just tested this before I read your message. For whatever reason, renewing the certificate seemed to work just fine? Port 80 isn't disabled all together btw, what I meant was that I disabled the port-forward rule for port 80, as that was previously pointing to FileBrowser. From really quick testing, everything _seems_ to be working just fine right now. Seems that all of this was simply caused by the wrong protocol. 🥴
-
Edit 3: I've now tried to change the protocol to HTTP instead of HTTPS within Nginx, as I'm not really sure what protocol FileBrowser want's to use. Turns out, this seems to work from quick on/off testing. I'm a bit confused as to why HTTPS worked just fine with the last Nginx container I had, but not here? Going to the certificates tab within Nginx, and testing the reachability of the server seems to still give me the same error as before. So I'm guessing renewing the certificates will still be an issue. Edit 4: Disabling the port-forward rule for port 80 within my router seems to still work. Doing this however, does give me a different result in reachability test, which is now stating that there is no server.

-
Rightyo! Let's see.. 4.) Does NPM reach your target container? Nope. Nginx container is in br0, and wasn't able to connect to FileBrowser, since that was in Bridge mode. Changing FileBrowser into br0 as well, allows Nginx to connect to it succesfully. I've then changed the port forward rule to reflect this change, which seems to work fine. However, the situation is still very much the same: ✔️ http://[my-public-ip] (Skipping Nginx entirely) ✔️[FileBrowser_ip]:[FileBrowser_port] (Skipping Nginx entirely) ✔️Connection between Nginx and FileBrowser (with br0 network) ✔️http:// domain . com ❌https:// domain . com (results in bad gateway) ❌Server reachability test (Within Nginx) I've only now jumped to the official docker image of the Nginx Proxy Manager, previously, I was rocking the jlesage's docker image, which has server me well up until the issue yesterday with renewing certificates. It was also using Bridge-network mode. I read somewhere about potential issues with that particular docker image, and I figured I'd try this one out, just in case 🤷♂️ I feel like I'm just missing something obvious here.
-
Here's what I've got: However, I'm not exactly in the same spot anymore, as I was with the previous message. I got the certificate to renew itself by changing the port-forward rules, so that from port 80, instead of it being directed to FileBrowser, it was instead directed at Nginx docker. This, however, created a "Bad gateway" error, which I'm now struggling with. I've since changed the port forward rules back to what they were, so port 80 is now directed to FileBrowser again. But the result is the same. I'm also getting the same result with the reachability test. Thank you for the quick response! Appreciate it

-
Hey there, I've set up an Nginx proxy to an FileBrowser docker (and previously NextCloud) about a year ago, and so far everything has been working like a dream. Until yesterday >.< Not sure what happened, and when, but Nginx wasn't able to auto-renew the SSL certificate for my domain. I only noticed this yesterday, when I wasn't able to connect to the FileBrowser from the net anymore. I've tried to "manually" (as in, from the Nginx GUI) renew the certificate, but it keeps failing. On certain browsers (like Samsung's own web app, which doesn't seem to give two hoots about secure connections) I can connect to the FileBrowser docker just fine. I also created a new domain, and new Nginx proxy host to my FileBrowser docker, without the SSL certificates, just to test if the connection is good. It is. This is what I'm getting from the Docker log (inside of UnRaid) when I try to renew the certificate: Internal Error Error: Command failed: certbot certonly --config "/etc/letsencrypt.ini" --cert-name "npm-6" --agree-tos --authenticator webroot --email "[EMAIL HERE]" --preferred-challenges "dns,http" --domains "[EMAIL HERE]" Saving debug log to /var/log/letsencrypt/letsencrypt.log Some challenges have failed. Ask for help or search for solutions at https://community.letsencrypt.org. See the logfile /var/log/letsencrypt/letsencrypt.log or re-run Certbot with -v for more details. at ChildProcess.exithandler (node:child_process:397:12) at ChildProcess.emit (node:events:390:28) at maybeClose (node:internal/child_process:1064:16) at Process.ChildProcess._handle.onexit (node:internal/child_process:301:5) The external log files I can't seem to find anywhere 🤔 Trying to test the server reachability, I get: Any help would be appreciated!
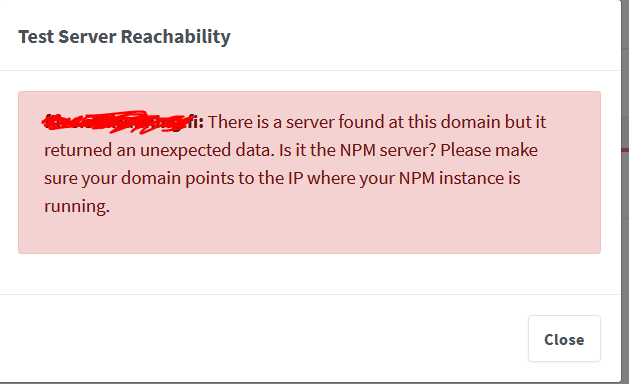
-
I got the same issue, and asked for help quite a while ago. Long story short, I decided to move to a docker called "FileBrowser" It was rather easy to setup, with a little help from a chinese video, and it's been working flawlessly ever since I set it up! As an added bonus, downloading files bigger than 1gb is actually possible straight out of the box with FileBrowser (I never got that to work with NextCloud)
-
This seems to have done the trick for me, thanks!
-
I don't know what the script is though, but probably shouldn't be too hard to create one on your own 🤷♂️
-
Hah, that would actually be good enough for our use, as 95% of the time we're using the files through SMB, and only 5% (whenever someone is working from home, and they're creating new folders) is used with FileBrowser. Mind sharing the script you did?
-
Did you find a way to get this working?
-
Either that, or he's just not too concerned about a free piece of software he created a long time ago I tried the "refresh" button just now, and unfortunately, no dice First, I ran the job through user-scripts, and opened the "manage backups" button, to see if the issue was still there (just in case) It was, so now I pressed the "refresh" button. That didn't work, and the backup wasn't updated. Then, I tried to run the cron-job again, and now, I tried to click on the "refresh" before opening the "manage backups" (since this is how it works with changing the profiles as well) and nothing. Just to check I wasn't crazy, I tried it my way, running the cron-job, and then switching between two profiles, and checking the "manage backups", and it worked just fine.
-
It does sound like it, since it would refresh the profiles 🤔 Would there be a command that could be ran after the profile, to refresh the profiles automatically? 🤔
-
I don't have the answer for your issue, but I'm using an app called "AutoSync" on our household phones. Cost's like 7eur to get the license to use it with an SMB share, and you can set it to sync automatically any folders you want when you're connected to a specific wifi. Has been working nicely for our needs atleast.
-
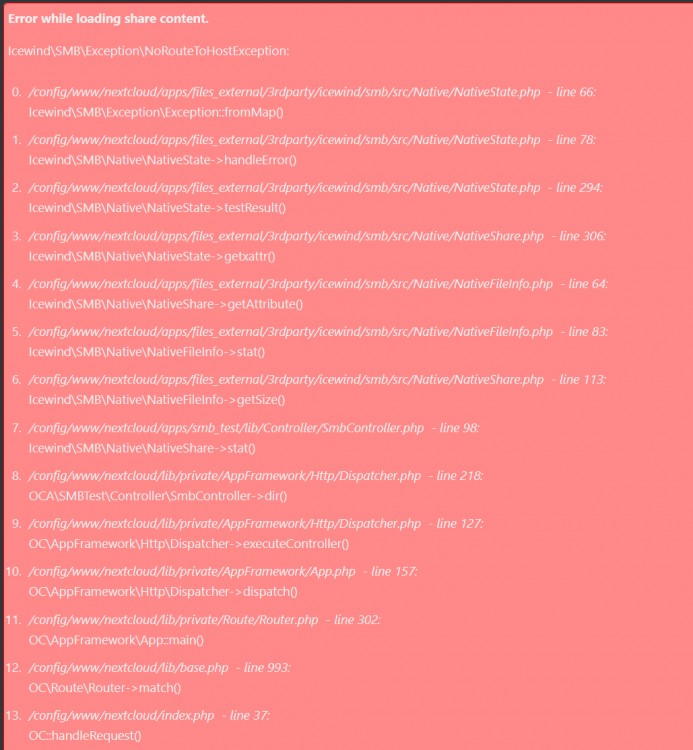
(Old issue, before updating) EDIT: (Internal server error, fixed in the next edit) EDIT2: (Fixing the internal server error, and back to square one) EDIT3: NextCloud is amazing for what it's trying to achieve, when it works. But it has just given me way too many headaches, and it's pretty much overkill for what I want to do with it (accessing files through the internet) that I've now decided to move to "FileBrowser" docker instead. Setting that up took me 10 minutes without really knowing what to do, and it's been working nicely (knock on wood), and even issues that we previously had (not being able to download files over 1gb) are now gone. Good luck all of you UnRaider's, who're battling with NextCloud!
-
Right, in that case, I could just have a restart every day through the user scripts, after the backup work is done :thinking: Thanks!











